













Inleiding
Hallo lezers, dit is opnieuw een post in een reeks die we over PyTorch doen. Deze post is bedoeld voor PyTorch gebruikers die bekend zijn met de basis van PyTorch en een stap naar het gevorderde niveau willen maken. Ondanks dat we in een eerdere post hoe je een basisclassificator kunt implementeren hebben behandeld, zal dit in deze post over hoe je meer complexe diepe learning functionaliteit kunt implementeren met behulp van PyTorch gaan. Enkele doelstellingen van deze post zijn om u te laten begrijpen.
- Wat is de verschillen tussen PyTorch klassen als
nn.Module,nn.Functional,nn.Parameteren wanneer welke moet worden gebruikt - Hoe u uw training opties kunt aanpassen, zoals verschillende leeringsnelheden voor verschillende lagen, verschillende leeringschema’s
- Aangepaste gewichtinitialisatie
Dus laten we beginnen.
nn.Module vs nn.Functional
Dit is iets wat vaak voorkomt, vooral als u open broncode leest. In PyTorch zijn lagen vaak uitgevoerd als een van de objecten torch.nn.Module of als functie torch.nn.Functional. Welke moet u gebruiken? Welke is beter?
Als we in Deel 2 hadden overgedragen, is torch.nn.Module eigenlijk de kern van PyTorch. Het manier waarop het werkt is dat u eerst een object van nn.Module definieert, en vervolgens het forward-methode aanroept om het te laten draaien. Dit is een object-georiënteerde manier van werken.
Op het andere hand, biedt nn.functional sommige laag / activaties in de vorm van functies die direct aan de invoer kunnen worden aangeroepen in plaats van een object te definiëren. Bijvoorbeeld, om een tensor van een afbeelding te herschalen, roept u torch.nn.functional.interpolate aan op een tensor van een afbeelding.
Maar hoe kiezen we dan wat we gebruiken? Wanneer de laag / activatie / verlies die we implementeren een verlies heeft.
Begrip van Stateful-ness
Gelijkaardig kan elke laag worden gezien als een functie. Bijvoorbeeld, een convolutiesoperatie is een simpele bundel van optelsommen en vermenigvuldigingen. Dus zou het logisch zijn om het als een functie uit te voeren, right? Maar even wachten, de laag bevat gewichten die moeten worden opgeslagen en bijgewerkt terwijl we trainen. Dus vanuit een programmatische hoek is een laag meer dan een functie. Het moet ook gegevens bijhouden die veranderen als we ons netwerk trainen.
Ik wil nu op de facte dat de gegevens die door de convolutie laag veranderen de nadruk leggen. Dit betekent dat de laag een toestand heeft die wijzigd als we trainen. Om een functie uit te voeren die de convolutie bewerking uitvoert, zouden we ook een datastructuur moeten definiëren om de gewichten van de laag apart te houden van de functie zelf. En dan deze externe datastructuur een input voor onze functie maken.
Of gewoon om de moeite te besparen, kunnen we een klasse definiëren om de datastructuur bij te houden, en de convolutie bewerking als een ledenfunctie ervan maken. Dit zou ons werk echt gemakkelijker maken, omdat we niet hoeven te zorgen voor toestandvariabelen buiten de functie. In deze gevallen zouden we de nn.Module objecten voorkeur geven waar we gewichten of andere toestanden hebben die het gedrag van de laag zouden kunnen bepalen. Bijvoorbeeld, een dropout / Batch Norm laag gaat anders tegenover training en inference.
Aan de andere kant, waar geen toestand of gewichten nodig zijn, kan men de nn.functional gebruiken. Voorbeelden zijn, het aanpassen van grootte (nn.functional.interpolate), gemiddelde pooling (nn.functional.AvgPool2d).
Ongeacht de bovenstaande redeneringen heeft de meeste nn.Module klassen hun nn.functional tegenhangers. Echter, de bovenstaande lijn van redenering moet in de praktijk gerespecteerd worden.
nn.Parameter
Een belangrijke klasse in PyTorch is de nn.Parameter klasse, die onverwacht weinig aandacht heeft gekregen in de PyTorch-introductie teksten. Neem voorbeeld van het volgende geval.
Elke nn.Module heeft een parameters() functie die, wellicht verwacht, zijn trainbare parameters teruggeeft. We moeten impliciet vaststellen wat deze parameters zijn. In de definitie van nn.Conv2d, hebben de PyTorch-auteurs deParameters en -bias gezet als Parameters van die laag. Echter, ontdekken we dat, als we net definiëren, we de parameters van nn.Conv2d niet nodig hebben toe te voegen aan de parameters van net. Dat gebeurt impliciet door het instellen van het nn.Conv2d object als een lid van het net object.
Dit wordt intern gefaciliteerd door de nn.Parameter klasse, die de Tensor klasse subclasseert. Als we de parameters() functie aanraken van een nn.Module object, geeft het alle zijn leden terug die nn.Parameter objecten zijn.
In feite, alle trainendeParameters van de nn.Module klassen zijn geïmplementeerd als nn.Parameter objecten. Elke keer dat een nn.Module (nn.Conv2d in ons geval) wordt toegekend als lid van een andere nn.Module, worden de “Parameters” van het toegewezen object (d.w.z. deParameters van nn.Conv2d) ook toegevoegd aan de “Parameters” van het object dat wordt toegekend aan (Parameters van net object). Dit noemt men het “registreren” van deParameters van een nn.Module.
Als u een tensor aan een nn.Module-object probeert toe te wijzen, zal dit niet verschijnen in de parameters()lijst, tenzij u het als een nn.Parameter-object definieert. Dit is gedaan om scenario’s te faciliteren waarin u misschien een niet-differentiabel tensor moet cachen, bijvoorbeeld bij het cachen van vorige uitvoer bij RNN’s.
nn.ModuleList en nn.ParameterList()
Ik herinner me dat ik een nn.ModuleList moest gebruiken toen ik YOLO v3 in PyTorch uitvoerde. Ik moest de netwerkarchitectuur parsen uit een tekstbestand dat de architectuur bevatte. Ik stelde alle nn.Module-objecten in een Python-lijst en maakte de lijst een lid van mijn nn.Module-object dat de netwerkrepresentatie voorstelde.
Om het eenvoudiger te maken, iets als dit.
Zoals u ziet, verschillend van het registreren van afzonderlijke modules, registreert het toewijzen van een Python lijst niet de parameters van de modules binnen de lijst. Om dit op te lossen, doen we onze lijst omsluiten met de klasse nn.ModuleList en wijs dan het toe aan de klasse van het netwerk.
Hetzelfde geldt voor een lijst van tensoren, die kan worden geregistreerd door de lijst in een nn.ParameterList klasse te doen omsluiten.
Weight Initialisatie
Weight initialisatie kan de resultaten van uw training beïnvloeden. Bovendien kun je verschillende typen lagen nodig hebben voor verschillende initialisatieschema’s. Dit kan worden uitgevoerd met de functies modules en apply. modules is een memberfunctie van de klasse nn.Module die een iterator retourneert die alle leden van het object nn.Module bevat van een nn.Module functie. Gebruik vervolgens de apply functie op elke nn.Module om de initialisatie ervan in te stellen.
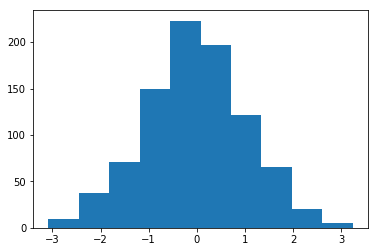
Histogram van gewichten geïnitialiseerd met gemiddelde = 1 en standaardafwijking = 1
Er zijn een hoop inplace initialisatiefuncties te vinden in het torch..nn.init module.
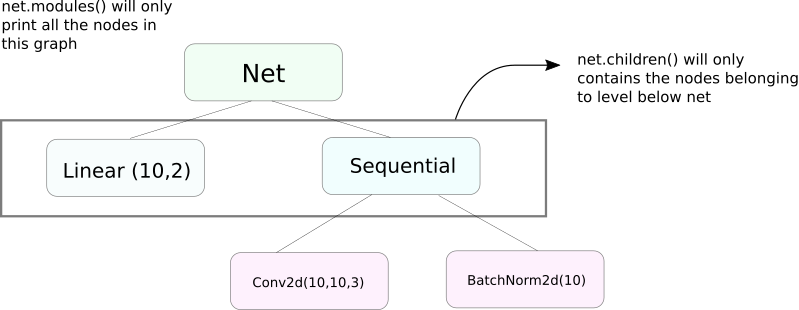
modules() vs children()
Een zeer vergelijkbare functie aan modules is children. Het verschil is klein maar belangrijk.ALS we weten, kan een nn.Module object andere nn.Module objecten als zijn datamember bevatten.
children() zal alleen een lijst teruggeven van de nn.Module objecten die deel uitmaken van het object waarop children wordt aangeroepen.
Aan de andere kant gaat nn.Modules recursief binnen elk nn.Module object, creërend een lijst van elk nn.Module object dat het pad volgt tot er geen nn.module objecten meer over zijn. Noteer, modules() geeft ook het nn.Module object terug dat het is aangeroepen als onderdeel van de lijst.
Merk op, dat de bovenstaande uitleg ook van toepassing is op alle objecten / klassen die subclassen van de nn.Module klasse zijn.
Dus, wanneer we de gewichten initialiseren, moeten we misschien de modules() functie gebruiken omdat we niet kunnen binnendringen in het nn.Sequential object en de gewichten initialiseren voor zijn leden.
Informatie Over Het Netwerk Afdrukken
We moeten misschien informatie over het netwerk afdrukken, ofwel voor de gebruiker dan wel voor debugging-doeleinden. PyTorch biedt een behoorlijk leuk systeem om veel informatie over ons netwerk af te drukken, door middel van zijn named_* functies. Er zijn 4 dergelijke functies.
named_parametersgeeft een iterator terug die een tuple bevat bestaande uit naam van de parameters (als een convolutie laag is toegewezen alsself.conv1, dan zou zijn parametersconv1.weightenconv1.biaszijn) en de waarde die wordt geretourneerd door de__repr__functie van denn.Parameter
2. named_modules. Hetzelfde als boven, maar de iterator geeft modules terug zoals de modules() functie doet.
3. named_children Hetzelfde als boven, maar de iterator geeft modules terug zoals children() teruggeeft
4. named_buffers Geeft buffer tensor terug zoals de langsstromende gemiddelde van een Batch Norm laag.
Verschillende Learning Rates Voor Verschillende Lagen
In dit gedeelte zullen we leren hoe we verschillende learning rates kunnen gebruiken voor onze verschillende lagen. In het algemeen zal ons les geven hoe we verschillende hyperparameters kunnen hebben voor verschillende groepen parameters, ofwel verschillende learning rates voor verschillende lagen, ofwel verschillende learning rates voor verliezen en gewichten.
De idee om zo iets uit te voeren is relatief eenvoudig. In onze vorige post, waarin we een CIFAR classificator implementeerden, hebben we alle parameters van het netwerk als geheel doorgegeven aan het optimizer object.
Hierbij is echter de torch.optim klasse ons toegestaan verschillende setsParameters met verschillende learning rates te geven in de vorm van een dictionary.
In het bovenstaande scenario gebruikt `fc1` een learning rate van 0.01 en momentum van 0.99. Als een hyperparameter niet is gespecificeerd voor een groep parameters (zoals `fc2`), gebruiken ze de standaard waarde van dat hyperparameter, gegeven als argument aan de optimizer functie. U kunt parameterlijsten op basis van verschillende laag samenstellen, of of de parameter een gewicht of een bias is, door middel van de functie named_parameters() die we bovenop besproken hebben.
Learning Rate Scheduling
Het plannen van uw learning rate is een belangrijke hyperparameter die u wilt afstemmen. PyTorch biedt ondersteuning voor het plannen van learning rates met zijn torch.optim.lr_scheduler module, dat verschillende learning rate schema’s biedt. Het volgende voorbeeld laat zo’n voorbeeld zien.
De bovenstaande planner vermenigvuldigd de learning rate met gamma elke keer als we een epoch bereiken die in de milestones lijst zit. In ons geval wordt de learning rate vermenigvuldigd met 0.1 bij de 10e en de 20e epoch. U moet ook de regel scheduler.step schrijven in de loop in uw code die over de epochs gaat, zodat de learning rate bijgewerkt wordt.
Genereel bestaat een training loop uit twee binnenste loops, waar één loop over de epochs gaat en de andere loop over de batchs in die epoch. Zorg ervoor dat u scheduler.step aanroept aan het begin van de epoch loop zodat uw learning rate bijgewerkt wordt. Maak er geen fout met het aanroepen ervan in de batch loop, anders wordt uw learning rate misschien bijgewerkt bij de 10e batch in plaats van bij de 10e epoch.
Vergeet ook niet dat scheduler.step geen vervanging is voor optim.step en u moet optim.step elke keer aanroepen als u terugpropagatie uitvoert. (Dit zou in de “batch” loop zijn).
Sla uw Model op
U zou uw model misschien willen opslaan voor later gebruik voor inference of gewoon om training checkpoints te maken. Bij het opslaan van modellen in PyTorch heeft u twee opties.
Eerst is het gebruiken van torch.save. Dit is equivalent aan het serialiseren van de gehele nn.Module objecten met behulp van Pickle. Dit slaat het gehele model op naar schijf. U kunt dit model later in het geheugen laden met torch.load.
Het bovenstaande zal de gehele model met gewichten en architectuur opslaan. Als u alleen de gewichten moet opslaan, in plaats van het gehele model, kunt u gewoon de state_dict van het model opslaan. De state_dict is eigenlijk een dictionary dat de nn.Parameter objecten van een netwerk aan hun waarden toewijst.
ALS getoond in bovenstaande, kan men een bestaande state_dict in een nn.Module object laden. Noteer dat dit niet betrekking heeft op het opslaan van het gehele model, maar alleen aan de parameters. U moet het netwerk met lagen creëren voordat u de state dict laden. Als de netwerkarchitectuur niet exact dezelfde is als het waarvan we de state_dict opslaan, zal PyTorch een fout gooien.
Een object van optimizer van torch.optim heeft ook een state_dict object dat wordt gebruikt om de hyperparameters van de optimisatiealgoritmen op te slaan. Het kan op gelijke wijze worden opgeslagen en geladen als we hierboven deden door load_state_dict aan een optimizer object aan te roepen.
Conclusie
Dit beëindigt onze discussie over enkele van de meer geavanceerde functionaliteiten van PyTorch. Ik hoop dat de dingen die u in dit bericht hebt gelezen u helpen om complexe diepe leer ideeën uit te voeren die u misschien hebben bedacht. Hier zijn links voor verdere studie, indien u geïnteresseerd bent.
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced