













מביאה
היי קוראים, זה עוד פוסט אחד בסדרה בה אנחנו עובדים על פיטורץ'. בפוסט זה מיועד למשתמשים בפיטורץ' המורגלים לבסיסים של הפיטורץ' ורוצים לעבור לרמה הביניים. למרות שכבר עבדנו על איך ליישם ספקטרם בסיסי בפוסט קודם, בפוסט זה, אנחנו נדבר על איך ליישם תפקודים עמוקים יותר של למידה עמוקה בעזרת פיטורץ'. חלק מהמטרות של הפוסט האלה הן לספק לך הבנה על.
- מה ההבדל בין הקבוצות בפיטורץ' כמו
nn.Module,nn.Functional,nn.Parameterומתי להשתמש בכל אחת מהן - איך להתאים את אפשרויות ההכשרה שלך כמו שינויי שיעורי למידה שונים עבור שכבות שונות, למעשה לתוצאות שיחזורים שונים
- התחלת משקל מותאמת אישית
אז, בואו נתחיל.
nn.Module מול nn.Functional
זה משהו שקורה די הרבה, בעיקר כשאתה קורא קוד פתוח. בפיטורץ', השכבות מובנים לעיתים רבות באחד מ-torch.nn.Module או בפעולה torch.nn.Functional. מי להשתמש? איזה טוב יותר?
כפי שעסקנו בחלק 2, torch.nn.Module הוא בעצם הבסיס של PyTorch. הדרך בה הוא פועל היא שראשית אתה מגדיר אבן מול של nn.Module, ואחר מה אתה מפעיל את שיחזור ה forward שלו כדי לבצע את העבודה. זו דרך של עיסוק סגולה ערכית.
מצד שני, nn.functional מספק כמה שכבות / פעילויות בצורת פונקציות שניתן להתקשר ישירות על הקלט במקום להגדיר אבן מול. לדוגמה, כדי לשנות את הגודל של תמונת טנסור, אתה מקריא torch.nn.functional.interpolate על תמונת טנסור.
אז איך אנחנו מחליטים מה להשתמש בו במידה כלשהי? כשלשכבה / פעילות / הפסד שאנחנו מיישמים יש הפסד.
הבנה של המצב המשנהה
בדרך טיפוסית, כל שכבה ניתן להסתכל עליה כפונקציה. לדוגמה, פעילות מבנה קונבולציונלית היא רק ערימת חילופים והולכים אחר עוד פעילויות. אז, זה הגיוני שנייצר אותה כפונקציה, נכון? אבל המשך הדבר, השכבה מחזיקה משקלים שצריך להישמר ולעדכנות בזמן האימון. לכן, מנקודת המבט הקודמת, השכבה היא יותר מפונקציה. היא צריכה גם להחזיק מידע, שמשתנה בזמן אימון הרשת שלנו.
אני רוצה להדחיק על העובדה שהמידע שבידים של השכבה הקולוקציונית משתנה. זה אומר שלשכבה יש מצב שמשתנה בזמן האימון. כדי ליישם פונקציה שמבצעת את הפעלת הקולוקציונית, אנחנו גם יש צורך בהגדרת מבנה מידע שישמר את המשקלים של השכבה בניגוד להפוך עצמו. ואז, נעשה את המבנה החיצוני הזה מקבל לתת לפונקציית שלנו.
או רק כדי להתחמק מההסתייגות, אנחנו יכולים פשוט להגדיר מחלקה בכדי להחזיק את המבנה המידעי, ולהעשית את הפעלת הקולוקציונית כפונקציה חברתית. זה יקלט באמת את עבודתנו, כי אין לנו צורך לדאוג על משקלים בעלי מצב מחוץ לתוך הפונקציה. במקרים אלה, אנחנו נוטים להשתמש בnn.Module בהם יש משקלים או מצבים אחרים שעשויים להגדיר את ההתנהגות של השכבה. לדוגמה, שכבה של dropout / Batch Norm מתנהגת אחרת בהתאמה ובהבחנה.
מצד שני, במקרים בהם איננו צריך מצב או משקלים, נוכל להשתמש בnn.functional. דוגמאות לכך הן הגדלת הגודל (nn.functional.interpolate) והסרת הממוצע (nn.functional.AvgPool2d).
