













Primero, veremos qué es Redis y su uso, así como por qué es adecuado para las modernas aplicaciones de microservicios complejos. Hablaremos de cómo Redis soporta el almacenamiento de múltiples formatos de datos para diferentes propósitos a través de sus módulos. A continuación, veremos cómo Redis, como base de datos en memoria, puede persistir datos y recuperarse de pérdidas de datos. También hablaremos de cómo Redis optimiza los costos de almacenamiento en memoria utilizando Redis en Flash.
Luego, veremos casos de uso muy interesantes de escalado de Redis y su replicación en múltiples regiones geográficas. Finalmente, dado que una de las plataformas más populares para ejecutar microservicios es Kubernetes, y dado que ejecutar aplicaciones con estado en Kubernetes es un poco desafiante, veremos cómo puedes ejecutar Redis fácilmente en Kubernetes.
¿Qué es Redis?
Redis, que en realidad significa Servidor de Diccionario Remoto, es una base de datos en memoria. Muchas personas lo han utilizado como caché encima de otras bases de datos para mejorar el rendimiento de la aplicación. Sin embargo, lo que muchas personas no saben es que Redis es una base de datos primaria completamente desarrollada que se puede utilizar para almacenar y persistir múltiples formatos de datos para aplicaciones complejas.
Ejemplo de Aplicación de Red Social Compleja
Veamos una configuración común para una aplicación de microservicios. Supongamos que tenemos una compleja aplicación de redes sociales con millones de usuarios. Y digamos que nuestra aplicación de microservicios utiliza una base de datos relacional como MySQL para almacenar los datos. Además, dado que estamos recopilando toneladas de datos diariamente, tenemos una base de datos de Elasticsearch para filtrar y buscar datos rápidamente.
Ahora, los usuarios están todos conectados entre sí, por lo que necesitamos una base de datos de grafos para representar estas conexiones. Además, nuestra aplicación tiene mucho contenido multimedia que los usuarios comparten entre sí diariamente, y para eso, tenemos una base de datos de documentos. Finalmente, para un mejor rendimiento de la aplicación, tenemos un servicio de caché que almacena en caché los datos de otras bases de datos y los hace accesibles más rápido.
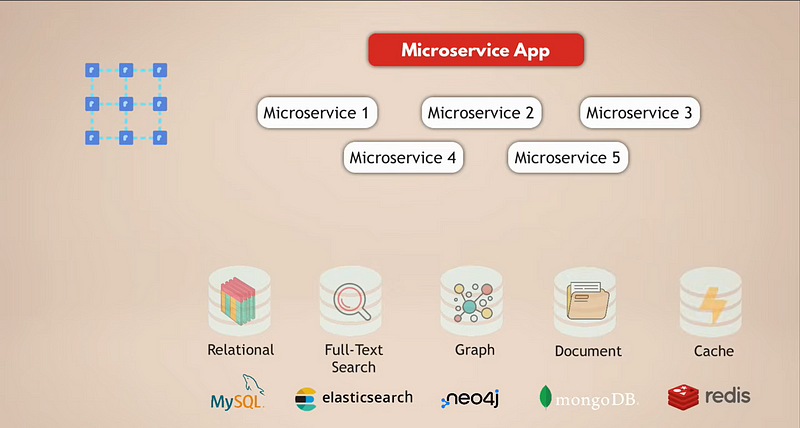
Ahora, es obvio que esta es una configuración bastante compleja. Veamos cuáles son los desafíos de esta configuración:
1. Despliegue y Mantenimiento
Todos estos servicios de datos necesitan ser desplegados, ejecutados y mantenidos. Esto significa que tu equipo necesita tener algún tipo de conocimiento sobre cómo operar todos estos servicios de datos.
2. Escalado y Requisitos de Infraestructura
Para alta disponibilidad y mejor rendimiento, querrás escalar tus servicios. Cada uno de estos servicios de datos se escala de manera diferente y tiene diferentes requisitos de infraestructura, lo que podría ser un desafío adicional. Así que, en general, usar múltiples servicios de datos para tu aplicación aumenta el esfuerzo de mantener toda la configuración de tu aplicación.
3. Costos de Nube
Por supuesto, como una alternativa más fácil para ejecutar y gestionar los servicios tú mismo, puedes utilizar los servicios de datos gestionados de los proveedores en la nube. Pero esto podría ser muy costoso porque, en las plataformas en la nube, pagas por cada servicio de datos gestionado por separado.
4. Complejidad de Desarrollo
5. Mayor Latencia
Por qué Redis Simplifica Esta Complejidad
En comparación con una base de datos multimodal como Redis, resuelves la mayoría de estos desafíos:
- Servicio de datos único. Corres y mantienes solo un servicio de datos. Por lo tanto, tu aplicación también necesita comunicarse con una única base de datos, lo que significa solo una interfaz programática para ese servicio de datos.
- Latencia reducida. La latencia se reduce yendo a un único punto de datos y eliminando varios saltos de red internos.
- Múltiples tipos de datos en uno. Tener una base de datos como Redis que te permite almacenar diferentes tipos de datos (es decir, múltiples tipos de bases de datos en una) así como actuar como caché resuelve tales desafíos.
Cómo Redis Admite Múltiples Formatos de Datos
Entonces, veamos cómo funciona Redis en realidad. En primer lugar, ¿cómo admite Redis múltiples formatos de datos en una sola base de datos?
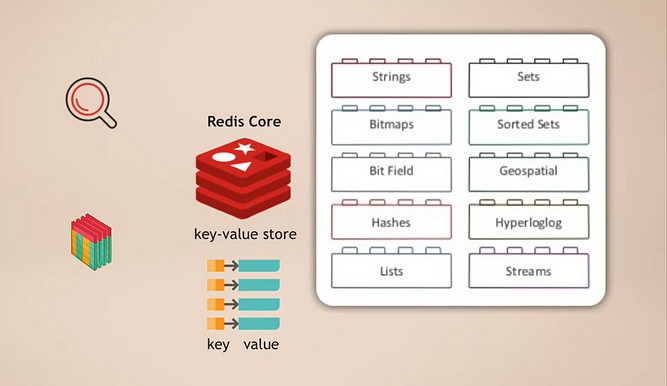
Núcleo de Redis y Módulos
La forma en que funciona es que tienes Redis core, que es un almacén de clave-valor que ya admite el almacenamiento de múltiples tipos de datos. Luego, puedes extender ese núcleo con lo que se llama módulos para diferentes tipos de datos, que tu aplicación necesita para diferentes propósitos. Por ejemplo:
- RedisSearch para funcionalidad de búsqueda (como Elasticsearch)
- RedisGraph para almacenamiento de datos en grafos
Algo genial de esto es que es modular. Estos diferentes tipos de funcionalidades de base de datos no están integrados de forma rígida en una sola base de datos como en muchas otras bases de datos multimodales, sino que puedes elegir exactamente qué funcionalidad de servicio de datos necesitas para tu aplicación y luego, básicamente, agregar ese módulo.
Cache Incorporado
Y, por supuesto, cuando usas Redis como base de datos principal, nonecesitas un cache adicional porque lo tienes automáticamente desde el principio con Redis. Eso significa, nuevamente, menos complejidad en tu aplicación porque no necesitas implementar la lógica para gestionar, poblar e invalidar el cache.
Alto Rendimiento y Pruebas Más Rápidas
Finalmente, como base de datos en memoria, Redis es muy rápido y eficiente, lo que, por supuesto, hace que la aplicación en sí sea más rápida. Además, también hace que la ejecución de las pruebas de la aplicación sea mucho más rápida, ya que Redis no necesita un esquema como otras bases de datos. Por lo tanto, no necesita tiempo para inicializar la base de datos, construir el esquema, y así sucesivamente antes de ejecutar las pruebas. Puedes empezar con una base de datos Redis vacía cada vez y generar datos para las pruebas según sea necesario. Las pruebas rápidas realmente pueden aumentar tu productividad en el desarrollo.
Persistencia de datos en Redis
Hemos entendido cómo funciona Redis y todos sus beneficios. Pero en este punto, es posible que te estés preguntando: ¿Cómo puede una base de datos en memoria persistir los datos? Porque si el proceso de Redis o el servidor en el que se está ejecutando Redis falla, ¿todos los datos en memoria desaparecen, verdad? Y si pierdo los datos, ¿cómo puedo recuperarlos? Básicamente, ¿cómo puedo estar seguro de que mis datos están seguros?
La forma más sencilla de tener copias de seguridad de datos es replicando Redis. Entonces, si la instancia maestra de Redis falla, las réplicas seguirán funcionando y tendrán todos los datos. Si tienes un Redis replicado, las réplicas tendrán los datos. Pero, por supuesto, si todas las instancias de Redis fallan, perderás los datos porque no quedará ninguna réplica.
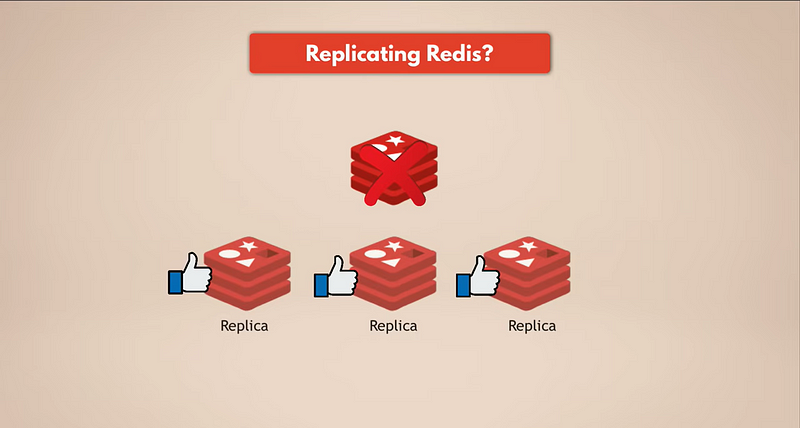
Necesitamos una persistencia real.
Instantánea (RDB)
Redis tiene múltiples mecanismos para persistir los datos y mantenerlos seguros. El primero es instantáneas, que puedes configurar en función del tiempo, el número de solicitudes, etc. Las instantáneas de tus datos se almacenarán en un disco, que puedes utilizar para recuperar tus datos si toda la base de datos de Redis desaparece. Pero ten en cuenta que perderás los últimos minutos de datos, porque generalmente haces instantáneas cada cinco minutos o una hora, dependiendo de tus necesidades.
AOF (Archivo Solo de Adición)
Como alternativa, Redis utiliza algo llamado AOF, que significa Archivo Solo de Adición. En este caso, cada cambio se guarda en el disco para la persistencia de manera continua. Al reiniciar Redis o después de un corte, Redis reproducirá los registros del Archivo Solo de Adición para reconstruir el estado. Así que, AOF es más duradero pero puede ser más lento que hacer instantáneas.
Combinación de Instantáneas y AOF
Y, por supuesto, también puedes usar una combinación de ambos, AOF e instantáneas, donde el archivo solo de adición está persistiendo datos de la memoria al disco de manera continua, además de que tienes instantáneas regulares entre medio para guardar el estado de los datos en caso de que necesites recuperarlo. Esto significa que incluso si la base de datos de Redis en sí o los servidores, la infraestructura subyacente donde se ejecuta Redis, fallan, aún tienes todos tus datos seguros y puedes recrear y reiniciar fácilmente una nueva base de datos de Redis con todos los datos.
¿Dónde Está Este Almacenamiento Persistente?
Una pregunta muy interesante es, ¿dónde está ese almacenamiento persistente? Entonces, ¿dónde está ese disco que contiene tus instantáneas y los registros del archivo solo de adición? ¿Están en los mismos servidores donde se está ejecutando Redis?
Esta pregunta nos lleva en realidad a la tendencia o mejor práctica de la persistencia de datos en entornos de nube, que es que siempre es mejor separar los servidores que ejecutan su aplicación y servicios de datos del almacenamiento persistente que almacena sus datos.
Con un ejemplo específico: Si sus aplicaciones y servicios se ejecutan en la nube en, digamos, una instancia de AWS EC2, debe usar EBS o Elastic Block Storage para persistir sus datos en lugar de almacenarlos en el disco duro de la instancia EC2. Porque si esa instancia EC2 falla, no tendrá acceso a ninguno de su almacenamiento, ya sea RAM, almacenamiento en disco o lo que sea. Así que, si desea persistencia y durabilidad para sus datos, debe colocar sus datos fuera de las instancias en un almacenamiento en red externo.
Como resultado, al separar estos dos, si la instancia del servidor falla o si todas las instancias fallan, todavía tiene el disco y todos los datos en él intactos. Simplemente inicia otras instancias y toma los datos del EBS, y eso es todo. Esto hace que su infraestructura sea mucho más fácil de gestionar porque cada servidor es igual; no tiene servidores especiales con datos o archivos especiales. Así que no le importa si pierde toda su infraestructura porque puede recrear una nueva y extraer los datos de un almacenamiento separado, y estará listo para continuar.
Volviendo al ejemplo de Redis, el servicio de Redis se ejecutará en los servidores y utilizará la RAM del servidor para almacenar los datos, mientras que los archivos de registro de solo anexar y los instantáneas se persistirán en un disco fuera de esos servidores, haciendo que sus datos sean más duraderos.
Optimización de costos con Redis en Flash
Ahora sabemos que se puede persistir datos con Redis para durabilidad y recuperación mientras se utiliza RAM o almacenamiento en memoria para obtener un rendimiento y velocidad óptimos. Entonces, la pregunta que puede surgir es: ¿No es costoso almacenar datos en memoria? Porque necesitarías más servidores en comparación con una base de datos que almacena datos en disco, simplemente porque la memoria es limitada en tamaño. Hay un equilibrio entre el costo y el rendimiento.
Bueno, en realidad Redis tiene una forma de optimizar esto utilizando un servicio llamado Redis en Flash, que es parte de Redis Enterprise.
Cómo funciona Redis en Flash
Es un concepto bastante simple, de hecho: Redis en Flash extiende la RAM al disco flash o SSD, donde los valores utilizados con frecuencia se almacenan en RAM y los menos utilizados se almacenan en SSD. Entonces, para Redis, es simplemente más RAM en el servidor. Esto significa que Redis puede utilizar más de la infraestructura subyacente o de los recursos del servidor subyacente al utilizar tanto RAM como la unidad SSD para almacenar los datos, aumentando la capacidad de almacenamiento en cada servidor, y de esta manera ahorrándote costos de infraestructura.
Escalar Redis: Replicación y Fragmentación
Hemos hablado sobre el almacenamiento de datos para la base de datos Redis y cómo todo funciona, incluidas las mejores prácticas. Ahora, otro tema muy interesante es ¿cómo escalamos una base de datos Redis?
Replicación y Alta Disponibilidad
Supongamos que mi instancia de Redis se queda sin memoria, por lo que los datos son demasiado grandes para almacenar en memoria, o Redis se convierte en un cuello de botella y no puede manejar más solicitudes. En tal caso, ¿cómo aumento la capacidad y el tamaño de memoria de mi base de datos Redis?
Tenemos varias opciones para eso. En primer lugar, Redis soporta el clustering, lo que significa que puedes tener una instancia principal o maestra de Redis que puede ser utilizada para leer y escribir datos, y puedes tener múltiples réplicas de esa instancia principal para leer los datos. De esta manera, puedes escalar Redis para manejar más peticiones y, además, aumentar la alta disponibilidad de tu base de datos. Si el maestro falla, una de las réplicas puede hacerse cargo, y tu base de datos de Redis puede continuar funcionando básicamente sin problemas.
Estas réplicas contendrán copias de los datos de la instancia principal. Por lo tanto, cuantas más réplicas tengas, más espacio de memoria necesitarás. Y un solo servidor puede que no tenga suficiente memoria para todas tus réplicas. Además, si tienes todas las réplicas en un solo servidor y ese servidor falla, toda tu base de datos de Redis se perderá y tendrás tiempo de inactividad. En cambio, quieres distribuir estas réplicas entre múltiples nodos o servidores. Por ejemplo, tu instancia maestra estará en un nodo y dos réplicas en los otros dos nodos.
Fragmentación para conjuntos de datos más grandes
Bueno, eso parece bastante bueno, pero ¿qué pasa si tu conjunto de datos crece demasiado para caber en la memoria de un solo servidor? Además, hemos escalado las lecturas en la base de datos, por lo que todas las peticiones básicamente consultan los datos, pero nuestra instancia maestra sigue sola y aún tiene que manejar todas las escrituras. Entonces, ¿cuál es la solución aquí?

Para eso, utilizamos el concepto de sharding, que es un concepto general en bases de datos y que Redis también soporta. Sharding básicamente significa que tomas tu conjunto de datos completo y lo divides en partes más pequeñas o subconjuntos de datos, donde cada shard es responsable de su propio subconjunto de datos.
Esto significa que en lugar de tener una instancia maestra que maneje todas las escrituras en el conjunto de datos completo; puedes dividirlo en, digamos, cuatro shards, cada uno de ellos responsable de lecturas y escrituras en un subconjunto de los datos. Cada shard también necesita menos capacidad de memoria porque solo tiene una cuarta parte de los datos. Esto significa que puedes distribuir y ejecutar shards en nodos más pequeños y, básicamente, escalar tu clúster horizontalmente. Y, por supuesto, a medida que tu conjunto de datos crece y a medida que necesitas aún más recursos, puedes volver a hacer sharding en tu base de datos Redis, lo que básicamente significa que solo divides tus datos en partes aún más pequeñas y creas más shards.

Así que tener múltiples nodos que ejecutan múltiples réplicas de Redis, que están todos shardados, te brinda una base de datos Redis muy eficiente y altamente disponible que puede manejar muchas más solicitudes sin crear cuellos de botella.
Ahora, tengo que señalar aquí que esta configuración es excelente, pero necesitarías gestionarla tú mismo, hacer la escalabilidad, agregar nodos, hacer el sharding y luego el re-sharding, etc. Para algunos equipos que están más enfocados en el desarrollo de aplicaciones y más lógica de negocio en lugar de ejecutar y mantener servicios de datos, esto podría ser un esfuerzo no deseado. Así que, como una alternativa más fácil, en Redis Enterprise, obtienes este tipo de configuración automáticamente porque la escalabilidad, el sharding, y así sucesivamente, son todos gestionados por ti.
Replicación Global con Redis: Despliegue Activo-Activo
Consideremos otro escenario interesante para aplicaciones que necesitan aún mayor disponibilidad y rendimiento en múltiples ubicaciones geográficas. Digamos que tenemos un clúster de base de datos Redis replicado y particionado en una región, en el centro de datos de Londres, Europa. Pero tenemos los dos siguientes casos de uso:
- Nuestros usuarios están distribuidos geográficamente, por lo que acceden a la aplicación desde todo el mundo. Queremos distribuir nuestros servicios de aplicación y datos a nivel mundial, cerca de los usuarios, para brindarles un mejor rendimiento.
- Si el centro de datos completo en Londres, Europa, por ejemplo, se cae, queremos un cambio inmediato a otro centro de datos para que el servicio de Redis siga disponible. En otras palabras, queremos réplicas de todo el clúster de Redis en centros de datos en múltiples ubicaciones geográficas o regiones.
Múltiples Clústeres de Redis en Varios Regiones
Esto significa que un solo dato debería ser replicado en muchos clústeres distribuidos en múltiples regiones, con cada clúster siendo completamente capaz de aceptar lecturas y escrituras. En ese caso, tendrías múltiples clústeres de Redis que actuarán como instancias locales de Redis en cada región, y los datos se sincronizarán en estos clústeres distribuidos geográficamente. Esta es una característica disponible en Redis Enterprise y se llama implementación activa-activa porque tienes múltiples bases de datos activas en diferentes ubicaciones.

Con esta configuración, tendremos una latencia más baja para los usuarios. E incluso si la base de datos Redis en una región se cae por completo, las otras regiones no se verán afectadas. Si la conexión o sincronización entre las regiones se interrumpe durante un corto tiempo debido a algún problema de red, por ejemplo, los clústeres de Redis en estas regiones pueden actualizar los datos de forma independiente, y una vez que se restablezca la conexión, pueden sincronizar esos cambios nuevamente.
Resolución de conflictos con CRDTs
Ahora, por supuesto, cuando escuchas eso, la primera pregunta que puede surgir en tu mente es: ¿Cómo resuelve Redis los cambios en múltiples regiones al mismo conjunto de datos? Entonces, si los mismos datos cambian en múltiples regiones, ¿cómo se asegura Redis de que los cambios de datos de ninguna región se pierdan y los datos se sincronicen correctamente, y cómo garantiza la consistencia de los datos?
Específicamente, Redis Enterprise utiliza un concepto llamado CRDTs, que significa tipos de datos replicados sin conflictos, y este concepto se utiliza para resolver conflictos automáticamente a nivel de base de datos y sin pérdida de datos. Básicamente, Redis en sí tiene un mecanismo para fusionar los cambios que se hicieron en el mismo conjunto de datos desde múltiples fuentes de manera que ninguno de los cambios de datos se pierda y cualquier conflicto se resuelva adecuadamente. Y dado que, como aprendiste, Redis admite múltiples tipos de datos, cada tipo de dato utiliza sus propias reglas de resolución de conflictos de datos, que son las más óptimas para ese tipo de dato específico.

En pocas palabras, en lugar de simplemente anular los cambios de una fuente y descartar todos los demás, se mantienen todos los cambios paralelos y se resuelven de manera inteligente. Nuevamente, esto se hace automáticamente por usted con esta función de geo-replicación activa-activa, por lo que no necesita preocuparse por eso.
Ejecutando Redis en Kubernetes
Y el último tema que quiero abordar con Redis es ejecutar Redis en Kubernetes. Como dije, Redis es una excelente opción para microservicios complejos que necesitan soportar múltiples tipos de datos y que requieren una fácil escalabilidad de una base de datos sin preocuparse por la consistencia de los datos. Y también sabemos que el nuevo estándar para ejecutar microservicios es la plataforma Kubernetes. Por lo tanto, ejecutar Redis en Kubernetes es un caso de uso muy interesante y común. Entonces, ¿cómo funciona eso?

Redis de código abierto en Kubernetes
Con Redis de código abierto, puede implementar Redis replicado como un gráfico de Helm o archivos de manifiesto de Kubernetes y, básicamente, utilizando las reglas de replicación y escalado de las que ya hablamos, configurar y ejecutar una base de datos Redis altamente disponible. La única diferencia sería que los hosts donde se ejecutará Redis serán pods de Kubernetes en lugar de, por ejemplo, instancias de EC2 o cualquier otro servidor físico o virtual. Pero los mismos conceptos de fragmentación, replicación y escalado se aplican aquí también cuando desea ejecutar un clúster de Redis en Kubernetes, y básicamente tendría que gestionar esa configuración usted mismo.
Operador de Redis Enterprise
Sin embargo, como mencioné, muchos equipos no quieren hacer el esfuerzo de mantener estos servicios de terceros porque preferirían invertir su tiempo y recursos en el desarrollo de aplicaciones u otras tareas. Por lo tanto, tener una alternativa más fácil también es importante aquí. Redis Enterprise tiene un clúster de Redis administrado, que se puede implementar como un operador de Kubernetes.

Si no conoces los operadores, un operador en Kubernetes es básicamente un concepto donde puedes empaquetar todos los recursos necesarios para operar una determinada aplicación o servicio para que no tengas que administrarlo tú mismo. En lugar de que un humano opere una base de datos, básicamente tienes toda esta lógica de forma automatizada para operar una base de datos por ti. Muchas bases de datos tienen operadores para Kubernetes, y cada operador tiene, por supuesto, su propia lógica basada en quién los escribió y cómo los escribió.
El operador de Redis Enterprise en Kubernetes automatiza específicamente la implementación y configuración de toda la base de datos de Redis en tu clúster de Kubernetes. También se encarga de escalar, realizar copias de seguridad y recuperar el clúster de Redis si es necesario, etc. Por lo tanto, se hace cargo de la operación completa del clúster de Redis dentro del clúster de Kubernetes.
Conclusión
Espero que hayas aprendido mucho en este blog y que haya podido responder muchas de tus preguntas. Si deseas aprender más sobre tecnologías y conceptos similares, asegúrate de seguirme porque escribo blogs regularmente sobre IA, DevOps y tecnologías en la nube.
También, comenta abajo si tienes alguna pregunta sobre Redis o alguna sugerencia de nuevo tema. Y con eso, gracias por leer y nos vemos en el próximo blog.
¡Conéctemos en LinkedIn!
Source:
https://dzone.com/articles/redis-as-a-primary-database-for-complex-applications