













Zuerst werden wir sehen, was Redis ist und wie es verwendet wird, sowie warum es für moderne komplexe Mikroservice-Anwendungen geeignet ist. Wir werden darüber sprechen, wie Redis durch seine Module das Speichern mehrerer Datenformate für verschiedene Zwecke unterstützt. Als nächstes werden wir sehen, wie Redis als In-Memory-Datenbank Daten persistieren und sich von Datenverlust erholen kann. Wir werden auch darüber sprechen, wie Redis die Speicherkosten durch die Verwendung von Redis on Flash optimiert.
Dann werden wir sehr interessante Anwendungsfälle zum Skalieren von Redis und zur Replikation über mehrere geografische Regionen hinweg sehen. Schließlich, da eine der beliebtesten Plattformen für die Ausführung von Mikroservices Kubernetes ist und da das Ausführen von zustandsbehafteten Anwendungen in Kubernetes etwas herausfordernd ist, werden wir sehen, wie Sie Redis einfach auf Kubernetes ausführen können.
Was ist Redis?
Redis, was tatsächlich für Remote Dictionary Server steht, ist eine In-Memory-Datenbank. Viele Menschen haben es als Cache auf anderen Datenbanken verwendet, um die Anwendungsleistung zu verbessern. Was jedoch viele Menschen nicht wissen, ist, dass Redis eine vollwertige primäre Datenbank ist, die verwendet werden kann, um mehrere Datenformate für komplexe Anwendungen zu speichern und zu persistieren.
Beispiel für eine komplexe Social-Media-Anwendung
Lassen Sie uns einen gängigen Aufbau für eine Microservices-Anwendung betrachten. Angenommen, wir haben eine komplexe Social-Media-Anwendung mit Millionen von Nutzern. Und nehmen wir an, unsere Microservices-Anwendung verwendet eine relationale Datenbank wie MySQL zur Speicherung der Daten. Darüber hinaus haben wir aufgrund der täglichen Erfassung von riesigen Datenmengen eine Elasticsearch-Datenbank für schnelles Filtern und Suchen der Daten.
Nun sind alle Nutzer miteinander verbunden, daher benötigen wir eine Graphdatenbank, um diese Verbindungen darzustellen. Außerdem hat unsere Anwendung eine Menge Medieninhalte, die die Nutzer täglich miteinander teilen, und dafür haben wir eine Dokumentdatenbank. Schließlich haben wir zur Verbesserung der Anwendungsleistung einen Caching-Dienst, der Daten aus anderen Datenbanken zwischenspeichert und schneller zugänglich macht.
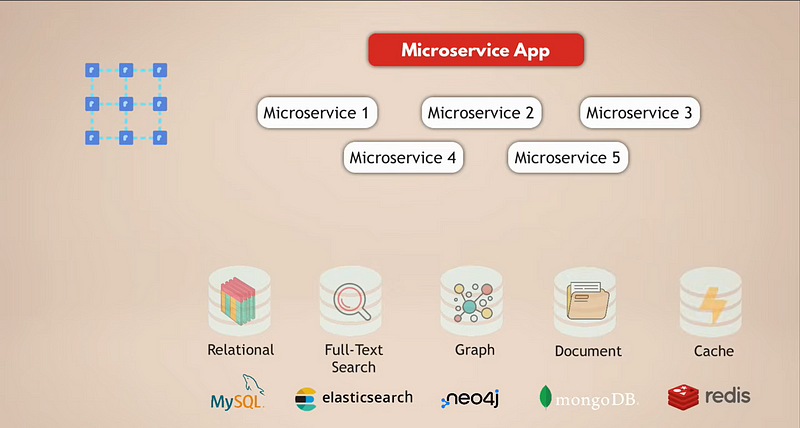
Nun ist offensichtlich, dass dies ein ziemlich komplexer Aufbau ist. Lassen Sie uns die Herausforderungen dieses Setups betrachten:
1. Bereitstellung und Wartung
All diese Datendienste müssen bereitgestellt, betrieben und gewartet werden. Das bedeutet, Ihr Team muss über Kenntnisse verfügen, wie man all diese Datendienste betreibt.
2. Skalierung und Infrastrukturanforderungen
Für hohe Verfügbarkeit und bessere Leistung möchten Sie Ihre Dienste skalieren. Jeder dieser Datendienste skaliert unterschiedlich und hat unterschiedliche Infrastrukturanforderungen, was eine zusätzliche Herausforderung darstellen kann. Insgesamt erhöht die Verwendung mehrerer Datendienste für Ihre Anwendung den Aufwand für die Wartung Ihres gesamten Anwendungssetups.
3. Cloud-Kosten
Natürlich können Sie als einfachere Alternative dazu, die Dienste selbst auszuführen und zu verwalten, die verwalteten Datendienste der Cloud-Anbieter nutzen. Aber das könnte sehr teuer sein, denn auf Cloud-Plattformen zahlen Sie für jeden verwalteten Datendienst separat.
4. Entwicklungskomplexität
5. Höhere Latenz
Warum Redis diese Komplexität vereinfacht
Im Vergleich zu einer multi-modalen Datenbank wie Redis lösen Sie die meisten dieser Herausforderungen:
- Einzeldatendienst. Sie führen und pflegen nur einen Datendienst. Daher muss Ihre Anwendung auch nur mit einem einzelnen Datenspeicher kommunizieren, was bedeutet, dass es nur eine programmatische Schnittstelle für diesen Datendienst gibt.
- Verringerte Latenz. Die Latenz wird reduziert, indem Sie zu einem einzelnen Datendienst gehen und mehrere interne Netzwerk-Hops eliminieren.
- Mehrere Datentypen in einem. Ein einzelner Datenbanktyp wie Redis, der es Ihnen ermöglicht, verschiedene Datentypen zu speichern (d.h. mehrere Datenbanktypen in einer) sowie als Cache zu fungieren, löst solche Herausforderungen.
Wie Redis mehrere Datenformate unterstützt
Also, schauen wir uns an, wie Redis tatsächlich funktioniert. Zunächst einmal, wie unterstützt Redis mehrere Datenformate in einer einzigen Datenbank?
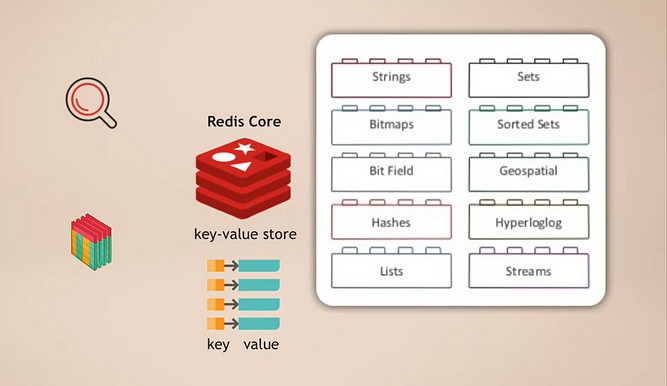
Redis-Kern und Module
Die Arbeitsweise besteht darin, dass du Redis-Kern hast, der ein Schlüssel-Wert-Speicher ist und der bereits das Speichern verschiedener Datentypen unterstützt. Anschließend kannst du diesen Kern mit sogenannten Modulen für verschiedene Datentypen erweitern, die deine Anwendung für verschiedene Zwecke benötigt. Zum Beispiel:
- RedisSearch für Suchfunktionalität (ähnlich wie Elasticsearch)
- RedisGraph für die Speicherung von Graphdaten
Ein großartiger Aspekt dabei ist, dass es modular ist. Diese verschiedenen Arten von Datenbankfunktionalitäten sind nicht fest in einer Datenbank integriert, wie es bei vielen anderen multimodalen Datenbanken der Fall ist. Stattdessen kannst du genau auswählen, welche Datenbankdienstfunktionalität du für deine Anwendung benötigst, und dann einfach dieses Modul hinzufügen.
Eingebautes Caching
Und natürlich, wenn du Redis als primäre Datenbank verwendest, benötigst du keinen zusätzlichen Cache, denn das ist automatisch mit Redis verfügbar. Das bedeutet, erneut weniger Komplexität in deiner Anwendung, da du die Logik zum Verwalten, Befüllen und Ungültigmachen des Caches nicht implementieren musst.
Hohe Leistung und schnellere Tests
Schließlich ist Redis als In-Memory-Datenbank sehr schnell und leistungsstark, was die Anwendung selbst natürlich schneller macht. Darüber hinaus beschleunigt es auch das Ausführen der Anwendungstests erheblich, da Redis im Gegensatz zu anderen Datenbanken kein Schema benötigt. Es muss also keine Zeit für die Initialisierung der Datenbank, den Aufbau des Schemas usw. aufgewendet werden, bevor die Tests ausgeführt werden können. Sie können jedes Mal mit einer leeren Redis-Datenbank beginnen und die Daten für Tests generieren, wie Sie es benötigen. Schnelle Tests können Ihre Entwicklungseffizienz wirklich steigern.
Datenpersistenz in Redis
Wir haben verstanden, wie Redis funktioniert und all seine Vorteile. Aber an diesem Punkt fragen Sie sich vielleicht: Wie kann eine In-Memory-Datenbank Daten persistieren? Denn wenn der Redis-Prozess oder der Server, auf dem Redis ausgeführt wird, abstürzt, sind alle Daten im Speicher verloren, oder? Und wenn ich die Daten verliere, wie kann ich sie wiederherstellen? Also, wie kann ich sicher sein, dass meine Daten geschützt sind?
Der einfachste Weg, Datensicherungen zu haben, besteht darin, Redis zu replizieren. Wenn also die Redis-Masterinstanz ausfällt, werden die Replikate weiterhin laufen und alle Daten haben. Wenn Sie ein repliziertes Redis haben, werden die Replikate die Daten haben. Natürlich gehen jedoch alle Daten verloren, wenn alle Redis-Instanzen ausfallen, da kein Replikat mehr vorhanden ist.
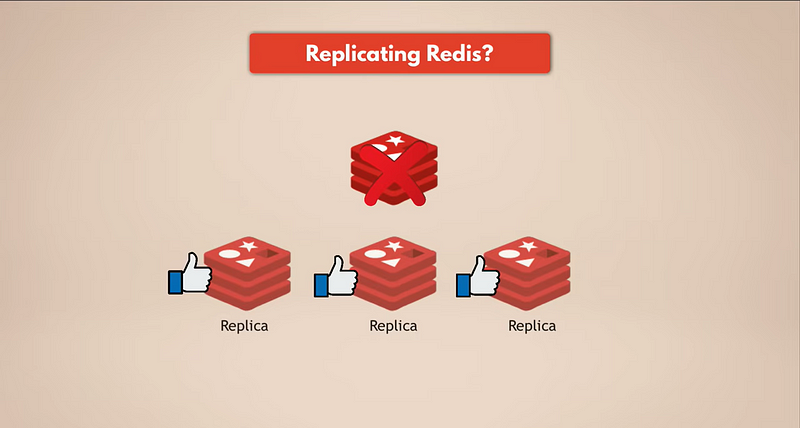
Wir brauchen echte Persistenz.
Schnappschuss (RDB)
Redis verfügt über mehrere Mechanismen zur Persistenz von Daten und zum Schutz der Daten. Der erste ist Snapshots, die basierend auf Zeit, Anzahl der Anfragen usw. konfiguriert werden können. Snapshots Ihrer Daten werden auf einer Festplatte gespeichert, die Sie verwenden können, um Ihre Daten wiederherzustellen, wenn die gesamte Redis-Datenbank verloren geht. Beachten Sie jedoch, dass Sie die letzten Minuten der Daten verlieren werden, da Sie in der Regel alle fünf Minuten oder jede Stunde Snapshots erstellen, abhängig von Ihren Bedürfnissen.
AOF (Append Only File)
Als Alternative verwendet Redis etwas namens AOF, was für Append Only File steht. In diesem Fall wird jede Änderung kontinuierlich auf die Festplatte zur Persistenz gespeichert. Beim Neustart von Redis oder nach einem Ausfall spielt Redis die Append Only File-Protokolle ab, um den Zustand wiederherzustellen. AOF ist also robuster, kann aber langsamer sein als das Erstellen von Snapshots.
Kombination von Snapshots und AOF
Und natürlich können Sie auch eine Kombination aus AOF und Snapshots verwenden, wobei die append-only-Datei kontinuierlich Daten aus dem Speicher auf die Festplatte schreibt und regelmäßige Snapshots dazwischen erstellt, um den Datenzustand zu speichern, falls eine Wiederherstellung erforderlich ist. Das bedeutet, dass selbst wenn die Redis-Datenbank selbst oder die Server, die zugrunde liegende Infrastruktur, auf der Redis läuft, versagen, sind alle Ihre Daten sicher und Sie können problemlos eine neue Redis-Datenbank mit allen Daten erstellen und neu starten.
Wo befindet sich dieser persistente Speicher?
Eine sehr interessante Frage ist, wo befindet sich dieser persistente Speicher? Also, wo befindet sich die Festplatte, die Ihre Snapshots und die Protokolle der append-only Datei enthält? Befinden sie sich auf denselben Servern, auf denen Redis läuft?
Diese Frage führt uns tatsächlich zum Trend oder zur bewährten Praxis der Datenspeicherung in Cloud-Umgebungen, nämlich dass es immer besser ist, die Server, auf denen Ihre Anwendungen und Datendienste ausgeführt werden, von dem dauerhaften Speicher zu trennen, der Ihre Daten speichert.
Mit einem konkreten Beispiel: Wenn Ihre Anwendungen und Dienste in der Cloud auf einer AWS EC2-Instanz ausgeführt werden, sollten Sie EBS oder Elastic Block Storage verwenden, um Ihre Daten zu speichern, anstatt sie auf der Festplatte der EC2-Instanz zu speichern. Denn wenn diese EC2-Instanz ausfällt, haben Sie keinen Zugriff auf ihren Speicher, sei es RAM oder Festplattenspeicher oder ähnliches. Wenn Sie also Persistenz und Langlebigkeit für Ihre Daten wünschen, müssen Sie Ihre Daten außerhalb der Instanzen auf einem externen Netzwerkspeicher platzieren.
Als Ergebnis, durch die Trennung dieser beiden, wenn die Serverinstanz ausfällt oder wenn alle Instanzen ausfallen, haben Sie dennoch die Festplatte und alle Daten darauf unberührt. Sie können einfach andere Instanzen hochfahren und die Daten aus dem EBS übernehmen, und das war’s. Dies erleichtert das Management Ihrer Infrastruktur erheblich, da jeder Server gleich ist; Sie haben keine speziellen Server mit speziellen Daten oder Dateien darauf. Es ist also egal, wenn Sie Ihre gesamte Infrastruktur verlieren, denn Sie können einfach eine neue erstellen und die Daten aus einem separaten Speicher abrufen, und schon können Sie wieder loslegen.
Zurück zum Redis-Beispiel: Der Redis-Dienst wird auf den Servern ausgeführt und nutzt den Server-RAM, um die Daten zu speichern, während die append-only Dateilogs und Snapshots auf einer Festplatte außerhalb dieser Server gespeichert werden, um Ihre Daten langlebiger zu machen.
Kostenoptimierung mit Redis on Flash
Jetzt wissen wir, dass Sie Daten mit Redis zur Haltbarkeit und Wiederherstellung speichern können, während Sie RAM oder Speicher für eine großartige Leistung und Geschwindigkeit nutzen. Die Frage, die Sie hier haben könnten, lautet: Ist die Speicherung von Daten im Speicher teuer? Denn Sie bräuchten mehr Server im Vergleich zu einer Datenbank, die Daten einfach auf der Festplatte speichert, da der Speicher begrenzt ist. Es gibt einen Kompromiss zwischen Kosten und Leistung.
Nun, Redis hat tatsächlich eine Methode zur Optimierung, die einen Dienst namens Redis on Flash verwendet, der Teil von Redis Enterprise ist.
Wie Redis on Flash funktioniert
Es ist eigentlich ein ziemlich einfaches Konzept: Redis on Flash erweitert den RAM auf das Flash-Laufwerk oder SSD, auf dem häufig verwendete Werte im RAM gespeichert werden und die selten verwendeten auf der SSD. Für Redis ist es einfach mehr RAM auf dem Server. Das bedeutet, dass Redis mehr von der zugrunde liegenden Infrastruktur oder den zugrunde liegenden Serverressourcen nutzen kann, indem es sowohl RAM als auch SSD-Laufwerk verwendet, um die Daten zu speichern, die Speicherkapazität auf jedem Server erhöht und Ihnen somit Infrastrukturkosten spart.
Skalierung von Redis: Replikation und Sharding
Wir haben über die Datenspeicherung für die Redis-Datenbank gesprochen und wie alles funktioniert, einschließlich bewährter Verfahren. Ein weiteres sehr interessantes Thema ist nun, wie wir eine Redis-Datenbank skalieren können?
Replikation und hohe Verfügbarkeit
Angenommen, meine Redis-Instanz läuft aus dem Speicher, sodass die Daten zu groß werden, um im Speicher zu halten, oder Redis wird zum Engpass und kann keine weiteren Anfragen mehr verarbeiten. In einem solchen Fall, wie erhöhe ich die Kapazität und die Speichergröße meiner Redis-Datenbank?
Wir haben mehrere Optionen dafür. Erstens unterstützt Redis Clustering, was bedeutet, dass Sie eine Primäre oder Master-Redis-Instanz haben können, die zum Lesen und Schreiben von Daten verwendet werden kann, und Sie können mehrere Replikate dieser primären Instanz für das Lesen der Daten haben. Auf diese Weise können Sie Redis skalieren, um mehr Anfragen zu bewältigen und zusätzlich die hohe Verfügbarkeit Ihrer Datenbank zu erhöhen. Wenn der Master ausfällt, kann eines der Replikate übernehmen, und Ihre Redis-Datenbank kann im Grunde weiterhin funktionieren, ohne Probleme zu haben.
Diese Replikate werden alle Kopien der Daten der primären Instanz halten. Je mehr Replikate Sie haben, desto mehr Speicherplatz benötigen Sie. Und ein Server hat möglicherweise nicht genügend Speicherplatz für alle Ihre Replikate. Außerdem, wenn Sie alle Replikate auf einem Server haben und dieser Server ausfällt, ist Ihre gesamte Redis-Datenbank weg, und Sie haben Ausfallzeiten. Stattdessen möchten Sie diese Replikate auf mehrere Knoten oder Server verteilen. Zum Beispiel wird Ihre Master-Instanz auf einem Knoten und zwei Replikate auf den anderen beiden Knoten sein.
Sharding für größere Datensätze
Nun, das scheint gut genug zu sein, aber was ist, wenn Ihr Datensatz zu groß wird, um auf einem einzelnen Server in den Speicher zu passen? Außerdem haben wir die Lesevorgänge in der Datenbank skaliert, sodass alle Anfragen im Grunde genommen nur die Daten abfragen, aber unsere Master-Instanz ist immer noch allein und muss immer noch alle Schreibvorgänge bearbeiten. Also, was ist die Lösung hier?

Dafür verwenden wir das Konzept des Sharding, das ein allgemeines Konzept in Datenbanken ist und das auch von Redis unterstützt wird. Sharding bedeutet im Wesentlichen, dass Sie Ihren kompletten Datensatz nehmen und ihn in kleinere Teile oder Teilmengen von Daten aufteilen, wobei jeder Shard für seine eigene Teilmenge von Daten verantwortlich ist.
Das bedeutet, anstatt eine Master-Instanz zu haben, die alle Schreibvorgänge für den kompletten Datensatz verarbeitet, können Sie ihn in, sagen wir, vier Shards aufteilen, von denen jeder für Lese- und Schreibvorgänge einer Teilmenge der Daten verantwortlich ist. Jeder Shard benötigt auch weniger Speicherkapazität, da er nur ein Viertel der Daten hat. Das bedeutet, dass Sie Shards auf kleineren Knoten verteilen und ausführen können und somit Ihr Cluster horizontal skalieren können. Und natürlich, wenn Ihr Datensatz wächst und Sie noch mehr Ressourcen benötigen, können Sie Ihre Redis-Datenbank neu sharden, was im Wesentlichen bedeutet, dass Sie Ihre Daten in noch kleinere Teile aufteilen und mehr Shards erstellen.

Das Vorhandensein mehrerer Knoten, die mehrere Replikate von Redis ausführen, die alle ge sharded sind, gibt Ihnen eine sehr leistungsfähige, hochverfügbare Redis-Datenbank, die viel mehr Anfragen verarbeiten kann, ohne Engpässe zu erzeugen.
Ich muss hier anmerken, dass dieses Setup großartig ist, aber Sie müssten es selbst verwalten, das Scaling durchführen, Knoten hinzufügen, Sharding und dann Resharding usw. Für einige Teams, die mehr auf Anwendungsentwicklung und Geschäftslogik fokussiert sind, anstatt Datenservices zu betreiben und zu warten, könnte dies viel unerwünschten Aufwand bedeuten. Als einfachere Alternative erhalten Sie in Redis Enterprise diese Art von Setup automatisch, da das Scaling, Sharding usw. alles für Sie verwaltet wird.
Globale Replikation mit Redis: Aktive-Aktive-Bereitstellung
Betrachten wir ein weiteres interessantes Szenario für Anwendungen, die noch höhere Verfügbarkeit und Leistung über mehrere geografische Standorte hinweg benötigen. Angenommen, wir haben diesen replizierten, gesharteten Redis-Datenbankcluster in einer Region, im Rechenzentrum von London, Europa. Aber wir haben die folgenden zwei Anwendungsfälle:
- Unsere Benutzer sind geografisch verteilt, sodass sie von überall auf der Welt auf die Anwendung zugreifen. Wir möchten unsere Anwendung und Daten-Services global verteilen, nahe an den Benutzern, um unseren Benutzern eine bessere Leistung zu bieten.
- Wenn das komplette Rechenzentrum in London, Europa, zum Beispiel ausfällt, möchten wir eine sofortige Umschaltung auf ein anderes Rechenzentrum, sodass der Redis-Dienst verfügbar bleibt. Mit anderen Worten möchten wir Repliken des gesamten Redis-Clusters in Rechenzentren an mehreren geografischen Standorten oder Regionen haben.
Mehrere Redis-Cluster über Regionen hinweg
Dies bedeutet, dass ein einzelnes Datum auf viele Cluster über mehrere Regionen verteilt repliziert werden sollte, wobei jeder Cluster vollständig in der Lage ist, Lese- und Schreibvorgänge zu akzeptieren. In diesem Fall hätten Sie mehrere Redis-Cluster, die in jeder Region als lokale Redis-Instanzen agieren, und die Daten würden über diese geografisch verteilten Cluster synchronisiert. Dies ist eine Funktion, die in Redis Enterprise verfügbar ist und aktive-aktive Bereitstellung genannt wird, da Sie mehrere aktive Datenbanken an verschiedenen Standorten haben.

Mit diesem Setup werden wir eine geringere Latenz für die Benutzer haben. Und selbst wenn die Redis-Datenbank in einer Region vollständig ausfällt, sind die anderen Regionen nicht betroffen. Wenn die Verbindung oder Synchronisierung zwischen den Regionen aufgrund eines Netzwerkproblems kurzzeitig unterbrochen wird, können die Redis-Cluster in diesen Regionen die Daten unabhängig aktualisieren, und sobald die Verbindung wiederhergestellt ist, können sie diese Änderungen erneut synchronisieren.
Konfliktlösung mit CRDTs
Nun, wenn man das hört, könnte die erste Frage, die einem in den Sinn kommt, lauten: Wie löst Redis die Änderungen in mehreren Regionen am selben Datensatz? Also, wenn sich dieselben Daten in mehreren Regionen ändern, wie stellt Redis sicher, dass Datenänderungen in keiner Region verloren gehen und die Daten korrekt synchronisiert werden, und wie gewährleistet es Datenkonsistenz?
Speziell verwendet Redis Enterprise ein Konzept namens CRDTs, was für konfliktfreie replizierte Datentypen steht, und dieses Konzept wird verwendet, um Konflikte automatisch auf Datenbankebene und ohne Datenverlust zu lösen. Also hat Redis selbst einen Mechanismus zum Zusammenführen der Änderungen, die am selben Datensatz aus mehreren Quellen vorgenommen wurden, sodass keine Datenänderungen verloren gehen und Konflikte ordnungsgemäß gelöst werden. Und da, wie Sie gelernt haben, Redis mehrere Datentypen unterstützt, verwendet jeder Datentyp seine eigenen Regeln zur Konfliktlösung, die für diesen spezifischen Datentyp am optimalsten sind.

Einfach ausgedrückt werden anstelle des einfachen Überschreibens der Änderungen einer Quelle und des Verwerfens aller anderen alle parallelen Änderungen beibehalten und intelligent gelöst. Auch hier wird dies automatisch für Sie mit dieser aktiven Geo-Replikationsfunktion durchgeführt, sodass Sie sich darüber keine Gedanken machen müssen.
Redis in Kubernetes ausführen
Und das letzte Thema, das ich mit Redis ansprechen möchte, ist das Ausführen von Redis in Kubernetes. Wie gesagt, Redis eignet sich hervorragend für komplexe Mikrodienste, die mehrere Datentypen unterstützen müssen und bei denen eine einfache Skalierung einer Datenbank ohne Sorgen um Datenkonsistenz erforderlich ist. Und wir wissen auch, dass der neue Standard für das Ausführen von Mikrodiensten die Kubernetes-Plattform ist. Das Ausführen von Redis in Kubernetes ist also ein sehr interessanter und häufiger Anwendungsfall. Wie funktioniert das also?

Open Source Redis auf Kubernetes
Mit Open-Source Redis können Sie repliziertes Redis als Helm-Chart oder Kubernetes-Manifestdateien bereitstellen und im Grunde genommen unter Verwendung der bereits besprochenen Replikations- und Skalierungsregeln ein hochverfügbares Redis-Datenbanksystem einrichten und betreiben. Der einzige Unterschied besteht darin, dass die Hosts, auf denen Redis ausgeführt wird, Kubernetes-Pods anstelle von z. B. EC2-Instanzen oder anderen physischen oder virtuellen Servern sein werden. Aber dieselben Konzepte für das Sharding, Replizieren und Skalieren gelten auch hier, wenn Sie ein Redis-Cluster in Kubernetes ausführen möchten, und im Grunde genommen müssten Sie dieses Setup selbst verwalten.
Redis Enterprise Operator
Jedoch, wie bereits erwähnt, möchten viele Teams nicht den Aufwand betreiben, diese Drittanbieterdienste zu pflegen, da sie ihre Zeit und Ressourcen lieber in die Anwendungsentwicklung oder andere Aufgaben investieren würden. Daher ist es auch wichtig, eine einfachere Alternative zu haben. Redis Enterprise verfügt über einen verwalteten Redis-Cluster, den Sie als Kubernetes-Operator bereitstellen können.

Wenn Sie nicht wissen, was Operatoren sind, ist ein Operator in Kubernetes im Grunde ein Konzept, bei dem Sie alle Ressourcen bündeln können, die benötigt werden, um eine bestimmte Anwendung oder einen bestimmten Dienst zu betreiben, sodass Sie es nicht selbst verwalten müssen. Anstatt dass ein Mensch eine Datenbank betreibt, haben Sie im Grunde genommen all diese Logik in automatisierter Form, um eine Datenbank für Sie zu betreiben. Viele Datenbanken haben Operatoren für Kubernetes, und jeder solche Operator hat natürlich seine eigene Logik, basierend darauf, wer sie geschrieben hat und wie sie geschrieben wurden.
Der Redis Enterprise on Kubernetes Operator automatisiert speziell die Bereitstellung und Konfiguration der gesamten Redis-Datenbank in Ihrem Kubernetes-Cluster. Er kümmert sich auch um das Skalieren, das Erstellen von Backups und das Wiederherstellen des Redis-Clusters bei Bedarf usw. Er übernimmt also die gesamte Betriebsführung des Redis-Clusters innerhalb des Kubernetes-Clusters.
Zusammenfassung
Ich hoffe, Sie haben in diesem Blog viel gelernt und dass ich viele Ihrer Fragen beantworten konnte. Wenn Sie mehr über ähnliche Technologien und Konzepte erfahren möchten, dann achten Sie darauf, mir zu folgen, da ich regelmäßig Blogs über KI, DevOps und Cloud-Technologien schreibe.
Schreiben Sie auch unten einen Kommentar, wenn Sie Fragen zu Redis oder Vorschläge zu neuen Themen haben. Und damit, vielen Dank fürs Lesen und bis zum nächsten Blog.
Lass uns auf LinkedIn vernetzen!
Source:
https://dzone.com/articles/redis-as-a-primary-database-for-complex-applications