













简介
大家好,这是我们在PyTorch系列中的又一篇文章。本文面向已经熟悉PyTorch基础并且想要提升到中级水平的用户。虽然我们在之前的文章中已经介绍了如何实现一个基本分类器,但在本文中,我们将讨论如何使用PyTorch实现更复杂的深度学习功能。本文的一些目标是让您理解:
- PyTorch类如
nn.Module、nn.Functional、nn.Parameter之间的区别以及何时使用哪个 - 如何自定义训练选项,例如为不同层设置不同的学习率、不同的学习率计划
- 自定义权重初始化
那么,让我们开始吧。
nn.Module与nn.Functional
这在阅读开源代码时经常会遇到。在PyTorch中,层通常作为torch.nn.Module对象或torch.nn.Functional函数实现。该使用哪个?哪个更好?
正如我们在第2部分所覆盖的,`torch.nn.Module`基本上是PyTorch的基石。它的运作方式是你首先定义一个`nn.Module`对象,然后调用其`forward`方法来运行它。这是一种面向对象的方式。
另一方面,`nn.functional`提供了一些以函数形式存在的层/激活,可以直接作用于输入而不是定义一个对象。例如,为了缩放一个图像张量,你会在图像张量上调用`torch.nn.functional.interpolate`。
那么我们该如何选择使用哪个呢?当我们要实现的层/激活/损失具有损失时。
理解有状态性
通常,任何层都可以被视为一个函数。例如,卷积操作只是一堆乘法和加法操作。因此,我们将其实现为一个函数是有意义的吧?但等等,层持有权重,在训练时需要存储和更新。因此,从编程角度来看,层不仅仅是函数。它还需要持有在训练我们的网络时会改变的数据。
卷积层所持有的数据是会变化的。这意味着该层具有状态,随着我们的训练而改变。为了实现卷积操作的功能,我们还需要定义一个数据结构来单独存储该层的权重,并与函数本身分离。然后,将这个外部数据结构作为输入传递给我们的函数。
或者,为了简化问题,我们可以定义一个类来持有数据结构,并将卷积操作作为成员函数。这确实会减轻我们的工作负担,因为不用担心函数外存在状态变量。在这些情况下,我们更愿意使用nn.Module对象,其中包含权重或其他可能定义层行为的状态。例如,dropout / Batch Norm层在训练和推理时的行为是不同的。
另一方面,如果不需要状态或权重,可以使用nn.functional。例如,调整大小(nn.functional.interpolate)、平均池化(nn.functional.AvgPool2d)。
尽管有上述理由,但大多数nn.Module类都有其nn.functional对应物。然而,在实际工作中,上述推理线是需要被尊重的。
nn.Parameter
在PyTorch中,有一个非常重要的类,那就是nn.Parameter类,然而令人惊讶的是,在PyTorch的入门教材中很少提到它。考虑以下情况。
每个nn.Module都有一个parameters()函数,它返回的是可训练的参数。我们必须隐式地定义这些参数是什么。在定义nn.Conv2d时,PyTorch的作者们将权重和偏置定义为层的参数。然而,注意一点,当我们定义net时,我们并没有需要将nn.Conv2d的parameters添加到net的parameters中。这是通过将nn.Conv2d对象设置为net对象的成员而隐式实现的。
这由内部的nn.Parameter类实现,它继承自Tensor类。当我们调用一个nn.Module对象的parameters()函数时,它返回所有其成员中是nn.Parameter对象的参数。
实际上,所有nn.Module类的训练权重都是作为nn.Parameter对象实现的。无论何时,一个nn.Module(在我们的案例中是nn.Conv2d)被分配为另一个nn.Module的成员,被分配对象的“参数”(即nn.Conv2d的权重)也会添加到被分配到的对象的“参数”(即net对象的参数)中。这称为注册nn.Module的“参数”。
如果你尝试将一个张量赋值给nn.Module对象,除非你将其定义为nn.Parameter对象,否则它在parameters()中不会显示。这样做是为了方便在需要缓存一个非微分张量的情况下,例如在RNN中缓存之前的输出。
nn.ModuleList和nn.ParameterList()
我记得在用PyTorch实现YOLO v3时,我必须使用nn.ModuleList。我必须通过解析一个包含网络结构的文本文件来创建网络。我将所有对应的nn.Module对象存储在一个Python列表中,然后将这个列表作为我的表示网络的nn.Module对象的成员。
简而言之,像这样。
正如你所见,与注册单个模块时不同,将Python列表分配给模块的参数并不会在列表内部注册模块的参数。为了解决这个问题,我们将列表用`nn.ModuleList`类包裹,然后将其作为网络类的一个成员分配。
同样,可以通过将列表包裹在`nn.ParameterList`类中来注册张量列表。
权重初始化
权重初始化可以影响你的训练结果。而且,你可能需要为不同类型的层采用不同的权重初始化方案。这可以通过`nn.Module`类的`modules`和`apply`函数来实现。`modules`是`nn.Module`类的一个成员函数,它返回一个包含`nn.Module`成员对象的迭代器,这些对象属于一个`nn.Module`函数。然后,对每个`nn.Module`调用`apply`函数可以设置其初始化。
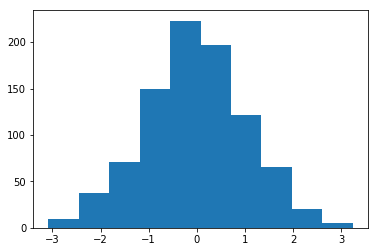
使用均值为1、标准差为1的权重进行初始化直方图
在`torch.nn.init`模块中可以找到许多原地初始化函数。
模块()与子项()的区别
与modules非常相似的功能是children。它们之间的区别虽然微妙,但非常重要。我们知道,一个nn.Module对象可以包含其他作为其数据成员的nn.Module对象。
children()只会返回一个列表,包含调用children的对象的数据成员中的nn.Module对象。
另一方面,nn.Modules会递归地深入每个nn.Module对象,创建一个列表,包括沿途遇到的每个nn.Module对象,直到没有nn.module对象为止。注意,modules()也会将调用它的nn.Module对象作为列表的一部分返回。
请注意,上述语句对于所有从nn.Module类派生的对象/类都是正确的。
因此,在初始化权重时,我们可能需要使用modules()函数,因为我们无法进入nn.Sequential对象并初始化其成员的权重。
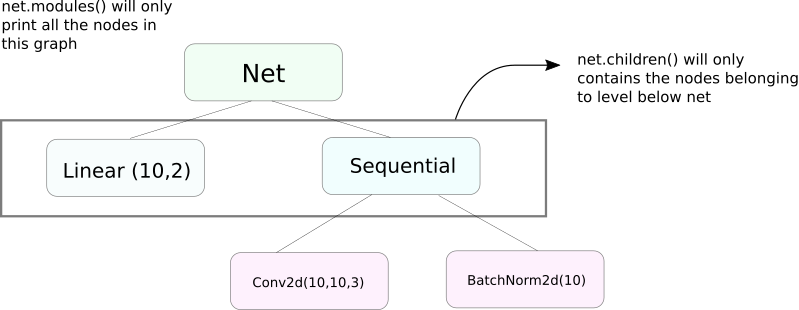
打印有关网络的信息
我们可能需要打印有关网络的信息,无论是为用户还是为了调试目的。PyTorch 提供了一种非常简洁的方式来打印大量关于我们网络的信息,使用它的 named_* 函数。有四个这样的函数。
named_parameters。返回一个迭代器,该迭代器提供包含参数名称的元组(如果卷积层被分配为self.conv1,那么它的参数将是conv1.weight和conv1.bias)以及nn.Parameter的__repr__函数返回的值。
2. named_modules。与上面相同,但迭代器返回模块,就像modules()函数一样。
3. named_children。与上面相同,但迭代器返回的模块就像children()返回的一样。
4. named_buffers。返回缓冲张量,例如 Batch Norm 层的运行平均值。
不同层的不同学习率
在本节中,我们将学习如何为不同的层使用不同的学习率。一般来说,我们将介绍如何为不同的参数组设置不同的超参数,无论是为不同的层设置不同的学习率,还是为偏差和权重设置不同的学习率。
实现这样的想法相对简单。在我们之前的帖子中,我们实现了一个CIFAR分类器,将网络的所有参数作为一个整体传递给优化器对象。
然而,torch.optim类允许我们以字典的形式提供具有不同学习率的不同参数集。
在上述场景中,`fc1`的参数使用学习率0.01和动量0.99。如果某个参数组(如`fc2`)没有指定超参数,则使用优化器函数的输入参数所给的默认超参数值。您可以根据不同的层,或者参数是权重还是偏置,使用我们上面介绍的named_parameters()函数创建参数列表。
学习率调度
调度学习率是您想要调整的主要超参数之一。PyTorch通过torch.optim.lr_scheduler模块提供学习率调度支持,该模块具有多种学习率调度方案。以下示例演示了其中一个例子。
上述调度器会在达到milestones列表中的每个时期时,将学习率乘以gamma。在我们这个案例中,在第10n个和第20n个时期,学习率会被乘以0.1。你还需要在你代码中的每个时期循环中编写scheduler.step这行代码,以便更新学习率。
通常,训练循环由两个嵌套循环组成,其中一个循环遍历时期,另一个循环遍历该时期的批次。确保你在时期循环的开始调用scheduler.step,以便更新学习率。注意不要写在批次循环中,否则你的学习率可能会在第10个批次而不是第10n个时期更新。
还要记住scheduler.step不能替代optim.step,你需要在每次反向传播后都调用optim.step。(这将在“批次”循环中)。
保存你的模型
你可能想为后续的推理使用而保存你的模型,或者只是想创建训练检查点。当涉及到在PyTorch中保存模型时,有两条路可走。
第一条是使用torch.save。这等同于使用Pickle对整个nn.Module对象进行序列化。这个方法将整个模型保存到磁盘上。你可以使用torch.load将此模型后来载入到内存中。
上述方法将保存整个模型,包括权重和架构。如果你只需要保存权重,而不是整个模型,你可以只保存模型的 state_dict。 state_dict 基本上是一个字典,它将网络中的 nn.Parameter 对象映射到它们的值。
如上所示,你可以将一个现有的 state_dict 加载到一个 nn.Module 对象中。注意,这里只涉及参数的保存,而不是整个模型的保存。在加载状态字典之前,你需要创建具有相同层的网络。如果网络架构与我们保存的 state_dict 所对应的网络架构不完全相同,PyTorch 将抛出一个错误。
来自 torch.optim 的优化器对象也具有一个 state_dict 对象,它用于存储优化算法的超参数。它可以像我们上面所做的那样通过在优化器对象上调用 load_state_dict 来保存和加载。
结论
这完成了我们对 PyTorch 一些高级功能的讨论。我希望你在这篇文章中读到的东西将帮助你实现你可能想到的复杂的深度学习思想。如果你有兴趣,可以参考以下链接进行进一步学习。
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced