













Introduction
Bonjour lecteurs, voici encore un post dans une série sur PyTorch que nous avons commencé. Ce post est destiné aux utilisateurs de PyTorch qui sont familiarisés avec les bases de PyTorch et qui aimeraient passer au niveau intermédiaire. Bien que nous avons couvert comment implémenter un classificateur de base dans un post précédent, dans ce post, nous discuterons de la manière de mettre en œuvre des fonctionnalités plus complexes de apprentissage profondes en utilisant PyTorch. Certains des objectifs de ce post sont de vous faire comprendre.
- Quelles sont les différences entre les classes de PyTorch telles que
nn.Module,nn.Functional,nn.Parameteret quand utiliser chacune d’entre elles - Comment personnaliser vos options de formation, telles que des taux d’apprentissage différents pour différentes couches, des calendriers de taux d’apprentissage différents
- Initiation des poids personnalisée
Alors, commençons.
nn.Module vs nn.Functional
C’est une question qui revient souvent, en particulier lorsque vous lisez du code open source. Dans PyTorch, les couches sont souvent implémentées en tant qu’objets soit de torch.nn.Module ou en tant que fonctions de torch.nn.Functional. Quelle utiliser ? Quelle est la meilleure ?
Comme nous l’avons couvert dans la Partie 2, torch.nn.Module est essentiellement la pierre angulaire de PyTorch. La manière dont il fonctionne est de définir d’abord un objet nn.Module, puis d’appeler sa méthode forward pour l’exécuter. C’est une manière Orientée Objet de faire les choses.
D’autre part, nn.functional fournit certaines couches / activations sous forme de fonctions qui peuvent être appelées directement sur l’entrée plutôt que de définir un objet. Par exemple, pour rééchelonner un tenseur d’image, vous appelez torch.nn.functional.interpolate sur un tenseur d’image.
Donc, comment choisir ce que l’on utilise quand ? Lorsque la couche / activation / perte que nous implémentons a une perte.
Comprendre l’état de l’objet
En général, quelle que soit la couche, elle peut être vue comme une fonction. Par exemple, une opération de convolution est juste une multitude d’opérations de multiplication et d’addition. Donc, il est logique de la mettre en œuvre comme une fonction, n’est-ce pas ? Mais attendez, la couche garde des poids qui doivent être conservés et mis à jour pendant que nous entraînons. Par conséquent, du point de vue programmatique, une couche est plus que une fonction. Elle doit également garder des données qui changent lorsque nous entraînons notre réseau.
Maintenant, je veux que vous mettez en avant le fait que les données conservées par la couche convolutionnelle changent. Cela signifie que la couche a une état qui change lors de l’entraînement. Afin de mettre en œuvre une fonction qui effectue l’opération de convolution, nous aurions également besoin de définir une structure de données pour stocker les poids de la couche séparément de la fonction elle-même. Ensuite, faire de cette structure de données externe une entrée pour notre fonction.
Ou simplement pour éviter les démêlés, nous pourrions simplement définir une classe pour contenir la structure de données et faire de l’opération de convolution comme une fonction membre. Cela simplifierait vraiment notre travail, car nous n’avons pas à s’occuper des variables d’état existantes en dehors de la fonction. Dans de tels cas, nous préférerions utiliser les objets nn.Module où nous avons des poids ou d’autres états qui pourraient définir le comportement de la couche. Par exemple, une couche de dropout / Batch Norm se comporte différemment pendant l’entraînement et à la validation.
D’autre part, lorsque pas de state ou de poids sont requis, on pourrait utiliser nn.functional. Les exemples sont, le redimensionnement (nn.functional.interpolate), la moyenne de pooling (nn.functional.AvgPool2d).
Malgré les raisons précitées, la plupart des classes nn.Module ont leurs homologues dans nn.functional. Cependant, la ligne de raisonnement ci-dessus doit être respectée lors du travail pratique.
nn.Parameter
Une classe importante dans PyTorch est la classe nn.Parameter, qui à mon avis, n’a reçu que peu d’attention dans les textes d’introduction à PyTorch. Considérez le cas suivant.
Chaque nn.Module possède une fonction parameters() qui retourne, bien, ses paramètres trainables. Nous devons implicitement définir ce que ces paramètres sont. Dans la définition de nn.Conv2d, les auteurs de PyTorch ont défini les poids et biais comme paramètres d’une couche. Cependant, remarquez une chose, lorsque nous avons défini net, nous n’avons pas besoin d’ajouter les parameters de nn.Conv2d aux parameters de net. Cela s’est produit implicitement en raison de l’ajout de l’objet nn.Conv2d en tant que membre de l’objet net.
Cela est facilité à l’interne par la classe nn.Parameter, qui hérite de la classe Tensor. Lorsque nous appelons la fonction parameters() d’un objet nn.Module, elle retourne tous ses membres qui sont des objets nn.Parameter.
En fait, tous les poids de formation des classes nn.Module sont implémentés en tant qu’objets nn.Parameter. Lorsque qu’un nn.Module (nn.Conv2d dans notre cas) est assigné en tant que membre d’un autre nn.Module, les « paramètres » de l’objet assigné (c.-à-d. les poids de nn.Conv2d) sont également ajoutés aux « paramètres » de l’objet auquel il est assigné (paramètres de l’objet net). Cela s’appelle l’enregistrement des « paramètres » d’un nn.Module.
Si vous essayez d’affecter un tenseur à l’objet nn.Module, il ne sera pas visible dans la fonction parameters() à moins que vous ne le définissiez pas comme un objet nn.Parameter. Cela a été fait pour faciliter les scénarios où vous pourriez avoir besoin de mémoriser un tenseur non differentiable, par exemple, pour mémoriser l’output précédent dans le cas d’RNNs.
nn.ModuleList et nn.ParameterList()
J’ai souvenir que j’ai dû utiliser une nn.ModuleList lorsque j’ai implémenté YOLO v3 en PyTorch. J’ai dû créer le réseau en解析 un fichier texte contenant l’architecture. J’ai stocké tous les objets nn.Module correspondants dans une liste Python et puis j’ai fait de la liste un membre de mon objet nn.Module représentant le réseau.
Pour simplifier, quelque chose comme ça.
Comme vous pouvez le voir, contrairement à ce que nous ferions lors de l’enregistrement de modules individuels, affecter une liste Python n’enregistre pas les paramètres des modules à l’intérieur de la liste. Pour corriger ce problème, nous enveloppons notre liste dans la classe nn.ModuleList et l’affectons ensuite en tant que membre de la classe du réseau.
De même, une liste de tenseurs peut être enregistrée en enveloppant la liste à l’intérieur de la classe nn.ParameterList.
Initialisation des poids
L’initialisation des poids peut influencer les résultats de votre entraînement. De plus, vous pourriez avoir besoin de différents schémas d’initialisation des poids pour différents types de couches. Cela peut être réalisé par les fonctions modules et apply. modules est une fonction membre de la classe nn.Module qui retourne un itérateur contenant tous les objets membres nn.Module d’une fonction nn.Module. Ensuite, vous pouvez appeler la fonction apply sur chaque nn.Module pour l’initialiser.
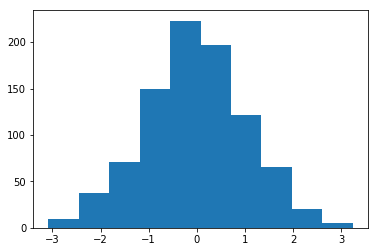
Histogramme des poids initialisés avec une Méthode = 1 et une Écart-type = 1
Il existe une multitude de fonctions d’initialisation inplace dans le module torch..nn.init.
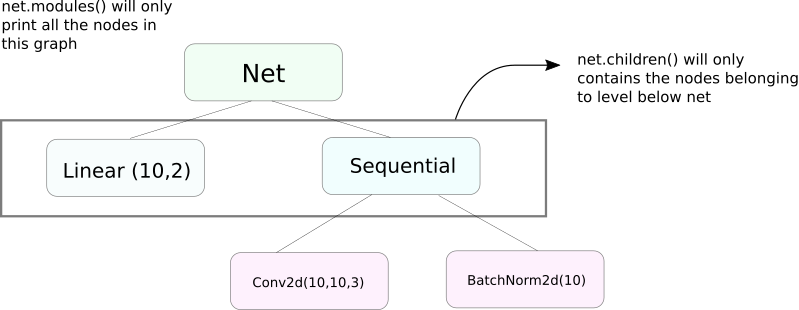
Les fonctions modules() et children()
Une fonction très similaire à modules est children. La différence est subtile mais importante. Comme nous le savons, un objet nn.Module peut contenir d’autres objets nn.Module en tant que membres de données.
children() ne retournera que la liste des objets nn.Module qui sont des membres de données de l’objet sur lequel children est appelé.
D’autre part, nn.Modules va récursivement à l’intérieur de chaque objet nn.Module, créant une liste de chaque objet nn.Module qui se trouve sur son chemin jusqu’à ce qu’il n’y ait plus d’objets nn.module. Notez, modules() retourne également l’nn.Module sur lequel il a été appelé en tant que partie de la liste.
Notez que ce qui précède reste vrai pour tous les objets / classes qui héritent de la classe nn.Module.
Donc, lorsque nous initialisons les poids, nous souhaiterions peut-être utiliser la fonction modules() car nous ne pouvons pas aller à l’intérieur de l’objet nn.Sequential et initialiser les poids pour ses membres.
Impression des informations sur le réseau
Nous pourrions avoir besoin d’imprimer des informations sur le réseau, que ce soit pour l’utilisateur ou à des fins de débogage. PyTorch offre une super manière de imprimer beaucoup d’informations sur notre réseau en utilisant ses fonctions named_*. Il en existe 4.
named_parameters. Retourne un itérateur qui donne un tuple contenant le nom des paramètres (si une couche de convolution est assignée commeself.conv1, alors ses paramètres seraientconv1.weightetconv1.bias) et la valeur retournée par la fonction__repr__denn.Parameter
2. named_modules. Identique à ci-dessus, mais l’itérateur retourne des modules comme la fonction modules() le fait.
3. named_children Identique à ci-dessus, mais l’itérateur retourne des modules comme la fonction children() le fait.
4. named_buffers Retourne les tenseurs de tampon tels que la moyenne mobile de la couche de normalisation de lot.
Different Learning Rates For Different Layers
Dans cette section, nous apprendrons comment utiliser des taux d’apprentissage différents pour nos différentes couches. En général, nous verrons comment avoir différents hyperparamètres pour différents groupes de paramètres, que ce soit différents taux d’apprentissage pour différentes couches ou différents taux d’apprentissage pour les biais et les poids.
L’idée de mettre en œuvre une telle chose est assez simple. Dans notre précédente publication, où nous avons mis en œuvre un classificateur CIFAR, nous avons passé tous les paramètres de réseau comme un ensemble au objet optimisateur.
Cependant, la classe torch.optim nous permet de fournir différents jeux de paramètres ayant des taux d’apprentissage différents sous forme de dictionnaire.
Dans le scénario ci-dessus, les paramètres de `fc1` utilisent un taux d’apprentissage de 0.01 et un momenent de 0.99. Si un hyperparamètre n’est pas spécifié pour un groupe de paramètres (comme `fc2`), il utilise la valeur par défaut de cet hyperparamètre, fournie en argument d’entrée à la fonction optimisatrice. Vous pouvez créer des listes de paramètres en fonction des différentes couches, ou si le paramètre est un poids ou un biais, en utilisant la fonction `named_parameters()` que nous avons couvert précédemment.
Planification du Taux d’Apprentissage
La planification de votre taux d’apprentissage est une hyperparamètre majeur que vous souhaitez ajuster. PyTorch offre de l’appui pour la planification du taux d’apprentissage avec son module torch.optim.lr_scheduler qui propose diverses plans de taux d’apprentissage. L’exemple suivant montre un tel exemple.
Le planificateur ci-dessus multiplie le taux d’apprentissage par gamma chaque fois que nous atteignons des époques contenues dans la liste milestones. Dans notre cas, le taux d’apprentissage est multiplié par 0.1 à l’10e et 20e époque. Vous devrez également écrire la ligne scheduler.step dans le boucle de votre code qui traverse les époques afin que le taux d’apprentissage soit mis à jour.
Généralement, le cycle de formation est composé de deux boucles imbriquées, où une boucle parcourt les époques et l’autre, imbriquée, parcourt les lots dans cette époque. Assurez-vous de faire appel à scheduler.step au début de la boucle de l’époque pour que votre taux d’apprentissage soit mis à jour. Faites attention de ne pas le mettre dans la boucle des lots, sinon votre taux d’apprentissage pourrait être mis à jour au 10e lot plutôt que pas le 10e époque.
Notez également que scheduler.step n’est pas un remplacement pour optim.step et vous devez appeler optim.step chaque fois que vous faites de la rétropropagation. (Cela se ferait dans la « boucle des lots »).
Enregistrer votre Modèle
Vous pourriez souhaiter enregistrer votre modèle pour une utilisation ultérieure en inférence, ou vous pourriez simplement vouloir créer des points de contrôle de formation. Lors de l’enregistrement des modèles dans PyTorch, vous avez deux options.
La première est d’utiliser torch.save. Cela est équivalent à sérialiser l’objet nn.Module entier en utilisant Pickle. Cela enregistre l’ensemble du modèle sur le disque. Vous pouvez charger ce modèle plus tard en mémoire avec torch.load.
Ceci sauvera l’ensemble du modèle avec les poids et l’architecture. Si vous n’avez besoin de sauvegarder que les poids, au lieu de sauvegarder l’ensemble du modèle, vous pouvez sauvegarder juste le state_dict du modèle. Le state_dict est essentiellement un dictionnaire qui associe les objets nn.Parameter d’une réseau à leurs valeurs.
Comme illustré ci-dessus, il est possible de charger un state_dict existant dans un objet nn.Module. Notez que cela ne concerne pas la sauvegarde de l’ensemble du modèle, mais seulement les paramètres. Vous devez créer le réseau avec les couches avant de charger le state_dict. Si l’architecture du réseau n’est pas identique à celle de celle dont nous avons sauvegardé le state_dict, PyTorch lancera une erreur.
Un objet optimisateur de torch.optim possède également un state_dict qui est utilisé pour stocker les hyperparamètres des algorithmes d’optimisation. Il peut être sauvegardé et chargé de la même manière que ci-dessus en appelant load_state_dict sur un objet optimisateur.
Conclusion
Ceci termine notre discussion sur certaines des fonctionnalités avancées de PyTorch. J’espère que les informations que vous avez lues dans ce billet vous aideront à mettre en œuvre les idées complexes de deep learning que vous avez peut-être imaginées. Voici des liens pour un approfondissement si vous êtes intéressé.
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced