













أولاً، سنرى ما هو ريديس واستخدامه، بالإضافة إلى سبب ملاءمته لتطبيقات الخدمات المتعددة المعقدة الحديثة. سنتحدث عن كيفية دعم ريديس لتخزين تنسيقات بيانات متعددة لأغراض مختلفة من خلال وحداته. بعد ذلك، سنرى كيف يمكن لريديس، كقاعدة بيانات في الذاكرة، الاحتفاظ بالبيانات واستعادتها من فقدان البيانات. كما سنتحدث عن كيفية تحسين ريديس لتكاليف تخزين الذاكرة باستخدام ريديس على الفلاش.
ثم، سنرى حالات استخدام مثيرة للاهتمام لتوسيع ريديس وتكراره عبر مناطق جغرافية متعددة. وأخيرًا، نظرًا لأن أحد أشهر منصات تشغيل الخدمات الصغيرة هو كوبرنيتيس، ونظرًا لأن تشغيل التطبيقات ذات الحالة في كوبرنيتيس يعتبر تحديًا بعض الشيء، سنرى كيف يمكنك تشغيل ريديس بسهولة على كوبرنيتيس.
ما هو ريديس؟
ريديس، الذي يقف في الواقع لـ Remote Dictionary Server، هو قاعدة بيانات في الذاكرة. استخدم العديد من الأشخاص ريديس كذاكرة تخزين مؤقتة فوق قواعد بيانات أخرى لتحسين أداء التطبيق. ومع ذلك، ما لا يعرفه الكثيرون هو أن ريديس هو قاعدة بيانات أساسية كاملة يمكن استخدامها لتخزين واحتفاظ بتنسيقات بيانات متعددة لتطبيقات معقدة.
مثال على تطبيق وسائل التواصل الاجتماعي المعقد
لنلقِ نظرة على إعداد شائع لتطبيق خدمات صغيرة. لنقل أن لدينا تطبيق وسائل تواصل اجتماعي معقد مع ملايين المستخدمين. ولنقل أن تطبيق خدماتنا الصغيرة يستخدم قاعدة بيانات علاقية مثل MySQL لتخزين البيانات. بالإضافة إلى ذلك، لأننا نقوم بجمع أطنان من البيانات يوميًا، لدينا قاعدة بيانات Elasticsearch للتصفية والبحث السريع عن البيانات.
الآن، المستخدمون متصلون جميعًا ببعضهم البعض، لذا نحتاج إلى قاعدة بيانات رسومية لتمثيل هذه الاتصالات. بالإضافة إلى ذلك، تحتوي تطبيقنا على العديد من محتويات الوسائط التي يشاركها المستخدمون مع بعضهم البعض يوميًا، ولهذا، لدينا قاعدة بيانات وثائقية. وأخيرًا، لتحسين أداء التطبيق، لدينا خدمة ذاكرة مؤقتة تقوم بتخزين بيانات من القواعد البيانات الأخرى وتجعلها متاحة بشكل أسرع.
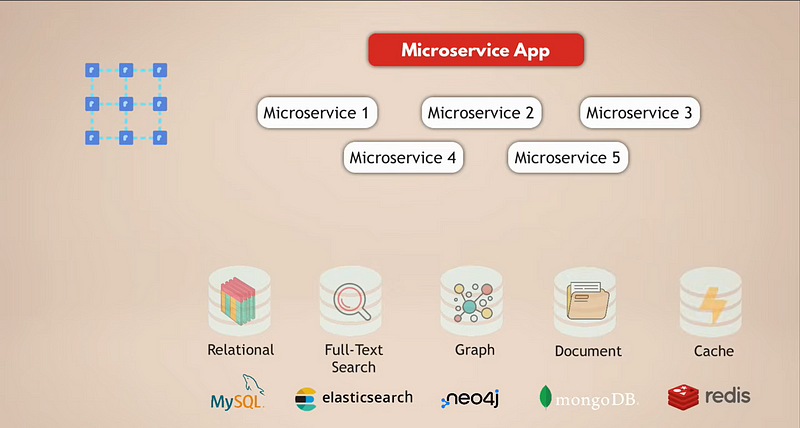
الآن، من الواضح أن هذا إعداد معقد للغاية. لنرى ما هي التحديات في هذا الإعداد:
1. نشر وصيانة
يجب أن تكون جميع خدمات البيانات هذه مُنشأة، تُشغَّل، ومُصانة. هذا يعني أن فريقك يحتاج إلى بعض المعرفة حول كيفية تشغيل جميع خدمات البيانات هذه.
2. توسيع ومتطلبات البنية التحتية
من أجل توفير توافر عالي وأداء أفضل، سترغب في توسيع خدماتك. كل هذه خدمات البيانات تتوسع بطريقة مختلفة ولها متطلبات بنية تحتية مختلفة، وهذا قد يكون تحديًا إضافيًا. لذا، بشكل عام، استخدام خدمات البيانات المتعددة لتطبيقك يزيد من جهد الصيانة لإعداد تطبيقك بأكمله.
3. تكاليف السحاب
بالطبع، كبديل أسهل لتشغيل وإدارة الخدمات بنفسك، يمكنك استخدام خدمات البيانات المُدارة من مزودي السحابة. ولكن هذا قد يكون مكلفًا جدًا لأنه في منصات السحابة، تدفع مقابل كل خدمة بيانات مدارة على حدة.
4. تعقيد التطوير
5. تأخير أعلى
كيف يبسط Redis هذا التعقيد
مقارنةً بقاعدة بيانات متعددة النماذج مثل Redis، تحل معظم هذه التحديات:
- خدمة بيانات واحدة. تقوم بتشغيل وصيانة خدمة بيانات واحدة فقط. لذلك، تحتاج التطبيقات الخاصة بك أيضًا للتحدث مع مخزن بيانات واحد فقط، مما يعني واجهة برمجية واحدة فقط لتلك الخدمة البيانية.
- تقليل التأخير. سيتم تقليل التأخير عن طريق الانتقال إلى نقطة بيانات واحدة والتخلص من العديد من نقاط التوصيل الداخلية.
- أنواع بيانات متعددة في واحدة. أن يكون لديك قاعدة بيانات واحدة مثل Redis التي تسمح لك بتخزين أنواع مختلفة من البيانات (أي، أنواع متعددة من قواعد البيانات في واحدة) وكذلك تكون كذاك ذاكرة تخزين مؤقت تحل مثل هذه التحديات.
كيف يدعم Redis تنسيقات بيانات متعددة
لذا، دعنا نرى كيف يعمل Redis فعليًا. أولًا، كيف يدعم Redis تنسيقات بيانات متعددة في قاعدة بيانات واحدة؟
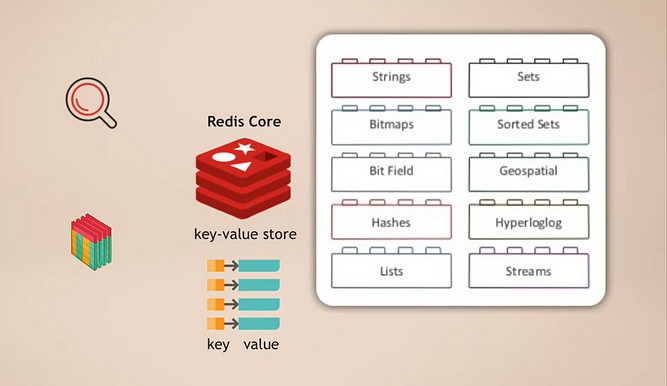
النواة والوحدات النمطية في Redis
الطريقة التي تعمل بها هي أن لديك Redis core، وهو مخزن مفاتيح وقيم يدعم بالفعل تخزين أنواع متعددة من البيانات. ثم، يمكنك توسيع هذا النواة بما يسمى الوحدات لأنواع بيانات مختلفة، التي يحتاجها تطبيقك لأغراض مختلفة. على سبيل المثال:
- RedisSearch لوظيفة البحث (مثل Elasticsearch)
- RedisGraph لتخزين بيانات الرسوم البيانية
شيء رائع في هذا هو أنه يعتمد على الوحدات. هذه الأنواع المختلفة من وظائف قواعد البيانات ليست متكاملة بشكل صارم في قاعدة بيانات واحدة كما في العديد من قواعد البيانات متعددة الوسائط الأخرى، بل يمكنك اختيار بالضبط الوظيفة التي تحتاجها لتطبيقك ثم ببساطة إضافة تلك الوحدة.
التخزين المؤقت المدمج
وبالطبع، عند استخدام Redis كقاعدة بيانات أساسية، فإنك لا تحتاج إلى ذاكرة تخزين مؤقت إضافية لأن لديك ذلك تلقائيًا مع Redis. وهذا يعني، مرة أخرى، أقل تعقيد في تطبيقك لأنه لا يلزمك تنفيذ منطق إدارة وملء وإبطال التخزين المؤقت.
أداء عالي واختبارات أسرع
أخيرًا، كقاعدة بيانات في الذاكرة، يعتبر ريديس سريعًا للغاية وفعالًا، مما يجعل التطبيق ذاته أسرع بالطبيعة. بالإضافة إلى ذلك، يجعل تشغيل اختبارات التطبيق أسرع بكثير، لأن ريديس لا يحتاج إلى مخطط كغيره من قواعد البيانات. لذلك، لا يحتاج إلى وقت لبدء تهيئة قاعدة البيانات، أو بناء المخطط، وما إلى ذلك قبل تشغيل الاختبارات. يمكنك بدء استخدام قاعدة بيانات ريديس فارغة في كل مرة وتوليد البيانات اللازمة للاختبارات. يمكن أن تزيد الاختبارات السريعة حقًا من إنتاجيتك في التطوير.
استمرارية البيانات في ريديس
فهمنا كيف يعمل ريديس وجميع فوائده. ولكن في هذه النقطة، قد تتساءل: كيف يمكن لقاعدة البيانات في الذاكرة البقاء على البيانات؟ لأنه إذا توقفت عملية ريديس الرئيسية أو الخادم الذي يعمل عليه ريديس، فإن جميع البيانات في الذاكرة تختفي، أليس كذلك؟ وإذا فقدت البيانات، كيف يمكنني استعادتها؟ إذن، بشكل أساسي، كيف يمكنني أن أكون واثقًا من أمان بياناتي؟
أبسط طريقة للحصول على نسخ احتياطية للبيانات هي عن طريق تكرار ريديس. لذا، إذا توقفت عملية ريديس الرئيسية، فسيظل النسخ الاحتياطية قيد التشغيل وتحتفظ بجميع البيانات. إذا كان لديك ريديس مكرر، فسيكون لدى النسخ الاحتياطية البيانات. ولكن بالطبع، إذا توقفت جميع حالات ريديس، فستفقد البيانات لأنه لن يكون هناك نسخة احتياطية باقية.
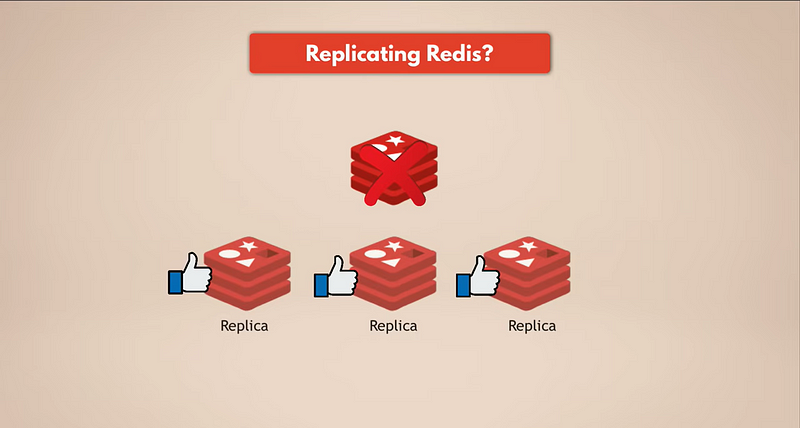
نحتاج إلى استمرارية حقيقية.
لقطة (RDB)
تتوفر لدى Redis آليات متعددة للحفاظ على البيانات وضمان سلامتها. الآلية الأولى هي اللقطات (snapshots)، التي يمكنك تكوينها بناءً على الوقت أو عدد الطلبات، وما إلى ذلك. ستتم تخزين لقطات بياناتك على قرص، الذي يمكنك استخدامه لاستعادة بياناتك إذا اختفت قاعدة بيانات Redis بأكملها. ولكن عليك ملاحظة أنك ستفقد الدقائق الأخيرة من البيانات، لأنه عادةً ما تكون عملية اللقطة كل خمس دقائق أو ساعة، اعتمادًا على احتياجاتك.
ملف AOF (Append Only File)
بديلاً، يستخدم Redis شيئًا يُسمى AOF، الذي يعني ملف الإضافة فقط (Append Only File). في هذه الحالة، يتم حفظ كل تغيير على القرص للحفظ باستمرار. عند إعادة تشغيل Redis أو بعد حدوث انقطاع في التشغيل، سيقوم Redis بإعادة تشغيل سجلات ملف الإضافة فقط لإعادة بناء الحالة. لذا، يعتبر AOF أكثر دوامة ولكن قد يكون أبطأ من عملية اللقطات.
مزيج من اللقطات و AOF
وبالطبع، يمكنك أيضًا استخدام مزيج من كل من AOF واللقطات، حيث يتم حفظ بيانات الإضافة فقط من الذاكرة إلى القرص باستمرار، بالإضافة إلى إجراء لقطات منتظمة بين الحين والآخر لحفظ حالة البيانات في حالة الحاجة إلى استعادتها. هذا يعني أنه حتى إذا فشلت قاعدة بيانات Redis نفسها أو الخوادم، أو البنية التحتية التي يعمل عليها Redis، ستظل لديك جميع بياناتك آمنة ويمكنك إعادة إنشاء وإعادة تشغيل قاعدة بيانات Redis جديدة بكل البيانات.
أين تكون هذه التخزينة المستمرة؟
سؤال مثير للاهتمام جدًا هو، أين تكون هذه التخزينة المستمرة؟ فأين يتم تخزين تلك القرص الذي يحتوي على لقطاتك وسجلات ملف الإضافة فقط؟ هل تكون على نفس الخوادم التي يعمل عليها Redis؟
هذا السؤال في الواقع يقودنا إلى الاتجاه أو أفضل ممارسة للثبات البيانات في بيئات السحابة، والتي تقول أنه دائمًا من الأفضل فصل الخوادم التي تشغل تطبيقك وخدمات البيانات عن التخزين الثابت الذي يخزن بياناتك.
بمثال محدد: إذا كانت تطبيقاتك وخدماتك تعمل في السحابة على، فلنقل، مثيل EC2 من AWS، يجب عليك استخدام EBS أو تخزين الكتل المرنة للثبات بياناتك بدلاً من تخزينها على قرص الـEC2. لأنه إذا تعطل ذلك المثيل EC2، فلن تكون لديك وصول إلى أي من تخزينه، سواء كان ذاكرة الوصول العشوائي أو تخزين القرص أو غيره. لذلك، إذا كنت ترغب في الثبات والمتانة لبياناتك، يجب عليك وضع بياناتك خارج المثيلات على تخزين شبكي خارجي.
ونتيجة لفصل هذين العنصرين، إذا فشل مثيل الخادم أو إذا فشلت جميع المثيلات، ستظل لديك القرص وكل البيانات عليه دون تأثر. ببساطة ستقوم بإطلاق مثيلات أخرى واستخراج البيانات من EBS، وهذا كل ما عليك فعله. يجعل هذا الأمر من السهل جدًا إدارة البنية التحتية لديك لأن كل خادم متساوٍ. ليس لديك أي خوادم خاصة تحتوي على بيانات أو ملفات خاصة عليها. لذا لا يهم إذا فقدت كامل بنيتك التحتية لأنه يمكنك ببساطة إعادة إنشاء واحدة جديدة واستخراج البيانات من تخزين منفصل، وستكون جاهزًا للعمل مرة أخرى.
وعند العودة إلى مثال Redis، ستعمل خدمة Redis على الخوادم واستخدام ذاكرة الخادم لتخزين البيانات، بينما ستتم الاستمرارية لسجلات الملف الخاصة بالإلحاق واللقطات على قرص خارجي خارج تلك الخوادم، مما يجعل بياناتك أكثر متانة.
تحسين التكلفة مع Redis on Flash
الآن نعلم أنه يمكنك الاحتفاظ بالبيانات باستخدام Redis للمتانة والاسترداد أثناء استخدام الذاكرة العشوائية أو التخزين في الذاكرة للحصول على أداء رائع وسرعة. لذا، السؤال الذي قد تكون لديك هنا هو: هل تخزين البيانات في الذاكرة مكلف؟ لأنه ستحتاج إلى مزيد من الخوادم مقارنة بقاعدة بيانات تخزن البيانات على القرص ببساطة لأن الذاكرة محدودة الحجم. هناك توازن بين التكلفة والأداء.
حسنًا، في الواقع، يحتوي Redis على طريقة لتحسين هذا باستخدام خدمة تسمى Redis on Flash، والتي تعتبر جزءًا من Redis Enterprise.
كيف يعمل Redis on Flash
إنه مفهوم بسيط جدًا، في الواقع: يعمل Redis on Flash على توسيع الذاكرة العشوائية إلى محرك الفلاش أو SSD، حيث يتم تخزين القيم التي تُستخدم بشكل متكرر في الذاكرة وتخزين القيم التي لا تُستخدم كثيرًا على SSD. لذلك، بالنسبة لـ Redis، فهو مجرد ذاكرة إضافية على الخادم. وهذا يعني أنه يمكن لـ Redis استخدام موارد البنية التحتية أو موارد الخادم الأساسية بشكل أكبر عن طريق استخدام كل من الذاكرة العشوائية ومحرك SSD لتخزين البيانات، مما يزيد من قدرة التخزين على كل خادم، وبهذه الطريقة يمكنك توفير تكاليف البنية التحتية.
توسيع Redis: التكرار والتجزئة
لقد تحدثنا عن تخزين البيانات لقاعدة بيانات Redis وكيفية عمل كل شيء، بما في ذلك أفضل الممارسات. الآن موضوع آخر مثير للاهتمام للغاية هو كيفية توسيع قاعدة بيانات Redis؟
التكرار والتوفرية العالية
لنفترض أن إحدى حالات Redis تنفذ من الذاكرة، لذا يصبح حجم البيانات كبيرًا جدًا لتخزينه في الذاكرة، أو يصبح Redis عائقًا ولا يمكنه تلبية المزيد من الطلبات. في مثل هذه الحالة، كيف يمكنني زيادة السعة وحجم الذاكرة في قاعدة بيانات Redis الخاصة بي؟
لدينا العديد من الخيارات لذلك. أولاً، Redis يدعم التجزئة، مما يعني أنه يمكنك أن تمتلك مثيلًا أساسيًا أو رئيسيًا لـ Redis يمكن استخدامه لقراءة وكتابة البيانات، ويمكنك أن تمتلك عدة نسخ من هذا المثيل الأساسي لقراءة البيانات. بهذه الطريقة، يمكنك توسيع Redis لمعالجة المزيد من الطلبات، وبالإضافة إلى ذلك، زيادة توافر قاعدة البيانات الخاصة بك. إذا فشل المثيل الرئيسي، يمكن لإحدى النسخ الاحتياطية الاستيلاء عليه، ويمكن أن تستمر قاعدة بيانات Redis الخاصة بك بالعمل بشكل أساسي دون أية مشاكل.
سيحتوي كل هذه النسخ الاحتياطية على نسخ من بيانات المثيل الأساسي. لذلك، كلما زاد عدد النسخ الاحتياطية التي تمتلكها، زادت مساحة الذاكرة التي تحتاجها. وقد لا يكون لدى خادم واحد ذاكرة كافية لجميع النسخ الاحتياطية الخاصة بك. بالإضافة إلى ذلك، إذا كانت جميع النسخ الاحتياطية على خادم واحد وفشل هذا الخادم، فإن قاعدة بيانات Redis الخاصة بك ستختفي، وستواجه فترة توقف. بدلاً من ذلك، تريد توزيع هذه النسخ الاحتياطية بين عدة عقد أو خوادم. على سبيل المثال، سيكون مثيل الرئيس على عقد واحد وسيكون هناك نسختان احتياطيتان على العقدين الآخرين.
التجزئة لمجموعات بيانات أكبر
حسنًا، يبدو أن هذا كافٍ، ولكن ماذا لو نمت مجموعة البيانات الخاصة بك بشكل كبير جدًا بحيث لا تناسب في الذاكرة على خادم واحد؟ بالإضافة إلى ذلك، لقد قمنا بتوسيع القراءة في قاعدة البيانات، لذلك تقوم جميع الطلبات بشكل أساسي بالاستعلام عن البيانات، ولكن مثيلنا الرئيسي لا يزال وحيدًا ولا يزال يجب عليه معالجة جميع عمليات الكتابة. إذاً، ما هو الحل هنا؟

بالنسبة لذلك، نستخدم مفهوم التجزئة، والذي هو مفهوم عام في قواعد البيانات والذي يدعمه Redis أيضًا. التجزئة تعني ببساطة أنك تأخذ مجموعة البيانات الكاملة وتقسمها إلى قطع أو مجموعات بيانات أصغر، حيث تكون كل قطعة مسؤولة عن مجموعة بياناتها الخاصة.
هذا يعني بدلاً من وجود مثيل رئيسي واحد يتعامل مع كل الكتابات إلى مجموعة البيانات الكاملة؛ يمكنك تقسيمها إلى، دعونا نقول، أربع قطع، يكون كل منها مسؤولاً عن القراءات والكتابات إلى جزء من البيانات. تحتاج كل قطعة أيضًا إلى سعة ذاكرة أقل لأنها تحتوي فقط على ربع البيانات. هذا يعني أنه يمكنك توزيع القطع وتشغيلها على عقد أصغر وببساطة توسيع عقدتك أفقيًا. وبالطبع، عندما تنمو مجموعة البيانات الخاصة بك وعندما تحتاج إلى موارد أكثر، يمكنك إعادة تجزئة قاعدة بيانات Redis الخاصة بك، والتي تعني ببساطة تقسيم بياناتك إلى قطع أصغر وإنشاء المزيد من القطع.

لذلك، وجود عقدات متعددة تعمل بمضاعفات متعددة من Redis، والتي تكون جميعها مجزأة، يمنحك قاعدة بيانات Redis فعالة للغاية ومتوفرة بشكل كبير يمكنها التعامل مع المزيد من الطلبات دون إنشاء أي ضغوط.
الآن، يجب علي أن أشير هنا إلى أن هذا الإعداد رائع، ولكن قد تحتاج إلى إدارته بنفسك، القيام بالتوسيع، إضافة عقدات، القيام بالتجزئة، ثم إعادة التجزئة، إلخ. بالنسبة لبعض الفرق التي تركز أكثر على تطوير التطبيقات والمنطق التجاري بدلاً من تشغيل وصيانة خدمات البيانات، قد يكون هذا جهدًا غير مرغوب فيه. لذا، كبديل أسهل، في Redis Enterprise، تحصل على هذا النوع من الإعداد تلقائيًا لأن التوسيع والتجزئة، وما إلى ذلك، يتم إدارتها جميعًا من أجلك.
التكرار العالمي مع Redis: نشر نشط-نشط
لنفترض سيناريوًا آخر مثير للاهتمام لتطبيقات تحتاج إلى توفير توفر وأداء أعلى عبر عدة مواقع جغرافية. لذلك دعونا نقول إن لدينا مجموعة من قواعد بيانات Redis المُستنسَخة والمُجزأة في إحدى المناطق، في مركز بيانات لندن بأوروبا. لكن لدينا حالتي استخدام كالتالي:
- مستخدمونا موزعون جغرافيًا، لذلك يقومون بالوصول إلى التطبيق من جميع أنحاء العالم. نريد توزيع تطبيقنا وخدمات البيانات على نطاق عالمي، قرب المستخدمين، لتحسين أداء مستخدمينا.
- إذا تعطل مركز البيانات بالكامل في لندن، أوروبا، على سبيل المثال، نريد التبديل الفوري إلى مركز بيانات آخر بحيث تظل خدمة Redis متاحة. بمعنى آخر، نريد نسخًا احتياطية من مجموعة Redis بأكملها في مراكز بيانات في عدة مواقع جغرافية أو مناطق.
مجموعات Redis متعددة عبر المناطق
هذا يعني أنه يجب نسخ بيانات واحدة إلى العديد من المجموعات المنتشرة عبر عدة مناطق، حيث يكون كل مجموعة قادرة تمامًا على قبول القراءات والكتابات. في هذه الحالة، ستمتلك مجموعات Redis متعددة ستعمل كمثيلات Redis محلية في كل منطقة، وسيتم مزامنة البيانات عبر هذه المجموعات المنتشرة جغرافيًا. هذه ميزة متوفرة في Redis Enterprise وتُسمى نشر نشط-نشط لأن لديك قواعد بيانات نشطة متعددة في مواقع مختلفة.

مع هذا الإعداد، ستكون التأخير أقل للمستخدمين. وحتى إذا تعطلت قاعدة بيانات Redis في إحدى المناطق تمامًا، فإن المناطق الأخرى لن تتأثر. إذا تم قطع الاتصال أو التزامن بين المناطق لفترة قصيرة بسبب مشكلة شبكة ما، على سبيل المثال، يمكن لمجموعات Redis في هذه المناطق تحديث البيانات بشكل مستقل، وبمجرد استعادة الاتصال، يمكنها مزامنة تلك التغييرات مرة أخرى.
حل النزاعات باستخدام CRDTs
الآن، بالطبع، عند سماعك لذلك، قد تتبادر إلى ذهنك السؤال الأول: كيف يقوم Redis بحل التغييرات في عدة مناطق لنفس مجموعة البيانات؟ لذا، إذا تغيرت نفس البيانات في عدة مناطق، كيف يتأكد Redis من عدم فقدان تغييرات البيانات في أي منطقة ومزامنة البيانات بشكل صحيح، وكيف يضمن تماسك البيانات؟
تحديدًا، يستخدم Redis Enterprise مفهومًا يُسمى CRDTs، والذي يعني أنواع البيانات المُكررة بدون صراع، ويتم استخدام هذا المفهوم لحل أي صراعات تلقائيًا على مستوى قاعدة البيانات ودون فقدان أي بيانات. لذا في الأساس، يحتوي Redis بذاته على آلية لدمج التغييرات التي تم إجراؤها على نفس مجموعة البيانات من مصادر متعددة بحيث لا يتم فقدان أي تغييرات في البيانات ويتم حل أي صراعات بشكل صحيح. ونظرًا لدعم Redis لأنواع بيانات متعددة، يستخدم كل نوع بيانات قواعد تحليل النزاعات الخاصة به، والتي تكون الأكثر فعالية لهذا النوع البيانات المحدد.

ببساطة، بدلاً من تجاوز تغييرات مصدر واحد وتجاهل كل الآخرين، يتم الاحتفاظ بجميع التغييرات المتوازية وحلها بذكاء. مرة أخرى، يتم ذلك تلقائيًا لك من خلال ميزة التكرار الجغرافي النشطة، لذا لا داعي للقلق بشأن ذلك.
تشغيل Redis في Kubernetes
والموضوع الأخير الذي أرغب في التطرق إليه مع Redis هو تشغيل Redis في Kubernetes. كما ذكرت، فإن Redis مناسب تمامًا لخدمات الويب الدقيقة المعقدة التي تحتاج إلى دعم أنواع بيانات متعددة والتي تحتاج إلى توسيع قاعدة بيانات بسهولة دون القلق بشأن تناسق البيانات. ونحن نعلم أيضًا أن المعيار الجديد لتشغيل خدمات الويب الدقيقة هو منصة Kubernetes. لذا، تشغيل Redis في Kubernetes هو حالة استخدام مثيرة للاهتمام وشائعة جدًا. فكيف يعمل ذلك؟

Redis المفتوح المصدر على Kubernetes
مع Redis مفتوح المصدر، يمكنك نشر Redis المكرر كمخطط Helm أو ملفات توضيحية Kubernetes و، ببساطة، باستخدام قواعد التكرار والتوسيع التي تحدثنا عنها بالفعل، إعداد وتشغيل قاعدة بيانات Redis عالية التوافر. الفرق الوحيد سيكون هو أن الخوادم التي ستعمل عليها Redis ستكون أقراص Kubernetes بدلاً من، على سبيل المثال، حالات EC2 أو أي خوادم فيزيائية أو افتراضية أخرى. ولكن نفس مفاهيم التجزئة والتكرار والتوسيع تنطبق هنا أيضًا عندما ترغب في تشغيل مجموعة Redis في Kubernetes، وعليك ببساطة إدارة هذا الإعداد بنفسك.
مشغل Redis Enterprise
ومع ذلك، كما ذكرت، العديد من الفرق لا يرغبون في بذل الجهد للحفاظ على هذه الخدمات الطرفية لأنهم يفضلون استثمار وقتهم ومواردهم في تطوير التطبيقات أو مهام أخرى. لذا، من المهم هنا أيضًا وجود بديل أسهل. Redis Enterprise يحتوي على مجموعة Redis التي يمكنك نشرها كمشغل Kubernetes.

إذا لم تكن تعرف ما هي المشغلات، فالمشغل في Kubernetes هو في الأساس مفهوم يمكنك من خلاله تجميع جميع الموارد اللازمة لتشغيل تطبيق معين أو خدمة بحيث لا تحتاج إلى إدارته بنفسك أو تشغيله بنفسك. بدلاً من أن يقوم إنسان بتشغيل قاعدة بيانات، لديك ببساطة كل هذه المنطق في شكل مُتَّمَتِّ لتشغيل قاعدة بيانات بالنيابة عنك. العديد من قواعد البيانات لديها مشغلات لـ Kubernetes، ولكل مشغل من هذا القبيل منطقه الخاص بناءً على من كتبه وكيفية كتابته.
يقوم مشغل Redis Enterprise على Kubernetes بتلقائي تنفيذ نشر وتكوين قاعدة بيانات Redis بأكملها في مجموعة Kubernetes الخاصة بك. كما يهتم أيضًا بالتوسيع، وعمل النسخ الاحتياطي، واستعادة مجموعة Redis إذا لزم الأمر، إلخ. لذا، يتولى عملية تشغيل كاملة لمجموعة Redis داخل مجموعة Kubernetes.
الاستنتاج
آمل أن تعلمت الكثير من هذه المدونة وأنني تمكنت من الإجابة على العديد من أسئلتك. إذا كنت ترغب في معرفة المزيد عن التقنيات والمفاهيم المماثلة، فتأكد من متابعتي لأنني أكتب مدونات بانتظام حول الذكاء الاصطناعي وDevOps وتقنيات السحابة.
أيضًا، اترك تعليقًا أدناه إذا كان لديك أي أسئلة بخصوص Redis أو أي اقتراحات لمواضيع جديدة. ومع ذلك، شكرًا لقراءتك، ونراك في المدونة القادمة.
لنتواصل على لينكدإن!
Source:
https://dzone.com/articles/redis-as-a-primary-database-for-complex-applications