













ראשית, נצפה מהו Redis ושימושו, ולמה הוא מתאים ליישומים מודרניים ומורכבים של שירותי מיקרו. נדובר על כיצד Redis תומך באחסון פורמטים שונים למטרות שונות דרך המודולים שלו. לאחר מכן, נראה כיצד Redis, כמסד נתונים בזיכרון, יכול לשמור נתונים ולשחזר מאובדן נתונים. נדבר גם על כיצד Redis מגביר את עלויות אחסון הזיכרון באמצעות Redis on Flash.
לאחר מכן, נראה מקרים מאוד מעניינים של התרחבות של Redis ושכפולו ברחבי גאוגרפיים שונים. לבסוף, מאחר שאחת מהפלטפורמות הפופולריות ביותר עבור הרצת שירותי מיקרו היא Kubernetes, ומאחר שהרצתי שירותי עצמיים ב-Kubernetes מעט מאתגרת, נראה כיצד ניתן להריץ Redis בקלות על Kubernetes.
מהו Redis?
Redis, שבפועל עומד על Remote Dictionary Server, הוא מסד נתונים בזיכרון. כל כך הרבה אנשים השתמשו בו כמטמון מעל מסדי נתונים אחרים כדי לשפר את ביצועי היישום. אך מה שרבים אינם יודעים הוא ש-Redis הוא מסד נתונים ראשי מלא שניתן להשתמש בו כדי לאחסן ולשמור פורמטי נתונים מרובים עבור יישומים מורכבים.
דוגמה ליישום מורכב ביישומי רשתות חברתיות
בואו נסתכל על הגדרה נפוצה ליישום שירותים קטנים. נניח שיש לנו יישום רשת חברתית מורכב עם מיליוני משתמשים. ונניח שהיישום שלנו משתמש במסד נתונים רלציוני כמו MySQL כדי לאחסן את הנתונים. בנוסף, מאחר שאנו מאגדים כמויות רבות של נתונים יומיומית, יש לנו מסד נתונים Elasticsearch לסינון מהיר וחיפוש בנתונים.
עכשיו, המשתמשים מחוברים כולם אלו לאחד ולכן אנו זקוקים למסד נתונים גרפי כדי לייצג את החיבורים הללו. בנוסף, היישום שלנו מכיל המון תוכן מדיה שמשתמשים מחליפים אחד עם השני באופן יומיומי, ולכן יש לנו מסד נתונים תיעודי. לבסוף, לשיפור ביצועי היישום, יש לנו שירות מטמון שמטמן נתונים ממסדי נתונים אחרים והופך אותם לגישים יותר מהירים.
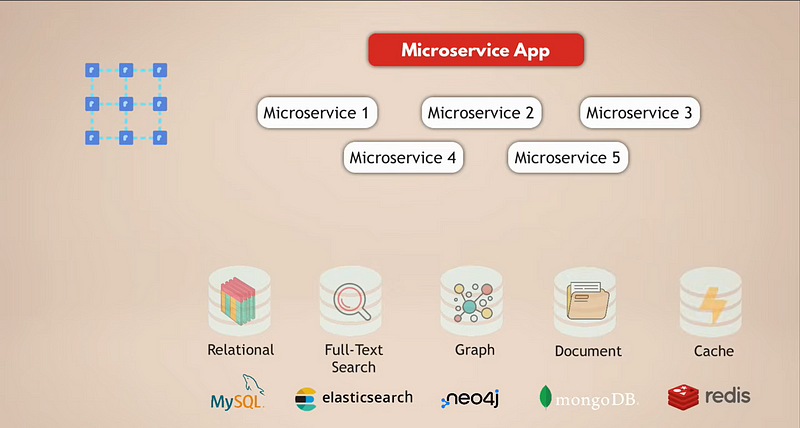
עכשיו, ברור שזהו הגדרה מורכבת די. בואו נראה מהן האתגרים של ההגדרה הזו:
1. התקנה ותחזוקה
כל שירותי הנתונים הללו צריכים להתקין, להפעיל ולתחזק. זה אומר שצוותך צריך לספק מעין מקצועות בנושא הפעלת כלל שירותי הנתונים הללו.
2. התרחבות ודרישות תשתיות
לזמינות גבוהה וביצועים טובים יותר, תרצה להרחיב את השירותים שלך. כל אחד משירותי הנתונים הללו מתרחב בדרך שונה ויש לו דרישות תשתיות שונות, וכך יכול להיות אתגר נוסף. לכן בסך הכול, השימוש במספר שירותי נתונים עבור היישום שלך מגביר את המאמץ של תחזוקת ההגדרה של כל היישום.
3. עלויות ענן
כמובן, כחלופה קלה יותר לניהול והפעלת השירותים בעצמך, אתה יכול להשתמש בשירותי נתונים מנוהלים מספקי ענן. אבל זה עלול להיות מאוד יקר כי, בפלטפורמות ענן, אתה משלם עבור כל שירות נתונים מנוהל בנפרד.
4. מורכבות הפיתוח
5. השהיה גבוהה יותר
מדוע Redis מפשטת את המורכבות הזו
בהשוואה למסד נתונים רב-מודלי כמו Redis, אתה פותר את רוב האתגרים הללו:
- שירות נתונים יחיד. אתה מפעיל ומתחזק רק שירות נתונים אחד. כך שהיישום שלך צריך לדבר גם עם מאגר נתונים אחד, מה שאומר שיש רק ממשק תכנותי אחד לשירות הנתונים הזה.
- השהיה מופחתת. ההשהיה תופחת על ידי מעבר לנקודת נתונים אחת והפחתת מספר קפיצות רשת פנימיות.
- מספר סוגי נתונים באחד. להחזיק במסד נתונים כמו Redis שמאפשר לך לאחסן סוגים שונים של נתונים (כלומר, מספר סוגי מסדי נתונים באחד) כמו גם לפעול כמטמון פותר את האתגרים הללו.
איך Redis תומכת בפורמטים מרובים של נתונים
אז, בואו נראה איך Redis באמת עובד. קודם כל, איך Redis תומכת בפורמטים מרובים של נתונים במסד נתונים אחד?
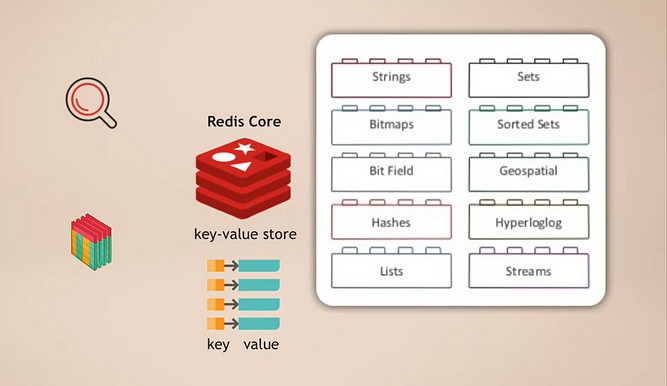
ליבת Redis ומודולים
הדרך שבה זה עובד היא שיש לך Redis core, שהוא חנות מפתח-ערך שכבר תומכת באחסון סוגים שונים של נתונים. לאחר מכן, אתה יכול להרחיב את הליבה הזו עם מה שנקרא מודולים לסוגי נתונים שונים, אשר האפליקציה שלך זקוקה להם למטרות שונות. לדוגמה:
- RedisSearch לפונקציונליות חיפוש (כמו Elasticsearch)
- RedisGraph לאחסון נתוני גרפים
דבר נהדר בזה הוא שזה מודולרי. סוגי הפונקציות השונות של מסדי נתונים אינם משולבים יחד במסד נתונים אחד כמו בהרבה מסדי נתונים רב-מודליים אחרים, אלא אתה יכול לבחור בדיוק איזו פונקציית שירות נתונים אתה זקוק לה לאפליקציה שלך ואז basically להוסיף את המודול הזה.
זיכרון מטמון מובנה
וכמובן, כאשר אתה משתמש ב-Redis כמסד נתונים ראשי, אתה לא זקוק למטמון נוסף כי יש לך את זה אוטומטית מהקופסה עם Redis. כלומר, שוב, פחות מורכבות באפליקציה שלך כי אתה לא צריך ליישם את הלוגיקה לניהול, אוכלוסייה, וביטול תוקף של המטמון.
ביצועים גבוהים ובדיקות מהירות יותר
לבסוף, כמאגר נתונים בזיכרון, רדיס הוא מהיר ומבצעי בצורה יוצאת דופן, דבר שעושה, כמובן, את האפליקציה עצמה מהירה יותר. בנוסף, זה גם מקצר את זמן הרצת הבדיקות של האפליקציה, כי רדיס לא זקוק לסכימה כמו מאגרי נתונים אחרים. כך שהוא לא צריך זמן לאתחל את המאגר, לבנות את הסכימה, ועוד, לפני הרצת הבדיקות. אתה יכול להתחיל עם מאגר רדיס ריק בכל פעם וליצור נתונים עבור הבדיקות לפי הצורך. בדיקות מהירות יכולות באמת להגדיל את פריון הפיתוח שלך.
עמידות נתונים ברדיס
הבנו איך רדיס עובד וכל היתרונות שלו. אבל בשלב הזה, אתה עשוי לתהות: איך יכול מאגר נתונים בזיכרון לשמור נתונים? כי אם תהליך רדיס או השרת שבו רדיס פועל מתמוטט, כל הנתונים בזיכרון ייעלמו, נכון? ואם אני מאבד את הנתונים, איך אני יכול לשחזר אותם? אז בעצם, איך אני יכול להיות בטוח שהנתונים שלי בטוחים?
הדרך הפשוטה ביותר לעשות גיבויים לנתונים היא על ידי שכפול רדיס. אז, אם מופע המאסטר של רדיס מתמוטט, השכפולים עדיין יפעלו ויהיה להם את כל הנתונים. אם יש לך רדיס משוכפל, לשכפולים יהיו את הנתונים. אבל כמובן, אם כל מופעי רדיס מתמוטטים, תאבד את הנתונים כי לא יישאר שום שכפול.
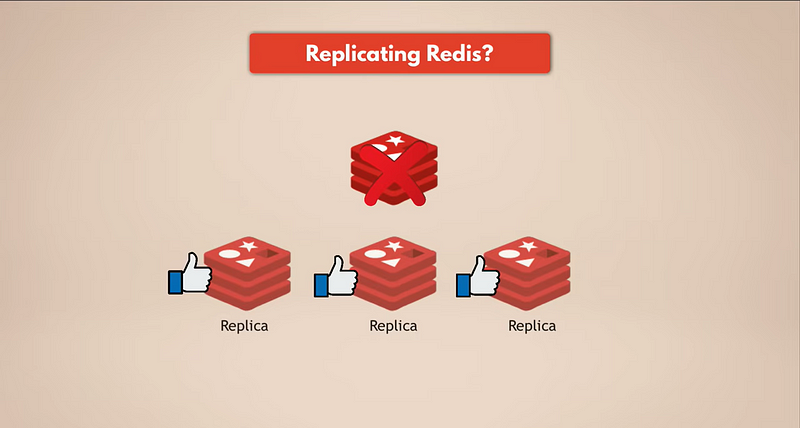
אנחנו צריכים עמידות אמיתית.
תמונה (RDB)
רדיס כולל מנגנונים מרובים לשמירת הנתונים ולשמירתם בצורה בטוחה. הראשון הוא צילומיות, שניתן להגדיר על פי זמן, מספר בקשות, וכדומה. צילומיות של הנתונים שלך תישמרנה על דיסק, שתוכל להשתמש בו לשחזור הנתונים שלך אם נתוני מסד הנתונים של רדיס נמחקים. אך שימו לב כי תאבדו את הדקות האחרונות של הנתונים, מכיוון שבדרך כלל עושים צילומיות כל חמש דקות או שעה, תלוי בצרכים שלך.
AOF (Append Only File)
כאלטרנטיבה, רדיס משתמש במשהו שנקרא AOF, שעל משמעו קובץ רק להוספה. במקרה זה, כל שינוי נשמר לדיסק לצורך עמידות באופן רציף. כאשר מאתחלים מחדש את רדיס או לאחר קריסה, רדיס ישדכך שוב את יומני קובץ ההוספה בכדי לבנות מחדש את המצב. לכן, AOF הוא יותר עמיד אך עשוי להיות איטי יותר מצילומיות.
שילוב של צילומיות ו-AOF
וכמובן, ניתן גם להשתמש בשילוב של שני הרעיונות, AOF וצילומיות, כאשר הקובץ להוספה בלבד משמיר נתונים מהזיכרון לדיסק באופן רציף, ובנוסף יש צילומיות רגילות בינתיים כדי לשמור את מצב הנתונים למקרה שצריך לשחזר אותם. זה אומר שאפילו אם מסד הנתונים של רדיס עצמו או השרתים, התשתית התחתונה בה רדיס פועל, כולם נופלים, עדיין תהיה לכם כל הנתונים שלכם בטוחים ותוכלו לשחזר ולהתחיל מחדש מסד נתונים חדש עם כל הנתונים.
איפה נמצא אחסון זה עמיד?
שאלה מעניינת מאוד היא, איפה נמצא אחסון זה? אז איפה נמצא הדיסק ששומר את הצילומיות ויומני קובץ ההוספה? האם הם נמצאים על אותם שרתים שבהם רדיס פועל?
השאלה הזו מובילה אותנו למגמה או לשיטת המיטב בניית מיקום נתונים בסביבות ענן, שתמיד עדיף להפריד בין השרתים שמפעילים את היישום ושירותי הנתונים מה-אחסון עמיק המאחסן את הנתונים שלך.
עם דוגמה ספציפית: אם היישומים והשירותים שלך פועלים בענן, נניח, על מכונת EC2 של AWS, עליך להשתמש ב-EBS או באחסון בלוקים גמיש כדי לשמור על נתונים שלך במקום לא לאחסן אותם על דיסק הקשיח של מכונת ה-EC2. מכיוון שאם מכונת ה-EC2 תכהה, לא תהיה לך גישה לאחד מהאחסון שלה, בין אם זה RAM או אחסון דיסק או מה שלא. לכן, אם ברצונך לקבל עמידות ואמינות לנתונים שלך, עליך לשים את הנתונים שלך מחוץ למכונות באחסון רשת חיצוני.
כתוצאה מכך, על ידי הפרדת שני אלה, אם מופע השרת נופל או אם כל המופעים נופלים, עדיין יש לך את הדיסק ואת כל הנתונים עליו שלא נפגעו. אתה פשוט מפעיל מופעים אחרים ומושך את הנתונים מה-EBS, וזהו. זה עושה את התשתיות שלך הרבה יותר קלות לניהול מכיוון שכל שרת שווה; אין לך שרתים מיוחדים עם נתונים או קבצים מיוחדים עליו. לכן אתה לא מדאיג אם אתה מאבד את כל התשתית שלך כי אתה יכול פשוט ליצור מחדש תשתית חדשה ולמשוך את הנתונים מאחסון נפרד, ואתה שוב מוכן להתקדם.
חוזרים לדוגמת ה-Redis, שירות ה-Redis יהיה פועל על השרתים וישתמש בRAM של השרת לאחסון הנתונים, בעוד שיומני הכתיבה המצמידים והצילומים הם שמירים על דיסק מחוץ לשרתים אלו, ומעניקים עמידות גבוהה יותר לנתונים שלך.
אופטימיזצית עלויות עם Redis on Flash
עכשיו שיש לנו את הידע שניתן לשמור נתונים ב-Redis לצורך עמידות ושחזור בעוד שמשתמשים בזיכרון RAM או באחסון בזיכרון לקבלת ביצועים גבוהים ומהירים. לכן, השאלה שעשויה לעלות כאן היא: האם שמירת נתונים בזיכרון היא יקרה? מכיוון שתצטרך יותר שרתים בהשוואה למסד נתונים ששומר נתונים על דיסק פשוט מאחר והזיכרון מוגבל בגודלו. יש מחיר לשלם ביחס לביצועים.
היטב, בעצם, ל-Redis יש דרך לאופטימיזציה זו באמצעות שירות בשם Redis on Flash, שהוא חלק מ-Redis Enterprise.
איך פועל Redis on Flash
זו רעיון פשוט מאוד, בעצם: Redis on Flash מרחיב את הזיכרון המהיר לכונן flash או SSD, שבו נשמרים ערכים שנמצאים בשימוש תדיר בזיכרון ואלה שאינם בשימוש תדיר נשמרים ב-SSD. לכן, עבור Redis, זהו פשוט זיכרון נוסף בשרת. זה אומר ש-Redis יכול להשתמש יותר בתשתית התחתונה או במשאבי השרת הבסיסיים על ידי שימוש בין זיכרון RAM וכונן SSD לשמירת הנתונים, הגדלת נפח האחסון בכל שרת, ובכך לחסוך לך עלויות תשתית.
סילוק של Redis: שפיצות וריפליקציה
דיברנו על אחסון הנתונים במסד הנתונים של Redis ואיך הכל עובד, כולל הנחיות המעשית הטובות. עכשיו נושא מעניין נוסף הוא כיצד אנו משתפים קבצי מסד נתונים ב-Redis?
ריפליקציה וזמינות גבוהה
נניח שהמופע של Redis שלי פוגע במצב של חסר זיכרון, ולכן גודל הנתונים גדול מדי להתמודדות בזיכרון, או ש-Redis מהווה נקודת בקבוק ואינו יכול להתמודד עם בקשות נוספות. במקרה כזה, איך אני מגביר את הקיבולת וגודל הזיכרון של בסיס הנתונים שלי ב-Redis?
יש לנו מספר אפשרויות לכך. למעשה, Redis תומך באשכול, כלומר תוכל להפעיל ראשי או מאסטר של Redis שיכול לשמש לקריאה וכתיבת נתונים, ולך תוכל להפעיל מספר רב של עותקים של אותו מאסטר לצורך קריאת הנתונים. בכך תוכל להרחיב את Redis כדי לטפל בבקשות רבות יותר ולהגביר את זמינות מסד הנתונים שלך. אם המאסטר נופל, אחד מהעותקים יכול לקחת את המקום שלו, ומסד הנתונים שלך ב-Redis ימשיך לפעול ללא בעיות.
כל העותקים הללו יחזיקו עותקים של הנתונים של המאסטר. אז, עם יותר עותקים, תצטרך יותר שטח זיכרון. ושרת אחד עשוי שלא להכיל מספיק זיכרון עבור כל העותקים שלך. בנוסף, אם כל העותקים על שרת אחד והשרת הזה נופל, כל בסיס הנתונים שלך ב-Redis יאבד, ויהיה לך זמן ריק. במקום זאת, תרצה להפיץ את העותקים הללו בקרב מספר רב של צמתים או שרתים. לדוגמה, המאסטר יהיה על צומת אחת ושני עותקים על שתי הצמתים האחרות.
שיבוץ עבור מערכות נתונים גדולות יותר
טוב, זה נראה מספיק טוב, אבל מה אם סט הנתונים שלך גדל מדי כדי להתאים בזיכרון של שרת אחד? בנוסף, כבר הרחבנו את הקריאות בבסיס הנתונים, כך שכל הבקשות בעצם רק משאירות שאילתה על הנתונים, אבל המאסטר שלנו עדיין בודד ועדיין עליו לטפל בכל הכתיבות. אז, מה הפתרון כאן?

עבור כך, אנו משתמשים במושג sharding, שהוא מושג כללי במסדי נתונים ושגם Redis תומך בו. Sharding בסך הכול אומר שאתה מפריד את קבוצת הנתונים המלאה שלך לחתיכות קטנות יותר או תת-קבוצות של נתונים, כאשר כל חתיכה אחראית על תת-קבוצת הנתונים שלה.
זה אומר שבמקום להיות לך פקיד ראשי אחד שמטפל בכל הכתיבות לקבוצת הנתונים המלאה; אתה יכול לחלק אותה, נגיד, לארבע חתיכות, כאשר כל אחת מהן אחראית על קריאות וכתיבות לתת-קבוצת הנתונים. כל חתיכה גם צריכה פחות קיבולת זיכרון מכיוון שהיא פשוט עם רבע מהנתונים. זה אומר שניתן להפיץ ולהריץ חתיכות על צמתים קטנים יותר ובגדול לסקל את האשכול שלך באופן אופקי. וכמובן, ככל שקבוצת הנתונים שלך גדלה וככל שנדרשות עוד משאבים, ניתן לעשות רישרד למסד הנתונים שלך ב-Redis, שגם זה אומר שאתה פשוט מפצל את הנתונים שלך לחתיכות קטנות יותר ויוצר עוד חתיכות.

לכן, ביצועים גבוהים מאוד, בסטיל גבוה, ואשכול של Redis שמריץ מספר צמתים המריצים מספר רפליקות של Redis, שכולן משורדות, נותן לך מסד נתונים שיכול לטפל במספר בקשות רבות יותר מבלי ליצור נקודות צמיחה.
כעת, אני צריך לציין כאן שהגדרה זו מעולה, אך עליך לנהל אותה בעצמך, לבצע את ההרחבה, להוסיף צמתים, לבצע את השרדינג, ואז רישרדינג וכו'. עבור חלק מהצוותים שמתמקדים יותר בפיתוח אפליקציות ובלוגיקה עסקית יותר מאשר בהפעלה ותחזוקת שירותי נתונים, זה יכול להיות מאמץ לא רצוי. לכן, כאלטרנטיבה קלה יותר, ב-Redis Enterprise, אתה מקבל סוג כזה של הגדרה באופן אוטומטי מכיוון שההרחבה, השרדינג וכו' ניהלים עבורך.
שיתוף עולמי עם Redis: פריסת Active-Active
בואו נשקול תרחיש נוסף מעניין ליישומים שזקוקים לזמינות גבוהה וביצועים משופרים במיקומים גיאוגרפיים מרובים. אז נניח שיש לנו אשכול מסד נתונים Redis משוכפל, משותף באזור אחד, במרכז המידע של לונדון, אירופה. אך יש לנו שני תרחישים הבאים:
- המשתמשים שלנו מתפלגים גיאוגרפית, ולכן הם גושים אל היישום מכל רחבי העולם. אנו רוצים להפיץ את היישום ושירותי הנתונים שלנו ברמה גלובלית, קרוב למשתמשים, כדי לספק למשתמשים שלנו ביצועים טובים יותר.
- אם מרכז המידע המלא בלונדון, אירופה, למשל, ייפל, אנו רוצים החלפה מיידית למרכז מידע אחר כך שהשירות של Redis יישאר זמין. במילים אחרות, אנו רוצים רפליקות של כל האשכול של Redis במרכזי מידע במיקומים גיאוגרפיים או אזורים מרובים.
אשכולי Redis מרובים במרכזים מרובים
משמע כי נתונים יחידים ישתפפו במספר אשכולות המופצים במרכזי מיקומים מרובים, עם כל אשכול מסוגל לקבל קריאות וכתיבות. במקרה כזה, תהיה לכם מספר אשכולי Redis שיפעלו כמופעי Redis מקומיים בכל אזור, והנתונים יסונכרנו בין האשכולות המפוזרים גיאוגרפית. זהו תכונה הזמינה ב- Redis Enterprise ונקראת מימוש פעיל-פעיל מאחר שיש לכם מסדי נתונים פעילים מרובים במיקומים שונים.

עם ההגדרה הזו, נקבל לטנט למטה עבור המשתמשים. ואפילו אם מסד הנתונים של Redis באזור אחד ייפל לחלוטין, האזורים האחרים לא ייפגעו. אם החיבור או הסנכרון בין האזורים נותקים לזמן קצר בגלל בעיה רשת כלשהי, לדוגמה, אשכולות ה-Redis באלה האזורים יכולים לעדכן את הנתונים באופן עצמאי, ופעם שהחיבור מתייצב, הם יכולים לסנכרן שוב את השינויים האלה.
פתרון סכסוכים עם CRDTs
עכשיו, כמובן, כשאתה שומע את זה, השאלה הראשונה שעשויה לעלות בדעתך היא: איך Redis פותר את השינויים במרחבים מרובים לאותו סט נתונים? אז, אם אותם נתונים משתנים במרחבים מרובים, איך Redis מבטיח ששינויי הנתונים של כל אזור לא יאבדו והנתונים מסונכרנים בצורה נכונה, ואיך הוא מבטיח עדכניות של הנתונים?
במיוחד, Redis Enterprise משתמש במושג הנקרא CRDTs, שעומד על conflict-free replicated Data types, ומושג זה משמש לפתור סכסוכים באופן אוטומטי ברמת מסד הנתונים וללא אובדן נתונים. כך שבגדר כללית, ב-Redis יש מנגנון למיזוג השינויים שנעשו לאותו סט נתונים ממקורות מרובים בדרך שאף אחד משינויי הנתונים לא יאבדו וכל הסכסוכים מטופלים כראוי. ומאחר שכפי שלמדת, Redis תומך בסוגי נתונים מרובים, כל סוג נתונים משתמש בכללים משלו לפתרון סכסוכי נתונים, שהם הכי אופטימליים לאותו סוג נתונים ספציפי.

בצורה פשוטה, במקום להחליף רק את השינויים של מקור אחד ולזרוק את כל האחרים, כל השינויים המקבילים נשמרים ומטופלים באופן חכם. שוב, זה נעשה אוטומטית עבורך עם תכונת השיבוץ הגיאוגרפי הפעיל-פעיל, כך שאין צורך לדאוג לכך.
הפעלת Redis ב-Kubernetes
והנושא האחרון שאני רוצה לטפל בו עם Redis הוא הפעלת Redis ב-Kubernetes. כפי שאמרתי, Redis הוא בר-תאים נהדר עבור שירותי מיקרו מורכבים שצריכים לתמוך במספר סוגי נתונים ושצריכים סולם קל של בסיס נתונים בלי לדאוג לאינטגרציה של הנתונים. וכן גם ידוע שהסטנדרט החדש להפעלת שירותי מיקרו הוא פלטפורמת Kubernetes. לכן, הפעלת Redis ב-Kubernetes היא מקרה שימוש מעניין מאוד ונפוץ. אז איך זה עובד?

Redis פתוח המקור על Kubernetes
עם Redis פתוח המקור, אפשר להפעיל את Redis המשוכפל כתרזה של Helm או קבצי תצורת Kubernetes ובגדר בסיס, באמצעות כללי השכפול והגידול שכבר דיברנו עליהם, להגדיר ולהפעיל מסד נתונים של Redis בעל זמינות גבוהה. ההבדל היחידי הוא שהמארחים שבהם ירוץ Redis יהיו כמו קפוסולות Kubernetes במקום, לדוגמה, מקראות EC2 או כל שרת פיזי או וירטואלי אחר. אבל אותם מושגים של שיתוף עומס, שכפול וגידול חלים גם כאן כאשר ברצונך להפעיל אשכול Redis ב-Kubernetes, ובעצם תצטרך לנהל את ההגדרה הזו בעצמך.
אופרטור Redis Enterprise
אך, כפי שציינתי, רבות מהקבוצות לא רוצות להשקיע את המאמץ לתחזק את שירותי הצד השלישי הללו מאחר והן מעדיפות להשקיע את הזמן והמשאבים שלהן בפיתוח אפליקציות או במשימות אחרות. לכן, חשוב גם כאן לקיים אלטרנטיבה קלה יותר. Redis Enterprise כולל אשף Redis מנוהל, אותו תוכל להשקיע כאופרטור Kubernetes.

אם אינך מכיר מהם, אופרטור ב-Kubernetes בגדר המושג המאפשר לארוז את כל המשאבים הנחוצים להפעלת אפליקציה או שירות מסוים כך שלא תצטרך לנהל אותו בעצמך או להפעיל אותו בעצמך. במקום שאדם יפעיל בעצמו מסד נתונים, בגדלים כמותיים יש לך את כל הלוגיקה הזו בצורה אוטומטית לפעול את מסד הנתונים עבורך. הרבה מסדי נתונים כוללים אופרטורים עבור Kubernetes, ולכל אופרטור כזה יש, כמובן, לוגיקה משלו בהתאם למי כתב אותם ואיך כתב אותם.
האופרטור Redis Enterprise על Kubernetes מאופטימל אוטומטית את ההפצה והתצורה של כל מסד הנתונים Redis בקרבת האשף שלך ב-Kubernetes. הוא גם דואג לגיוון, לביצוע גיבויים ולשחזור מסד הנתונים Redis אם נדרש, וכדומה. לכן, הוא משמור על הפעולה המלאה של מסד הנתונים Redis בתוך האשף של Kubernetes.
מסקנה
אני מקווה שלמדת הרבה בבלוג זה ושהצלחתי לענות על רוב שאלותיך. אם ברצונך ללמוד טכנולוגיות וקונספטים דומים נוספים, ודא שאתה עוקב אחריי מכיוון שאני כותב בלוגים באופן קבוע על AI, DevOps וטכנולוגיות ענן.
גם, תגיבו למטה אם יש לכם שאלות כלשהן בנוגע ל-Redis או להצעות לנושאים חדשים. ועם זאת, תודה רבה על הקריאה, ונתראה בבלוג הבא.
בואו נתחבר ב־LinkedIn!
Source:
https://dzone.com/articles/redis-as-a-primary-database-for-complex-applications