













Introducción
Hola lectores, esto es otra publicación en una serie que estamos haciendo con PyTorch. Esta publicación está dirigida a usuarios de PyTorch que están familiarizados con los conceptos básicos de PyTorch y que quieren avanzar hacia un nivel intermedio. Aunque hemos cubierto cómo implementar un clasificador básico en una publicación anterior, en esta publicación, discutiremos cómo implementar funcionalidades de aprendizaje profundo más complejas utilizando PyTorch. Algunos de los objetivos de esta publicación son hacerte entender.
- ¿Cuál es la diferencia entre las clases de PyTorch como
nn.Module,nn.Functional,nn.Parametery cuándo usar cada una? - Cómo personalizar tus opciones de entrenamiento, como diferentes tasas de aprendizaje para diferentes capas, diferentes programas de tasa de aprendizaje
- Inicialización personalizada de pesos
Así que vamos a empezar.
nn.Module vs nn.Functional
Esto es algo que aparece bastante especialmente cuando estás leyendo código de origen abierto. En PyTorch, las capas son a menudo implementadas como una de las siguientes: objetos de torch.nn.Module o funciones de torch.nn.Functional. ¿Qué usar? ¿Cuál es mejor?
Como habíamos cubierto en la Parte 2, torch.nn.Module es básicamente la piedra angular de PyTorch. La manera en que funciona es que primero definimos un objeto nn.Module, y luego lo invocamos mediante su método forward para ejecutarlo. Esta es una manera de Orientación a Objetos de hacer cosas.
Por otra parte, nn.functional proporciona algunas capas / activaciones en forma de funciones que se pueden llamar directamente sobre la entrada en lugar de definir un objeto. Por ejemplo, para escalar una imagen tensor, se llama torch.nn.functional.interpolate sobre un tensor de imagen.
¿Entonces cómo elegimos lo que usar cuando? Cuando la capa / activación / pérdida que estamos implementando tiene una pérdida.
Comprender la Estado-dad
Normalmente, cualquier capa se puede ver como una función. Por ejemplo, una operación convolucional es solo un montón de operaciones de multiplicación y suma. Así que tiene sentido que lo implementemos como una función, ¿verdad? Pero espera, la capa mantiene pesos que necesitan ser almacenados y actualizados mientras estamos entrenando. Por lo tanto, desde un ángulo programático, una capa es más que una función. También necesita mantener datos que cambian conforme entrenamos nuestra red.
Ahora quiero que hables de que hecho que los datos manejados por la capa convolucional cambian. Esto significa que la capa tiene un estado que cambia conforme entrenamos. Para implementar una función que realice la operación de convolución, también necesitaríamos definir una estructura de datos para mantener los pesos de la capa separadamente de la función misma. Y luego, hacer que esta estructura de datos externa sea un input para nuestra función.
O simplemente para evitar el alboroto, podríamos definir una clase para mantener la estructura de datos y hacer que la operación de convolución sea una función miembro. Esto realmente simplificaría nuestro trabajo, ya que no tendríamos que preocuparnos por variables estadofuertes que existan fuera de la función. En estos casos, preferiríamos utilizar los objetos nn.Module donde tenemos pesos o otros estados que podrían definir el comportamiento de la capa. Por ejemplo, una capa de dropout / Batch Norm se comporta de forma diferente durante el entrenamiento y la inferción.
Por otro lado, donde no se requieren estados o pesos, podría utilizarse nn.functional. Los ejemplos son, redimensionar (nn.functional.interpolate), piscina de promedio (nn.functional.AvgPool2d).
A pesar de la razon anterior, la mayoría de las clases nn.Module tienen sus contrapartes en nn.functional. Sin embargo, la línea de razonamiento anterior debe respetarse durante el trabajo práctico.
nn.Parameter
Una clase importante en PyTorch es la clase nn.Parameter, que por supuesto, ha recibido poca cobertura en los textos de inicio de PyTorch. Consideremos el siguiente caso.
Cada nn.Module tiene una función parameters() que devuelve, bien, sus parámetros entrenables. Tenemos que definirlos implícitamente. En la definición de nn.Conv2d, los autores de PyTorch definen los pesos y sesgos como parámetros de esa capa. Sin embargo, note una cosa, que cuando definimos net, no teníamos que agregar los parameters de nn.Conv2d a los parameters de net. Eso ocurrió implícitamente al poner el objeto nn.Conv2d como miembro del objeto net.
Esto es facilitado internamente por la clase nn.Parameter, que es una subclase de la clase Tensor. Cuando llamamos a la función parameters() de un objeto nn.Module, devuelve todos sus miembros que son objetos nn.Parameter.
De hecho, todos los pesos de entrenamiento de las clases nn.Module se implementan como objetos nn.Parameter. Cada vez que se asigna un nn.Module (nn.Conv2d en nuestro caso) como miembro de otro nn.Module, los “parámetros” del objeto asignador (es decir, los pesos de nn.Conv2d) también se agreguen los “parámetros” del objeto al que se asigna (parámetros del objeto net). Esto se denomina registro de “parámetros” de un nn.Module.
Si intentas asignar un tensor a la variable nn.Module, no aparecerá en la función parameters() a menos que lo defines como un objeto nn.Parameter. Esto se ha hecho para facilitar escenarios en los que pueda necesitar almacenar un tensor no diferenciable, por ejemplo, almacenar el salida previa en caso de RNNs.
nn.ModuleList y nn.ParameterList()
Recuerdo que tuve que usar una nn.ModuleList cuando estaba implementando YOLO v3 en PyTorch. Tenía que crear la red leyendo un archivo de texto que contenía la arquitectura. Almacené todos los objetos nn.Module correspondientes en una lista de Python y luego hice que la lista fuera un miembro de mi objeto nn.Module que representa la red.
Para simplificarlo, algo como esto.
Como puede ver, a diferencia de cuando registramos módulos individuales, asignar una Lista de Python no registra los parámetros de los Módulos dentro de la lista. Para corregir esto, envuelve nuestra lista con la clase nn.ModuleList y luego la asigna como un miembro de la clase de red.
De forma similar, una lista de tensores puede registrarse envuelviéndola dentro de una clase nn.ParameterList.
Inicialización de Pesos
La inicialización de pesos puede influir en los resultados de su entrenamiento. Además, es posible que requiera diferentes esquemas de inicialización de pesos para diferentes tipos de capas. Esto se puede lograr mediante las funciones modules y apply. modules es una función miembro de la clase nn.Module que devuelve un iterador que contiene todos los objetos miembros nn.Module de una función nn.Module. A continuación, se puede llamar a la función apply en cada nn.Module para establecer su inicialización.
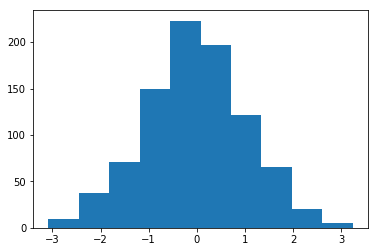
Histograma de pesos inicializados con Media = 1 y Desvío estándar = 1
Hay una amplia gama de funciones de inicialización inplace que se pueden encontrar en el módulo torch..nn.init.
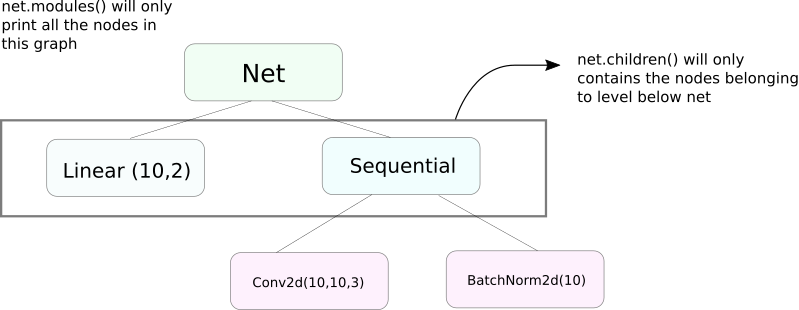
funciones_módulos() vs children()
Una función muy similar a modules es children. La diferencia es pequeña pero importante. Como sabemos, un objeto nn.Module puede contener otros objetos nn.Module como miembros de datos.
children() solo devuelve una lista de los objetos nn.Module que son miembros de datos del objeto en el que se está llamando children.
Al otro lado, nn.Modules entra recursivamente en cada objeto nn.Module, creando una lista de cada objeto nn.Module que se encuentra en el camino hasta que no quedan más objetos nn.module. Tenga en cuenta que modules() también devuelve el nn.Module en el que se ha llamado como parte de la lista.
Tenga en cuenta que el anterior enunciado sigue siendo verdadero para todos los objetos / clases que heredan de la clase nn.Module.
Así, cuando inicializamos los pesos, podríamos querer usar la función modules() ya que no podemos entrar en el objeto nn.Sequential y inicializar el peso para sus miembros.
Impresión de Información Sobre la Red
Puede que necesitemos imprimir información sobre la red, ya sea para el usuario o para propósitos de depuración. PyTorch proporciona una manera muy elegante de imprimir mucha información sobre nuestra red utilizando sus funciones named_*. Existen 4 funciones de este tipo.
named_parameters. Devuelve un iterador que proporciona una tupla que contiene nombre de los parámetros (si se asigna una capa convolucional comoself.conv1, entonces sus parámetros seríanconv1.weightyconv1.bias) y el valor devuelto por la función__repr__delnn.Parameter
2. named_modules. Igual que arriba, pero el iterador devuelve módulos como la función modules() lo hace.