למרות ההגיון העליון, רוב המחלקות nn.Module יש מעבדות חיתוך חיצוניות. אך על ידי הגיון העליון הזה, צריך להשתמש בו בעבודה המעשית.
nn.Parameter
מסוג חשוב בPyTorch הוא המידע nn.Parameter, שלמרבה הפתעתי, קיבל מעט מדיום בספרי הקצת המבואים לPyTorch. קחו בחשבון את המקרה הבא.
לכל nn.Module יש פעולה parameters() שמחזירה את הפרמטרים המאמנים שלו. אנחנו צריכים להגדיר באופן אינטראלי את הפרמטרים האלה. בהגדרה של nn.Conv2d, המחברים של PyTorch הגדירו את המשקלים והשילובים כפרמטריםלשכבה הזו. אבל, הבחנו בדבר אחד, שבעידן בו אנחנו מגדירים net, לא היה צורך להוסיף את הparameters של nn.Conv2d לparameters של net. זה קרה באופן אינטראלי על-ידי הגדירת nn.Conv2d כמותף של net עצמו.
זה מוסיף משמעותית על-ידי המידע nn.Parameter המעורבב, שהוא סבך של המידע Tensor המקורי. כשאנחנו מקרינים את פעולת parameters() של עצם nn.Module, היא מחזירה את כל חבריות האלה שהם nn.Parameter עצמים.
למעשה, כל המשקלים המאמנים של מודלי nn.Module מיועדים כעצמים nn.Parameter. בכל פעם שעצם nn.Module (nn.Conv2d במקרה שלנו) מוגדר כחברה של עצם אחר nn.Module, ה "פרמטרים" של העצם המוגדר (אז, המשקלים של nn.Conv2d) מוסיפים גם ל "פרמטרים" של העצם שבו מוגדרים (פרמטרים של עצם net). זה נקרא רשום "
אם אתה מנסה להעניק טנסור לאובייקט nn.Module, הוא לא יופיע ב parameters() אם אתה לא מגדיר אותו כאובייקט nn.Parameter. זה נעשה כדי לקלוט סיטאציות בהן אתה עשוי לצרך להאחסן טנסור לא שונה, לדוגמה, במקרה של אחסון היצאות הקודמת במקרה של RNNs.
nn.ModuleList ו nn.ParameterList()
אני זוכר שהייתי צריך להשתמש ב nn.ModuleList כשהייתי מבצע את האמצעים של YOLO v3 ב PyTorch. הייתי צריך ליצור את הרשת על-ידי ניתוח של קובץ טקסט שהכיל את הארכיטקטורה. אני אחזר את כל האובייקטים nn.Module הקשורים ברשימה ב Python ואז הפך את הרשימה לחברה של האובייקט שלי nn.Module שמייצג את הרשת.
כדי לפשט את הדבר, משהו כמו זה.
אתם רואים, לא כמו שאם נרשמה מודלים בודדים, שיעור רשימת פיתוחים בפיתוחי Python לא מרשם את הפרמטרים של המודלים בתוך הרשימה. כדי לתקן את זה, אנחנו מתחבאים את הרשימה שלנו במחלקה nn.ModuleList, ואחר כך אנחנו מעצבים אותה כחברה למערכת הרשת.
באופן דומה, רשימת טנסורים יכולה להירשמה על ידי הקבלה שלהם בתוך מחלקה nn.ParameterList.
הגדלת משקל
הגדלת המשקלים יכולה להשפיע על תוצאות האימון שלך. יותר מזה, אתה עשוי לדרוש סדרות הגדלת משקלים שונות עבור המערכות השונות. זה יכול להיות בעזרת הפונקציות modules ו apply modules הוא פונקציה חברתית של nn.Module המחזירה איתורן של כל החברות nn.Module של תוך תפקיד nn.Module מבנה. אחר כך ניתן להשתמש בפונקציית apply על כל חברה nn.Module כדי להגדיר את ההגדלה הראשונית שלה.
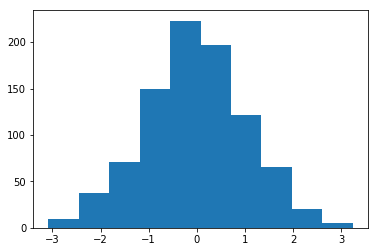
הגדלה של המשקלים המורשת עם ממוצע = 1 וסטנדרט = 1
יש מספר פונקציות להגדלה במקום במודל torch..nn.init למצאת.
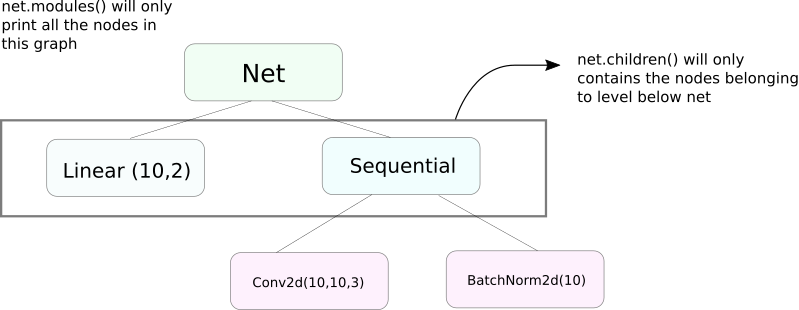
מודלים() נגד ילדים()
פונקציית modules מאוד דומה לchildren. ההבדל קל אבל חשוב. כפי שאנחנו יודעים, אובייקט של nn.Module יכול לכלול את עצמו בתוכו אובייקטים נוספים של nn.Module.
children() יחזיר רק רשימה של אובייקטים nn.Module שהם חלק של האובייקט של מי שמהווה מקור לקריאה לchildren.
מצד שני, nn.Modules נכנס באופן רקורסיבי לתוך כל אובייקט nn.Module, יוצר רשימה של כל אובייקט nn.Module שנמצא בדרך עד שלא יותר אובייקטי nn.module למציאה. שימו לב, modules() גם יחזיר את הnn.Module שלו כחלק מהרשימה.
שימו לב שההצהרה הקטנה הזו נכונה גם לכל אובייקטים/קבוצות שמסוגלים להיות סבסודים למעלה מהמודל nn.Module.
אז, כשאנחנו מוגדרים את המשקלים, אולי נרצה להשתמש בפונקצייתmodules() מפני שאנחנו לא יכולים להגיע לתוך האובייקט nn.Sequential ולהתחיל את המשקלים עבור חברתו.
הדפסת מידע על הרשת
אולי אנחנו נזדקק להדפיס מידע על הרשת, בין אם זה עבור המשתמש או בשביל התיקון התהליכים. פיטורך מעניק דרך מעולה להדפיס מידע רב על הרשת שלנו בעזרת פונקציותיו named_*. יש 4 פונקציות כאלו.
named_parameters. מחזירה איטרור שמעביר קבוצת קבעים הכילה בשם של הפרמטרים (אם שכבה קוונצולציונלית ניתנת כself.conv1, אז הפרמטרים שלה יהיוconv1.weightוconv1.bias) והערך שחוזר על ידי הפונקציה__repr__שלnn.Parameter
2. named_modules. זה דומה לקודם, אך האיטרור מחזיר מודולים כמו שהפונקציה modules() מספקת.
3. named_children זה דומה לקודם, אך האיטרור מחזיר מודולים כמו שהפונקציה children() מספקת
4. named_buffers מחזירה טensor המאגרים כמו ממוצע המהר של שכבת ההרף המקבילה בשכבת ההרף המקבילה.
שיעורי למידה שונים עבור שכבות שונות
בחלק זה, אנחנו נלמד איך להשתמש בשיעורי למידה שונים עבור השכבות השונות שלנו. באופן כללי, אנחנו נסקול איך לקבל היפרפרמטרים שונים עבור קבוצות פרמטרים שונות, בין אם זה שיעורי למידה שונים עבור שכבות שונות, או שיעורי למידה שונים עבור הביאים והמשקלים.
הרעיון ליישם משהו כזה הוא די פשוט. בפוסט הקודם שלנו, בו יישמנו סינטיסטיקן ל-CIFAR, העברנו את כל הפרמטרים של הרשת כמקבץ שלם לאובייקט המעודד.
אך הקבוצה torch.optim מאפשרת לנו לספק קבוצות של פרמטרים שיש להם קצבי למידה שונים באופן של מילון.
במקרה העליון, הפרמטרים של `fc1` משתמשים בקצב למידה של 0.01 ומוניטין של 0.99. אם קבוצת פרמטרים לא מוגדרת קובץ של היפרפארמטרים (כמו `fc2`), הם משתמשים בערך המובן הבסיסי של ההיפרפארמטרים, שנתנה כאן כתוצאה מהפונקציה של המעודד. אתה יכול ליצור רשימות פרמטרים על ידי שכללים של שכבות שונות, או בהם הפרמטר הוא משקל או עקלת, בעזרת הפונקציית named_parameters() שסיפרנו עליה למעלה.
תכנון קצבי למידה
תכנון קצבי הלמידה שלך יעבור הוא ההיפרפארמטר העיקרי שאתה רוצה לשינוי. פייטורך מספקת תמיכה בתכנון קצבי הלמידה בעזרת מודול torch.optim.lr_scheduler שיש בו סדרות קצבי הלמידה מגוונים. הדוגמה הבאה מדגימה אחת מהסדרות האלה.
הסדרנר העל, מרבה את קצב הלמידה בעזרת gamma בכל פעם שאנחנו מגיעים לעונה שבתוך רשימת milestones. במקרה שלנו, קצב הלמידה מוכפל ב-0.1 בעונה ה-10n וה-20n. תצטרכו גם לכתוב את השורה scheduler.step בלול של הקוד שלכם שעובר על העונות כך שקצב הלמידה ייעדף.
בעיקר, מעגל ההדרכה מורך משתי מעגלים פנומנים, בהם אחד מעגלים על העונות והשני על העותקים בעונה. תוודאו שתקראו scheduler.step בתחילת מעגל העונה כך שקצב הלמידה ייעדף. תהיו מזהים ולא לכתוב אותו במעגל העותקים, אחרת קצב הלמידה עשוי להיעדף בעותק ה-10 במקום עונת ה-10n.
אז תזכרו שscheduler.step אינו החלף לoptim.step ותצטרכו לקרוא optim.step בכל פעם שתדביקו אחורנית. (זה יהיה במעגל העותקים).
שימור המודל שלך
אולי תרצו לשמור את המודל שלך עבור השימוש בהבחנה בעת מאוחר יותר, או רק על מנת ליצור עמדות ביישום ההדרכה. כשמדברים על שימור מודלים בPyTorch, יש לך שתי אפשרויות.
הראשונה היא להשתמש בtorch.save. זה בעל המשמעות של סיריאלצייצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציאצציא
העליצה ללא הערכים תשמר את כל המודל עם המשקלים והארכיטקטורה. אם רק צריך לשמור על המשקלים, במקום לשמור על כל המודל, ניתן לשמור רק על state_dict של המודל. state_dict הוא בעצם מילון שמתאים עצמו לאובייקטים nn.Parameter של רשת לערכיהם.
כפי שהודגמה למעלה, אתה יכול להטעין מידע state_dict קיים לתוך אובייקט nn.Module. שימו לב שזה לא מעניק שימור של כל המודל אלא רק של המפרמטרים. תצטרך ליצור את הרשת עם השכבות לפני שימוש ב state_dict. אם הארכיטקטורה של הרשת אינה בדיוק אותה שבה state_dict שנשמר, פיטורך יזריק שגיאה.
אובייקט מתקן מערכים מקטגורית torch.optim גם יש לו state_dict שמשמש לאחסן את ההיפרפרמטרים של אלגוריתמים העילוי. הוא יכול להישמר ולהודגמן באותה דרך שהבאה על ידי קריאה ל load_state_dict על אובייקט מתקן מערכים.
סיכום
זה סיים את הדיון שלנו על חלק מהתכונות המתקדמות של פיטורך. אני מקווה שהדברים שקראת בהם במאמר יעזרו לך ליישם רעיונות עמוקים בלמידת עופרת שחיברת לעצמך. הנה קישורים ללימוד נוספים אם תרצו.
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced