













Eerst zullen we bekijken wat Redis is en hoe het wordt gebruikt, evenals waarom het geschikt is voor moderne complexe microservice-toepassingen. We zullen het hebben over hoe Redis het opslaan van meerdere gegevensformaten voor verschillende doeleinden ondersteunt via zijn modules. Vervolgens zullen we zien hoe Redis, als een in-memory database, gegevens kan persistent maken en herstellen van gegevensverlies. We zullen ook bespreken hoe Redis de kosten van geheugenopslag optimaliseert met behulp van Redis op Flash.
Daarna zullen we zeer interessante gebruiksgevallen bekijken van het schalen van Redis en het repliceren ervan over meerdere geografische regio’s. Ten slotte, aangezien een van de populairste platforms voor het draaien van microservices Kubernetes is, en omdat het draaien van stateful toepassingen in Kubernetes een beetje uitdagend is, zullen we zien hoe je Redis eenvoudig op Kubernetes kunt draaien.
Wat is Redis?
Redis, dat eigenlijk staat voor Remote Dictionary Server, is een in-memory database. Veel mensen hebben het gebruikt als een cache bovenop andere databases om de prestaties van de toepassing te verbeteren. Wat veel mensen echter niet weten, is dat Redis een volwaardige primaire database is die kan worden gebruikt om meerdere gegevensformaten voor complexe toepassingen op te slaan en persistent te maken.
Voorbeeld van een complexe sociale media-toepassing
Laten we kijken naar een veelvoorkomende opzet voor een microservices-applicatie. Stel dat we een complexe sociale media-applicatie hebben met miljoenen gebruikers. En laten we zeggen dat onze microservices-applicatie een relationele database zoals MySQL gebruikt om de gegevens op te slaan. Daarnaast, omdat we dagelijks enorme hoeveelheden gegevens verzamelen, hebben we een Elasticsearch-database voor snelle filtering en het doorzoeken van de gegevens.
Nu zijn de gebruikers allemaal met elkaar verbonden, dus we hebben een grafiekdatabase nodig om deze verbindingen weer te geven. Bovendien heeft onze applicatie veel media-inhoud die gebruikers dagelijks met elkaar delen, en daarvoor hebben we een documentdatabase. Tot slot, voor een betere prestatie van de applicatie, hebben we een cache-service die gegevens uit andere databases opslaat en sneller toegankelijk maakt.
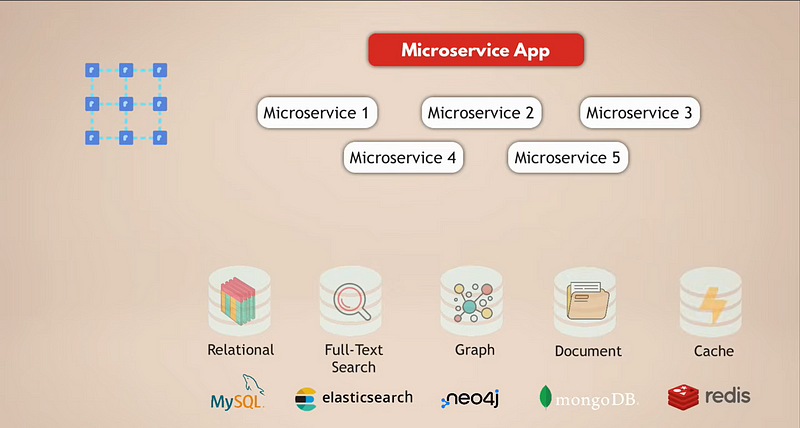
Het is nu duidelijk dat dit een vrij complexe opzet is. Laten we eens kijken naar de uitdagingen van deze opzet:
1. Implementatie en Onderhoud
Al deze dataservices moeten worden geïmplementeerd, uitgevoerd en onderhouden. Dit betekent dat jouw team enige kennis moet hebben van hoe je al deze dataservices moet bedienen.
2. Schaalbaarheid en Infrastructuurvereisten
Voor hoge beschikbaarheid en betere prestaties wil je je services schalen. Elke van deze dataservices schaalt anders en heeft verschillende infrastructuurvereisten, wat een extra uitdaging kan zijn. Al met al verhoogt het gebruik van meerdere dataservices voor je applicatie de inspanning om je hele applicatieopzet te onderhouden.
3. Cloudkosten
Natuurlijk, als een gemakkelijkere alternatieve manier om de diensten zelf te draaien en te beheren, kun je de beheerde datadiensten van cloudproviders gebruiken. Maar dit kan erg duur zijn omdat je op cloudplatforms voor elke beheerde datadienst apart betaalt.
4. Ontwikkelingscomplexiteit
5. Hogere latentie
Waarom Redis deze complexiteit vereenvoudigt
In vergelijking met een multimodale database zoals Redis, los je de meeste van deze uitdagingen op:
- Enkele datadienst. Je draait en onderhoudt slechts één datadienst. Dus je applicatie hoeft ook maar met één datastorage te communiceren, wat betekent dat er maar één programmatische interface voor die datadienst is.
- Verminderde latentie. De latentie zal worden verminderd door naar één data-eindpunt te gaan en verschillende interne netwerk hops te elimineren.
- Meerdere datatypes in één. Het hebben van één database zoals Redis die je in staat stelt verschillende soorten data op te slaan (d.w.z. meerdere soorten databases in één) en ook als cache fungeertlost dergelijke uitdagingen op.
Hoe Redis meerdere dataformaten ondersteunt
Dus laten we eens kijken hoe Redis daadwerkelijk werkt. Ten eerste, hoe ondersteunt Redis meerdere dataformaten in één enkele database?
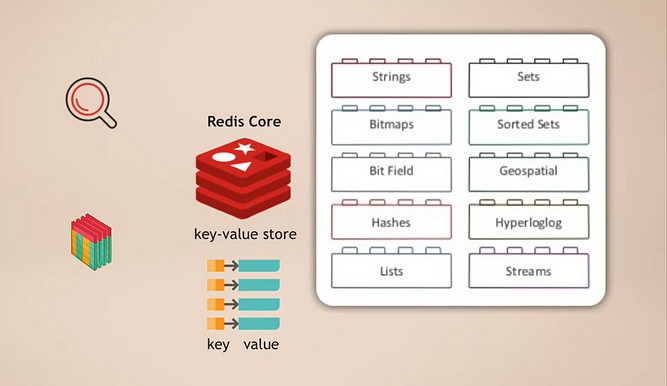
Redis Kern en Modules
De manier waarop het werkt is dat je Redis-core hebt, wat een key-value store is die al ondersteuning biedt voor het opslaan van meerdere soorten gegevens. Vervolgens kun je die kern uitbreiden met wat modules worden genoemd voor verschillende gegevenstypen die je applicatie nodig heeft voor verschillende doeleinden. Bijvoorbeeld:
- RedisSearch voor zoekfunctionaliteit (zoals Elasticsearch)
- RedisGraph voor het opslaan van grafiekgegevens
Een geweldige eigenschap hiervan is dat het modulair is. Deze verschillende soorten databasefunctionaliteiten zijn niet strak geïntegreerd in één database zoals bij veel andere multimodale databases, maar in plaats daarvan kun je precies kiezen welke gegevensservicefunctionaliteit je nodig hebt voor je applicatie en die module toevoegen.
Ingebouwde caching
En natuurlijk, wanneer je Redis als primaire database gebruikt, heb je geen extra cache nodig omdat je dat automatisch bij Redis hebt. Dat betekent opnieuw minder complexiteit in je applicatie omdat je de logica voor het beheren, vullen en ongeldig maken van de cache niet hoeft te implementeren.
Hoge prestaties en sneller testen
Uiteindelijk is Redis, als een in-memory database, super snel en performant, wat natuurlijk de applicatie zelf sneller maakt. Bovendien maakt het ook het uitvoeren van de applicatietests veel sneller, omdat Redis geen schema nodig heeft zoals andere databases. Het hoeft dus geen tijd te besteden aan het initialiseren van de database, het bouwen van het schema, enzovoort, voordat de tests worden uitgevoerd. Je kunt elke keer beginnen met een lege Redis-database en gegevens genereren voor tests wanneer je dat nodig hebt. Snelle tests kunnen echt je ontwikkelingsproductiviteit verhogen.
Gegevenspersistentie in Redis
We hebben begrepen hoe Redis werkt en al zijn voordelen. Maar op dit punt vraag je je misschien af: Hoe kan een in-memory database gegevens persistent maken? Want als het Redis-proces of de server waarop Redis draait uitvalt, zijn alle gegevens in het geheugen weg, toch? En als ik de gegevens verlies, hoe kan ik ze dan herstellen? Dus in wezen, hoe kan ik er zeker van zijn dat mijn gegevens veilig zijn?
De eenvoudigste manier om gegevensback-ups te hebben, is door Redis te repliceren. Dus, als de Redis-masterinstantie uitvalt, zullen de replica’s nog steeds draaien en alle gegevens hebben. Als je een gerepliceerde Redis hebt, zullen de replica’s de gegevens hebben. Maar natuurlijk, als alle Redis-instanties uitvallen, verlies je de gegevens omdat er geen replica meer over is.
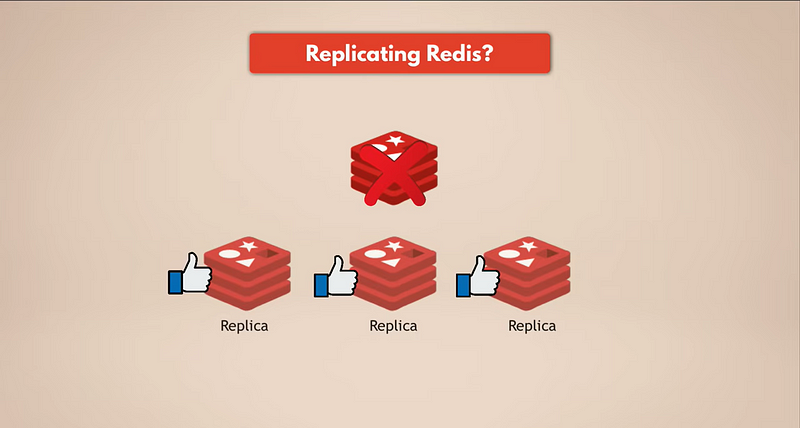
We hebben echte persistentie.
Snapshot (RDB)
Redis heeft meerdere mechanismen om gegevens te behouden en veilig te stellen. De eerste is momentopnamen, die je kunt configureren op basis van tijd, aantal verzoeken, enzovoort. Momentopnamen van je gegevens worden opgeslagen op een schijf, die je kunt gebruiken om je gegevens te herstellen als de hele Redis-database verdwenen is. Maar let op dat je de laatste minuten aan gegevens zult verliezen, omdat je meestal elke vijf minuten of elk uur een momentopname maakt, afhankelijk van je behoeften.
AOF (Append Only File)
Als alternatief gebruikt Redis iets dat AOF wordt genoemd, wat staat voor Append Only File. In dit geval wordt elke wijziging continu opgeslagen op de schijf voor persistentie. Bij het opnieuw starten van Redis of na een storing zal Redis de logs van het Append Only File opnieuw afspelen om de staat te herbouwen. Dus, AOF is duurzamer maar kan trager zijn dan momentopnamen.
Combinatie van Momentopnamen en AOF
En, natuurlijk, je kunt ook een combinatie van zowel AOF als momentopnamen gebruiken, waarbij het append-only bestand gegevens continu van het geheugen naar de schijf persisteert, plus je hebt regelmatige momentopnamen ertussen om de gegevensstaat op te slaan voor het geval je deze moet herstellen. Dit betekent dat zelfs als de Redis-database zelf of de servers, de onderliggende infrastructuur waarop Redis draait, allemaal falen, je nog steeds al je gegevens veilig hebt en je gemakkelijk een nieuwe Redis-database met alle gegevens kunt herstellen en opnieuw kunt starten.
Waar Is Deze Persistente Opslag?
Een zeer interessante vraag is, waar bevindt zich die persistente opslag? Dus waar is die schijf die je momentopnamen en de logbestanden van het append-only bestand bevat? Zijn ze op dezelfde servers waar Redis draait?
Deze vraag leidt ons eigenlijk naar de trend of de beste praktijk van gegevenspersistentie in cloudomgevingen, namelijk dat het altijd beter is om de servers die uw applicatie en gegevensservices uitvoeren te scheiden van de persistente opslag die uw gegevens opslaat.
Met een specifiek voorbeeld: Als uw applicaties en services in de cloud draaien op bijvoorbeeld een AWS EC2-instantie, moet u EBS of Elastic Block Storage gebruiken om uw gegevens te behouden in plaats van ze op de harde schijf van de EC2-instantie op te slaan. Want als die EC2-instantie uitvalt, heeft u geen toegang tot een van de opslag, of het nu RAM is of schijfopslag of wat dan ook. Dus, als u persistentie en duurzaamheid voor uw gegevens wilt, moet u uw gegevens buiten de instanties opslaan op een externe netwerkopslag.
Als gevolg hiervan, door deze twee van elkaar te scheiden, als de serverinstantie uitvalt of als alle instanties uitvallen, heeft u nog steeds de schijf en alle gegevens erop onaangetast. U start gewoon andere instanties op en haalt de gegevens uit de EBS, en dat is het. Dit maakt uw infrastructuur veel gemakkelijker te beheren omdat elke server gelijk is; u heeft geen speciale servers met speciale gegevens of bestanden erop. Dus het kan u niet schelen als u uw hele infrastructuur verliest omdat u gewoon een nieuwe kunt maken en de gegevens van een aparte opslag kunt halen, en u bent weer klaar om te gaan.
Terugkomend op het Redis-voorbeeld: de Redis-service draait op de servers en gebruikt server-RAM om de gegevens op te slaan, terwijl de append-only logbestanden en momentopnamen worden bewaard op een schijf buiten die servers, waardoor uw gegevens duurzamer worden.
Kostenoptimalisatie met Redis on Flash
Nu weten we dat je gegevens met Redis kunt persisten voor duurzaamheid en herstel terwijl je RAM of geheugenopslag gebruikt voor geweldige prestaties en snelheid. Dus de vraag die je hier misschien hebt is: Is het opslaan van gegevens in het geheugen duur? Omdat je meer servers nodig zou hebben in vergelijking met een database die gegevens op een schijf opslaat simpelweg omdat het geheugen beperkt is in omvang. Er is een afweging tussen de kosten en prestaties.
Nou, Redis heeft eigenlijk een manier om dit te optimaliseren met behulp van een service genaamd Redis on Flash, wat onderdeel is van Redis Enterprise.
Hoe Redis on Flash werkt
Het is eigenlijk een vrij eenvoudig concept: Redis on Flash breidt het RAM uit naar de flashdrive of SSD, waar vaak gebruikte waarden in het RAM worden opgeslagen en de minder vaak gebruikte waarden op de SSD worden opgeslagen. Dus, voor Redis, is het gewoon meer RAM op de server. Dit betekent dat Redis meer van de onderliggende infrastructuur of de onderliggende serverbronnen kan gebruiken door zowel RAM als SSD-schijf te gebruiken om de gegevens op te slaan, waardoor de opslagcapaciteit op elke server toeneemt, en op deze manier kosten voor infrastructuur bespaart.
Opschalen van Redis: Replicatie en Sharding
We hebben gesproken over gegevensopslag voor de Redis-database en hoe het allemaal werkt, inclusief de beste praktijken. Nu is een ander zeer interessant onderwerp hoe we een Redis-database schalen?
Replicatie en hoge beschikbaarheid
Stel dat mijn enkele Redis-instantie geen geheugen meer heeft, dus de gegevens te groot worden om in het geheugen te houden, of Redis een bottleneck wordt en niet meer verzoeken aankan. In zo’n geval, hoe vergroot ik de capaciteit en geheugengrootte van mijn Redis-database?
We hebben verschillende opties daarvoor. Ten eerste, Redis ondersteunt clustering, wat betekent dat je een primaire of master Redis-instantie kunt hebben die kan worden gebruikt om gegevens te lezen en te schrijven, en je kunt meerdere replica’s van die primaire instantie hebben voor het lezen van de gegevens. Op deze manier kun je Redis schalen om meer aanvragen aan te kunnen en bovendien de hoge beschikbaarheid van je database te vergroten. Als de master faalt, kan een van de replica’s het overnemen, en je Redis-database kan in wezen blijven functioneren zonder problemen.
Deze replica’s zullen allemaal kopieën van de gegevens van de primaire instantie bevatten. Hoe meer replica’s je hebt, hoe meer geheugenruimte je nodig hebt. En één server heeft misschien niet genoeg geheugen voor al je replica’s. Bovendien, als je alle replica’s op één server hebt en die server faalt, is je hele Redis-database weg en heb je downtime. In plaats daarvan wil je deze replica’s verdelen over meerdere knooppunten of servers. Bijvoorbeeld, je master-instantie zal op één knooppunt zijn en twee replica’s op de andere twee knooppunten.
Sharding voor Grotere Datasetten
Nou, dat lijkt goed genoeg, maar wat als je dataset te groot groeit om in het geheugen op een enkele server te passen? Bovendien hebben we de leesbewerkingen in de database geschaald, dus alle aanvragen queryen in wezen gewoon de gegevens, maar onze master-instantie staat nog steeds alleen en moet nog steeds alle schrijfbewerkingen afhandelen. Dus, wat is hier de oplossing?

Voor dat doel gebruiken we het concept van sharding, wat een algemeen concept is in databases en ook door Redis wordt ondersteund. Sharding betekent in feite dat je je volledige dataset neemt en deze verdeeld in kleinere stukken of subsets van gegevens, waarbij elke shard verantwoordelijk is voor zijn eigen subset van gegevens.
Dat betekent dat je in plaats van één masterinstantie die alle schrijfacties naar de volledige dataset beheert, het kunt splitsen in, laten we zeggen, vier shards, die elk verantwoordelijk zijn voor lezen en schrijven naar een subset van de gegevens. Elke shard heeft ook minder geheugencapaciteit nodig omdat deze slechts een vierde van de gegevens bevat. Dit betekent dat je shards kunt distribueren en draaien op kleinere knooppunten en in principe je cluster horizontaal kunt schalen. En natuurlijk, naarmate je dataset groeit en je nog meer middelen nodig hebt, kun je je Redis-database opnieuw sharden, wat in wezen betekent dat je je gegevens in nog kleinere stukken splitst en meer shards creëert.

Het hebben van meerdere knooppunten die meerdere replica’s van Redis draaien, die allemaal geshard zijn, geeft je een zeer performante, hoog beschikbare Redis-database die veel meer verzoeken kan verwerken zonder knelpunten te creëren.
Nu moet ik hier opmerken dat deze setup geweldig is, maar je moet het zelf beheren, de schaling doen, knooppunten toevoegen, sharden en vervolgens resharding, enzovoort. Voor sommige teams die meer gefocust zijn op applicatieontwikkeling en meer bedrijfslogica dan op het draaien en onderhouden van dataservices, kan dit veel ongewenste inspanning zijn. Dus, als een eenvoudigere optie, krijg je in Redis Enterprise deze soort setup automatisch omdat de schaling, sharding, enzovoort allemaal voor jou worden beheerd.
Global Replicatie Met Redis: Actief-Actieve Implementatie
Laten we een ander interessant scenario overwegen voor toepassingen die nog hogere beschikbaarheid en prestaties nodig hebben over meerdere geografische locaties. Dus laten we zeggen dat we deze gerepliceerde, geshardede Redis-databasecluster hebben in één regio, in het datacenter van Londen, Europa. Maar we hebben de twee volgende use cases:
- Onze gebruikers zijn geografisch verspreid, dus ze benaderen de applicatie van over de hele wereld. We willen onze toepassing en dataservices wereldwijd distribueren, dicht bij de gebruikers, om onze gebruikers betere prestaties te bieden.
- Als het volledige datacenter in Londen, Europa, bijvoorbeeld uitvalt, willen we direct overschakelen naar een ander datacenter zodat de Redis-service beschikbaar blijft. Met andere woorden, we willen replica’s van de hele Redis-cluster in datacenters op meerdere geografische locaties of regio’s.
Meerdere Redis-clusters over regio’s
Dit betekent dat een enkele dataset gerepliceerd moet worden naar vele clusters verspreid over meerdere regio’s, waarbij elke cluster volledig in staat is om lees- en schrijfopdrachten te accepteren. In dat geval zou je meerdere Redis-clusters hebben die zullen fungeren als lokale Redis-instanties in elke regio, en de data zal worden gesynchroniseerd over deze geografisch verspreide clusters. Dit is een functie beschikbaar in Redis Enterprise en wordt actief-actieve implementatie genoemd omdat je meerdere actieve databases hebt op verschillende locaties.

Met deze opstelling hebben we lagere latentie voor de gebruikers. En zelfs als de Redis-database in één regio volledig uitvalt, zullen de andere regio’s onaangetast blijven. Als de verbinding of synchronisatie tussen de regio’s korte tijd verbroken is vanwege een netwerkprobleem, kunnen de Redis-clusters in deze regio’s de gegevens onafhankelijk bijwerken, en zodra de verbinding is hersteld, kunnen ze die wijzigingen opnieuw synchroniseren.
Conflict Resolutie Met CRDT’s
Nu, natuurlijk, wanneer je dat hoort, is de eerste vraag die in je opkomt: Hoe lost Redis de wijzigingen in meerdere regio’s naar dezelfde dataset op? Dus, als dezelfde gegevens in meerdere regio’s veranderen, hoe zorgt Redis ervoor dat gegevenswijzigingen van een regio niet verloren gaan en dat de gegevens correct worden gesynchroniseerd, en hoe zorgt het voor gegevensconsistentie?
Specifiek gebruikt Redis Enterprise een concept genaamd CRDT’s, wat staat voor conflict-vrije gerepliceerde gegevens typen, en dit concept wordt gebruikt om eventuele conflicten automatisch op te lossen op het databaseniveau en zonder dataverlies. Dus in wezen heeft Redis zelf een mechanisme voor het samenvoegen van de wijzigingen die zijn aangebracht aan dezelfde dataset vanuit meerdere bronnen op een manier dat geen van de gegevenswijzigingen verloren gaan en eventuele conflicten op de juiste manier worden opgelost. En aangezien, zoals je hebt geleerd, Redis meerdere gegevenstypen ondersteunt, gebruikt elk gegevenstype zijn eigen regels voor gegevensconflictoplossing, die het meest optimaal zijn voor dat specifieke gegevenstype.

Eenvoudig gezegd, in plaats van alleen de wijzigingen van één bron te overschrijven en alle andere te negeren, worden alle parallelle wijzigingen behouden en intelligent opgelost. Nogmaals, dit wordt automatisch voor je gedaan met deze actieve-actieve geo-replicatie functie, dus daar hoef je je geen zorgen over te maken.
Redis draaien in Kubernetes
En het laatste onderwerp dat ik wil bespreken met Redis is Redis draaien in Kubernetes. Zoals ik al zei, is Redis een uitstekende keuze voor complexe microservices die meerdere datatypes moeten ondersteunen en die een gemakkelijke schaalvergroting van een database nodig hebben zonder je zorgen te maken over gegevensconsistentie. En we weten ook dat het nieuwe standaard voor het draaien van microservices het Kubernetes-platform is. Dus, Redis draaien in Kubernetes is een zeer interessante en veelvoorkomende use case. Hoe werkt dat?

Open Source Redis op Kubernetes
Met open-source Redis kun je gerepliceerde Redis implementeren als een Helm-chart of Kubernetes-manifestbestanden en, in wezen, met behulp van de replicatie- en schaalregels waar we het al over gehad hebben, een zeer beschikbare Redis-database opzetten en draaien. Het enige verschil zou zijn dat de hosts waar Redis op draait Kubernetes-pods zullen zijn in plaats van bijvoorbeeld EC2-instanties of andere fysieke of virtuele servers. Maar dezelfde sharding-, replicatie- en schaalconcepten zijn hier ook van toepassing wanneer je een Redis-cluster in Kubernetes wilt draaien, en je zou dat opzet zelf moeten beheren.
Redis Enterprise Operator
Echter, zoals ik al zei, willen veel teams niet de moeite nemen om deze diensten van derden te onderhouden omdat ze liever hun tijd en middelen investeren in applicatieontwikkeling of andere taken. Dus, het hebben van een gemakkelijker alternatief is hier ook belangrijk. Redis Enterprise heeft een beheerd Redis-cluster, dat je kunt implementeren als een Kubernetes-operator.

Als je niet bekend bent met operators, is een operator in Kubernetes in feite een concept waarbij je alle benodigde middelen bundelt om een bepaalde applicatie of dienst te bedienen, zodat je het niet zelf hoeft te beheren of bedienen. In plaats van een mens die een database bedient, heb je in feite al deze logica in geautomatiseerde vorm om een database voor jou te bedienen. Veel databases hebben operators voor Kubernetes, en elke operator heeft natuurlijk zijn eigen logica op basis van wie ze heeft geschreven en hoe ze deze hebben geschreven.
De Redis Enterprise op Kubernetes-operator automatiseert specifiek de implementatie en configuratie van de volledige Redis-database in je Kubernetes-cluster. Het regelt ook het schalen, het maken van back-ups en het herstellen van het Redis-cluster indien nodig, enzovoort. Dus, het neemt de volledige werking van het Redis-cluster over binnen het Kubernetes-cluster.
Conclusie
Ik hoop dat je veel hebt geleerd in deze blog en dat ik veel van je vragen heb kunnen beantwoorden. Als je meer wilt leren over vergelijkbare technologieën en concepten, zorg er dan voor dat je me volgt, want ik schrijf regelmatig blogs over AI, DevOps en cloudtechnologieën.
Laat ook hieronder een reactie achter als je vragen hebt over Redis of suggesties voor nieuwe onderwerpen. En daarmee, bedankt voor het lezen en tot ziens in de volgende blog.
Laten we verbinden op LinkedIn!
Source:
https://dzone.com/articles/redis-as-a-primary-database-for-complex-applications