3. named_children Igual que arriba, pero el iterador devuelve módulos como la función children() devuelve.
4. named_buffers Devuelve tensores de buffer como el promedio de running mean de una capa de Normalización por lotes.
Diferentes Tazas de Aprendizaje para Diferentes Capas
En esta sección, aprenderemos cómo usar diferentes tazas de aprendizaje para nuestras diferentes capas. En general, cubriremos cómo tener diferentes hiperparámetros para diferentes grupos de parámetros, ya sea que sea una tasa de aprendizaje diferente para diferentes capas o una tasa de aprendizaje diferente para términos de bias y pesos.
La idea de implementar algo así es bastante simple. En nuestro post anterior, donde implementamos un clasificador CIFAR, pasamos todos los parámetros de la red como un todo al objeto optimizador.
Sin embargo, la clase `torch.optim` nos permite proporcionar diferentes conjuntos de parámetros con diferentes tasas de aprendizaje en forma de un diccionario.
En el escenario anterior, los parámetros de `fc1` utilizan una tasa de aprendizaje de 0.01 y un momentum de 0.99. Si un hiperparámetro no está especificado para un grupo de parámetros (como `fc2`), utilizan el valor predeterminado de ese hiperparámetro, dado como argumento de entrada a la función optimizadora. Podría crear listas de parámetros en base a diferentes capas, o ya sea si el parámetro es una ponderación o un error, utilizando la función `named_parameters()` que cubrimos anteriormente.
Planificación de la Tasa de Aprendizaje
La programación de su tasa de aprendizaje va a seguir es un hiperparámetro importante que desea ajustar. PyTorch proporciona soporte para la programación de tasas de aprendizaje con su módulo `torch.optim.lr_scheduler` que tiene una variedad de programaciones de tasa de aprendizaje. El siguiente ejemplo demuestra un ejemplo de este tipo.
El planificador de arriba, multiplica la tasa de aprendizaje por gamma cada vez que llegamos a los epochs contenidos en la lista milestones. En nuestro caso, la tasa de aprendizaje se multiplica por 0.1 en los epochs 10n y 20n. También tendrás que escribir la línea scheduler.step en el bucle de tu código que recorre los epochs para que la tasa de aprendizaje se actualice.
Generalmente, el bucle de entrenamiento se compone de dos bucles anidados, donde uno recorre los epochs y el otro anidado recorre las batchs en esos epochs. Asegúrate de llamar a scheduler.step al inicio del bucle de los epochs para que tu tasa de aprendizaje se actualice. Teng cuidado de no escribirlo en el bucle de batch, de lo contrario tu tasa de aprendizaje podría actualizarse en el batch 10 en lugar del 10n epoch.
También recuerda que scheduler.step no es una sustitución para optim.step y tendrás que llamar a optim.step cada vez que realices backpropagation hacia atrás. (Esto estaría en el “batch” loop).
Guardando tu Modelo
Puede que quieras guardar tu modelo para usarlo posteriormente para inferencia, o simplemente puede que quieras crear puntos de control de entrenamiento. Cuando se trata de guardar modelos en PyTorch, tiene dos opciones.
La primera es utilizar torch.save. Esto es equivalente a serializar todo el objeto nn.Module usando Pickle. Este método guarda todo el modelo en el disco. Puedes cargar este modelo en la memoria posteriormente con torch.load.
El texto superior guardará todo el modelo con pesos y arquitectura. Si solo necesita guardar los pesos, en lugar de guardar todo el modelo, puede guardar solo el state_dict del modelo. El state_dict es básicamente un diccionario que mapea los objetos nn.Parameter de una red a sus valores.
Como se demostró arriba, uno puede cargar un state_dict existente en un objeto nn.Module. Tenga en cuenta que esto no implica guardar todo el modelo, sólo los parámetros. Tendrá que crear la red con capas antes de cargar el state dict. Si la arquitectura de la red no es exactamente la misma que la del state_dict que guardamos, PyTorch lanzará un error.
Un objeto optimizador de torch.optim también tiene un objeto state_dict que se utiliza para almacenar los hiperparámetros de los algoritmos de optimización. Puede guardar y cargar de manera similar a la que hicimos arriba llamando load_state_dict en un objeto optimizador.
Conclusión
Este completa nuestra discusión sobre algunas de las características avanzadas de PyTorch. Espero que las cosas que ha leído en este post le ayuden a implementar ideas complejas de aprendizaje profundo que podría haber ideado. Aquí están los enlaces para estudios posteriores si estás interesado.
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced