













Введение
Здравствуйте, читатели! Это еще один пост из серии, которую мы делаем о PyTorch. Этот пост направлен на пользователей PyTorch, которые знакомы с базовыми аспектами PyTorch и хотят продолжить до уровня intermediate. хотя мы уже рассмотрели, как реализовать базовый классификатор в предыдущем посте, в этом посте мы будем讨论, как реализовать более сложные функции глубокого обучения с использованием PyTorch. Some of the objectives of this posts are to make you understand.
- What is the difference between PyTorch classes like
nn.Module,nn.Functional,nn.Parameterand when to use which - How to customise your training options such as different learning rates for different layers, different learning rate schedules
- Custom Weight Initialisation
So, let’s get started.
nn.Module vs nn.Functional
This is something that comes quite a lot especially when you are reading open source code. In PyTorch, layers are often implemented as either one of torch.nn.Module objects or torch.nn.Functional functions. Which one to use? Which one is better?
Как мы рассмотрели в части 2, torch.nn.Module является базовым камнем PyTorch. Его работает следующим образом: вы first определяете объект nn.Module, а затем вызываете его метод forward, чтобы запустить его. Это Object Oriented способ делать вещи.
С другой стороны, nn.functional обеспечивает несколько слоёв / активаций в форме функций, которые можно вызвать непосредственно на входной данных, а не определяя объект. Например, чтобы пересчитать изображение тензором, вы вызываете torch.nn.functional.interpolate на тензоре изображения.
Так что как мы выбрать, что использовать? Когда слой / активация / потеря, которую мы реализуем, имеет потерю.
Понимание Stateful-ness
Обычно любой слой можно рассматривать как функцию. Например, операция конвульсионного слоя представляет собой только набор умножений и加法 операций. Так что этологично для нас реализовать ее как функцию? Но подождите, слой содержит веса, которые нужно сохранять и обновлять при обучении. Таким образом, с программной точки зрения, слой более чем только функция. Он также должен содержать данные, которые изменяются во время обучения нашей сети.
Я хочу, чтобы вы обратили особое внимание на тот факт, что данные, хранящиеся в конволюционной слое изменяются. Это означает, что слой имеет состояние, которое изменяется при обучении. Чтобы реализовать функцию, выполняющую операцию конволюции, нам также нужно определить структуру данных для хранения весов слоя отдельно от самой функции. Затем сделать эту внешнюю структуру данных входом в нашу функцию.
Или же, чтобы избегать хладнокровного труда, мы могли бы просто определить класс для хранения структуры данных и сделать операцию конволюции как членную функцию. Это действительно упростит нашу работу, так как мы не должны волноваться о статических переменных, существующих вне функции. В таких случаях мы предпочитаем использовать объекты nn.Module, где есть веса или другие состояния, которые могут определять поведение слоя. Например, слой dropout/Batch Norm ведет себя по-разному во время тренировки и вference.
С другой стороны, где не требуется состояние или веса, можно использовать nn.functional. Примеры включают изменение размера (nn.functional.interpolate), среднее пуление (nn.functional.AvgPool2d).
Несмотря на вышеуказанные причины, большинство классов nn.Module имеют свои соответствующие варианты nn.functional. However, the above line of reasoning is to be respected during practical work.
nn.Parameter
В PyTorch важный класс – это nn.Parameter, который, по моему удивлению, встречается редко в вводных текстах о PyTorch. рассмотрим следующий случай.
Каждый nn.Module имеет функцию parameters(), которая возвращает, так сказать, его обучаемые параметры. Мы должны неявно определить, что эти параметры являются. В определении nn.Conv2d, авторы PyTorch определили веса и смещения как параметры для этого слоя. Однако, заметим одно дело, что когда мы определили net, мы не обязательно должны были добавить parameters nn.Conv2d к parameters net. Это произошло неявно благодаря тому, что nn.Conv2d объект стал членом net объекта.
Это внутренне осуществляется с помощью класса nn.Parameter, который является подклассом Tensor. когда мы вызываем функцию parameters() объекта nn.Module, она возвращает все его члены, являющиеся объектами nn.Parameter.
Действительно, все тренировочные веса nn.Module классов реализованы как объекты nn.Parameter. Whenever, a nn.Module (nn.Conv2d in our case) is assigned as a member of another nn.Module, the “parameters” of the assignee object (i.e. the weights of nn.Conv2d) are also added the “parameters” of the object which is being assigned to (parameters of net object). This is called registering “parameters” of a nn.Module
Если вы попытаетесь назначить тензор nn.Module объекту, он не будет отображен в parameters(),除非 вы определите его как nn.Parameter объект. Это было сделано для упрощения сценариев, когда могут потребоваться кэшировать недифференцируемый тензор, например, в случае кэширования предыдущего выхода в случае RNN.
nn.ModuleList и nn.ParameterList()
Я помню, когда я использовал nn.ModuleList, когда я реализовал YOLO v3 в PyTorch. Я создавал сеть, исходя из текстового файла, который содержал архитектуру. Я сохранил все nn.Module объекты в Python-список и затем сделал список членом моего nn.Module объекта, представляющего сеть.
Чтобы упростить его, что-то вроде этого.
Как вы видите, в отличие от регистрации отдельных модулей, при назначении Python List не регистрируются параметры модулей внутри списка. чтобы исправить это, мы обертываем наш список в класс nn.ModuleList и затем назначаем его в качестве члена класса сети.
Также список тензоров может быть зарегистрирован, обертывая список внутри класса nn.ParameterList.
Инициализация весов
Инициализация весов может influенцовать результаты вашего обучения. Более того, вам может потребоваться различные схемы инициализации весов для различных типов слоев. Это может быть сделано с помощью функций modules и apply modules является member function класса nn.Module, который возвращает итератор, содержащий все member nn.Module объекты member objects одной nn.Module функции. затем использовать функцию apply может быть вызвана на каждом nn.Module, чтобы настроить его инициализацию.
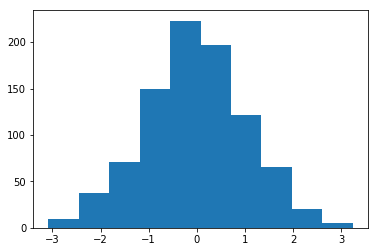
Histogram of weights initialised with Mean = 1 and Std = 1
В модуле torch..nn.init есть множество inplace инициализационных функций.
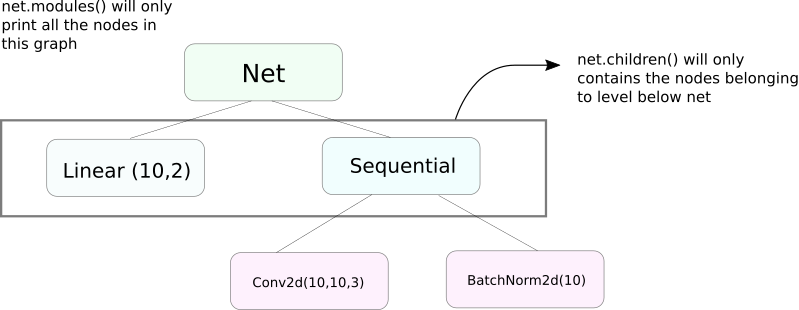
модули() против детей()
Очень схожая функция, как modules, это children. разница очень небольшая, но важная. Как мы знаем, объект nn.Module может содержать другие объекты nn.Module в качестве своих данных.
children() будет возвращать только список объектов nn.Module, которые являются данными членами объекта, на котором вызывается children.
С другой стороны, nn.Modules идет рекурсивно внутрь каждого объекта nn.Module, создавая список каждого объекта nn.Module, который встречается на пути, пока не останется больше объектов nn.module. заметим, что modules() также возвращает nn.Module, на котором оно было вызвано, как часть списка.
заметим, что вышеуказанное утверждение остается верным для всех объектов / классов, которые являются подклассами класса nn.Module.
Таким образом, когда мы инициализируем веса, мы можем пожелать использовать функцию modules(), так как мы не можем войти внутрь объекта nn.Sequential и инициализировать вес для его членов.
Печать информации о сети
Мы можем потребовать напечатать информацию о сети, будь то для пользователя или для debugging-целей. PyTorch предоставляет очень удобный способ напечатать много информации о нашей сети, используя его named_* функции. Есть 4 таких функции.
named_parameters. Возвращает итератор, который выдает кортеж, содержащий имя параметров (если конвенциональная convolutional layer определена какself.conv1, то ее параметры будутconv1.weightиconv1.bias) и значение, возвращаемое функцией__repr__классаnn.Parameter
2. named_modules.同一如上,但 итератор возвращает модули, как функция modules() делает.
3. named_children同一如上,但 итератор возвращает модули, как функция children() возвращает
4. named_buffers возвращает tensors буфера, такие как running mean средняяя величина a Batch Norm layer.
不同的学习率 для различных слоев
В этом разделе мы leaned, как использовать различные learning rates для наших различных слоев. Generally, мы будем охватить, как иметь различные hyperparameters для различных групп параметров, будь то различные learning rate для различных слоев или различные learning rate для постоянных и весов.
IDEA реализовать такое дело довольно проста. В нашем предыдущем посте мы реализовали классификатор CIFAR, и в этом месте мы проходили все параметры сети в целом через объект оптимизатора.
Тем не менее, класс torch.optim позволяет нам предоставлять различные наборы параметров с различными скоростями обучения в виде словаря.
В указанном выше сценарии параметры `fc1` используют скорость обучения 0.01 и момент устойчивости 0.99. Если для группы параметров не указан гиперпараметр (как `fc2`), они используют default значение этого гиперпараметра, переданное в качестве аргумента функции оптимизатора. Вы можете создавать списки параметров на основе различных слоев или того, является ли параметр весом или смещением, используя функцию named_parameters(), которую мы описали выше.
Планирование Скорости Обучения
Планирование скорости обучения, которое вы хотите следовать, является важным гиперпараметром, который вы хотите настроить. PyTorch обеспечивает поддержку для планирования скорости обучения через модуль torch.optim.lr_scheduler, который содержит различные расписания скорости обучения. В следующем примере показано такое их применение.
Планировщик, описанный выше, умножает Learning Rate на gamma каждый раз, когда мы достигаем эпох, определенных в списке milestones. В нашем случае Learning Rate умножается на 0.1 в n-й и 2n-й эпохах. Вы также должны написать строку scheduler.step в цикле вашего кода, который идет по эпохам, чтобы обновить Learning Rate.
В общем, цикл тренировки состоит из двух вложенных циклов, где один цикл идет по эпохам, а вложенный идет по batch’ам в текущей эпохе. Убедитесь, что вы вызываете scheduler.step в начале цикла по эпохам, чтобы ваш Learning Rate был обновлен. Будьте осторожны и не напишите это в цикле по batch’ам, иначе ваш Learning Rate может быть обновлен после 10-го batch’а, а не после n-й эпохи.
также помните, что scheduler.step не является заменой для optim.step и вы должны вызывать optim.step каждый раз, когда вы про propagate назад. (Это будет в “batch” цикле).
Сохранение вашей модели
Вы можете захотеть сохранить вашу модель для будущего использования в inference, или просто создать checkpoint для тренировки. Что касается сохранения моделей в PyTorch, у вас есть две опции.
Первая – использовать torch.save. Это эквивалентно сериализации всего объекта nn.Module с использованием Pickle. Это сохраняет всю модель на диск. Вы можете загрузить эту модель позже в память с помощью torch.load.
的上面的代码将保存整个模型以及权重和架构。如果您只需要保存权重,而不是保存整个模型,您可以只保存模型的state_dict。state_dict基本是一个字典,它将网络的nn.Parameter对象映射到它们的值。如上所示,我们可以将现有的state_dict加载到nn.Module对象中。请注意,这不会涉及到保存整个模型,只是参数。在加载state dict之前,您需要先创建具有层的网络。如果网络架构与保存state_dict时的架构不完全相同,PyTorch将会抛出错误。来自torch.optim的优化器对象也有一个state_dict对象,用于存储优化算法的超参数。它可以通过在优化器对象上调用load_state_dict以类似的方式进行保存和加载。
结论
这完成了我们关于PyTorch的一些更高级特性的讨论。我希望您在这篇文章中阅读到的内容将帮助您实现您可能已经想到的复杂深度学习想法。以下是供进一步学习的相关链接,如果您感兴趣的话。
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced