













Introduzione
Ciao lettori, questo è un altro post di una serie dedicata a PyTorch. Questo post è rivolto agli utenti di PyTorch che sono già familiarizzati con i fondamenti del framework e che desiderano approfondire a un livello intermedio. benché abbiamo spiegato come implementare un semplice classificatore in un precedente post, in questo articolo discuteremo come implementare funzionalità di apprendimento profondo più complicate utilizzando PyTorch. Alcuni degli obiettivi di questo post sono quelli di aiutarti a comprendere:
- La differenza tra le classi di PyTorch come
nn.Module,nn.Functional,nn.Parametere quando usare ciascuna di esse - Come personalizzare le opzioni di addestramento, come ad esempio differenti tassi di apprendimento per diverse layer o diversi programmi di tasso di apprendimento
- Inizializzazione personalizzata del peso
Quindi, cominciamo.
nn.Module contro nn.Functional
Questo è un elemento che compare spesso, specialmente quando si leggono codici open source. In PyTorch, le layer sono spesso implementate come oggetti di uno tra torch.nn.Module o come funzioni torch.nn.Functional. Qual’è la differenza? Qual’è la migliore scelta?
Come abbiamo visto nella Parte 2, torch.nn.Module costituisce la base fondamentale di PyTorch. Il modo in cui funziona è che prima definiamo un oggetto nn.Module, e poi lo invochiamo tramite il suo metodo forward per farlo funzionare. Questo è un approcio orientato agli oggetti.
D’altro canto, nn.functional fornisce alcune layer/attivazioni sotto forma di funzioni che possono essere chiamate direttamente sull’input invece di definire un oggetto. Per esempio, per riportare un tensore di immagine ad una scala specifica, chiamiamo torch.nn.functional.interpolate su un tensore di immagine.
Quindi come scegliamo ciò che usare in determinate situazioni? Quando la layer/attivazione/perdita che stiamo implementando ha una perdita.
Comprendere l’aspetto stateless-ness
Normalmente, ogni layer può essere visto come una funzione. Per esempio, un’operazione convoluzionale è solo un insieme di operazioni di moltiplicazione e somma. Quindi, può sembrare logicamente implementarla come una funzione? Ma aspetta, la layer conserva pesi che devono essere memorizzati e aggiornati durante l’addestramento. Quindi, dal punto di vista programmatico, una layer è più di una funzione. Deve anche conservare dati che cambiano mentre addestriamo il nostro network.
Ora voglio sottolineare il fatto che i dati tenuti dalla scansione convoluzionale Cambiano . Questo significa che la scansione ha un Stato che cambia mentre addestriamo. Per implementare una funzione che esegue l’operazione di scansione, dovremmo anche definire una struttura dati per tenere i pesi dell’ strato separatamente dalla funzione stessa. E poi, rendere questa struttura dati esterna un input per nostra funzione.
O per semplicare le cose, potremmo semplicemente definire una classe per tenere la struttura dati e rendere l’operazione di scansione un membro di questa classe. Questo farebbe davvero semplificare il nostro lavoro, in quanto non dovremmo preoccuparci di variabili statiche esterni alla funzione. In questi casi, preferiremmo usare gli oggetti nn.Module nei quali ci sono i pesi o altri stati che potrebbero definire il comportamento dell’ strato. Ad esempio, una scansione Dropout / Batch Norm si comporta diversamente durante l’ addestramento e nell’ inferenza.
Dall’ altra parte, dove non sono richiesti stati o pesi, si può usare nn.functional. Esempi sono, la reintegrazione (nn.functional.interpolate), l’ iniezione di tasselli (nn.functional.AvgPool2d).
Nonostante le ragioni sopra indicate, la maggior parte delle classi nn.Module ha i corrispondenti di nn.functional. Tuttavia, la linea di ragionamento sopra deve essere rispettata durante il lavoro pratico.
nn.Parameter
Una classe importante in PyTorch è la classe nn.Parameter, che a mia sorpresa, ha avuto poca copertura nei testi di introduzione a PyTorch. Considerate il seguente caso.
Ogni nn.Module ha una funzione parameters() che restituisce, beh, i suoi parametri trainabili. Dobbiamo definire implicitamente cosa sono questi parametri. Nella definizione di nn.Conv2d, gli autori di PyTorch hanno definito i pesi e i bias come parametri di una layer. Tuttavia, notate una cosa, quando abbiamo definito net, non abbiamo bisogno di aggiungere i parameters di nn.Conv2d ai parameters di net. È successo implicitamente grazie al fatto che abbiamo impostato l’oggetto nn.Conv2d come membro dell’oggetto net.
Questo è facilitato internamente dalla classe nn.Parameter, che estende la classe Tensor. Quando chiamiamo la funzione parameters() di un oggetto nn.Module, restituisce tutto il suo membro che è un oggetto nn.Parameter.
Anzi, tutti i pesi di addestramento delle classi nn.Module sono implementati come oggetti nn.Parameter. Ogni volta che un nn.Module (nn.Conv2d nel nostro caso) è assegnato come membro di un altro nn.Module, i “parametri” dell’oggetto assegnatario (ovvero i pesi di nn.Conv2d) vengono anche aggiunti ai “parametri” dell’oggetto a cui è assegnato (parametri dell’oggetto net). Questo si chiama registrazione dei “parametri” di un nn.Module.
Se cercate di assegnare un tensore ad un oggetto nn.Module, non apparirà nell’elenco delle parameters() se non lo definite come un oggetto nn.Parameter. Questo è stato fatto per facilitare scenari in cui potreste aver bisogno di cacheare un tensore non differenziale, ad esempio nel caso in cui si cache l’output precedente in caso di RNN.
nn.ModuleList e nn.ParameterList()
Ricordo di aver dovuto usare una nn.ModuleList quando implementavo YOLO v3 in PyTorch. Dovevo creare la rete interpretando un file di testo che conteneva l’architettura. Ho salvato tutti gli oggetti nn.Module corrispondenti in una lista Python e poi ho reso la lista un membro dell’oggetto nn.Module che rappresenta la rete.
Per semplificare, qualcosa come questo.
Come vedete, a differenza del momento in cui registreremo moduli individuali, assegnare una Lista Python non registra i parametri degli stessi Moduli all’interno della lista. Per correggere questo, incapsuliamo la nostra lista nella classe nn.ModuleList e poi la assegniamo come membro della classe del network.
Analogamente, una lista di tensori può essere registrata incapsulando la lista in una classe nn.ParameterList.
Inizializzazione del Peso
L’inizializzazione del peso può influenzare i risultati del tuo training. Eppure, potresti richiedere diversi schemi di inizializzazione del peso per diverse tipologie di layer. Questo può essere realizzato tramite le funzioni modules e apply. modules è una funzione membro della classe nn.Module che restituisce un iteratore che contiene tutti i membri oggetti nn.Module di una funzione nn.Module. Poi, è possibile richiamare la funzione apply su ciascun nn.Module per impostare la sua inizializzazione.
Histogram of weights initialised with Mean = 1 and Std = 1
Nella modulo torch..nn.init si possono trovare un mucchio di funzioni di inizializzazione in-place.
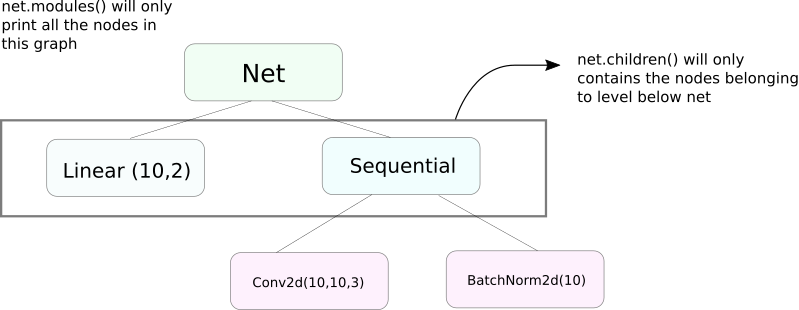
moduli() contro figli()
Una funzione molto simile a moduli è figli. La differenza è lieve ma importante. Come sappiamo, un oggetto nn.Module può contenere altri oggetti nn.Module come membri dati.
figli() restituirà solo una lista di oggetti nn.Module che sono membri dati dell’oggetto su cui viene chiamato figli.
D’altro canto, nn.Modules va ricorsivamente all’interno di ogni oggetto nn.Module, creando una lista di ogni oggetto nn.Module che viene incluso nel percorso fino a quando non restano più oggetti nn.module. Notare, moduli() restituisce anche l’nn.Module su cui è stato chiamato come parte della lista.
Notare che il precedente punto rimane vero per tutti gli oggetti / classi che estendono la classe nn.Module.
Quindi, quando inizializziamo i pesi, potremmo voler usare la funzione moduli() poiché non possiamo andare all’interno dell’oggetto nn.Sequential e inizializzare il peso per i suoi membri.
Stampa Informazioni Sulle Reti
Potremmo aver bisogno di stampare informazioni sulla rete, sia per l’utente che per scopi di debug. PyTorch offre un modo molto elegante per stampare molte informazioni sulla nostra rete utilizzando le sue funzioni named_*. Esistono 4 funzioni simili.
named_parameters. Restituisce un iteratore che fornisce una tupla contenente il nome dei parametri (se una layer convoluzionale è assegnata comeself.conv1, allora i suoi parametri sarebberoconv1.weighteconv1.bias) e il valore restituito dalla funzione__repr__dell’nn.Parameter
2. named_modules. Come sopra, ma l’iteratore restituisce moduli come la funzione modules() lo fa.
3. named_children Come sopra, ma l’iteratore restituisce moduli come la funzione children() restituisce.
4. named_buffers Restituisce tensori buffer come la media mobile del layer di batch norm.
Different Learning Rates For Different Layers
In questa sezione, impareremo come utilizzare diversi tassi di apprendimento per le nostre diverse layer. In generale, tratteremo come gestire diversi hyperparametri per diversi gruppi di parametri, sia diversi tassi di apprendimento per diverse layer, o diversi tassi di apprendimento per bias e pesi.
L’idea di implementare una cosa del genere è piuttosto semplice. Nell’articolo precedente, in cui abbiamo implementato un classificatore CIFAR, abbiamo passato tutti i parametri della rete come un insieme intero all’oggetto optimizzatore.
Tuttavia, la classe torch.optim ci permette di fornire diversi insiemi di parametri con differenti tassi di apprendimento in forma di un dizionario.
Nel caso precedente, i parametri di `fc1` usano un tasso di apprendimento di 0.01 e un momento di 0.99. Se un iperparmetro non è specificato per un gruppo di parametri (come `fc2`), essi usano il valore predefinito di quel iperparmetro, fornito come argomento input alla funzione optimizer. Puoi creare liste di parametri in base alle diverse layer o al fatto che il parametro sia un peso o un bias, usando la funzione named_parameters() che abbiamo visto prima.
Pianificazione del Tasso di Apprendimento
Pianificare il tuo tasso di apprendimento sarà un iperparmetro principale che vorrai adattare. PyTorch offre supporto per la pianificazione del tasso di apprendimento tramite il suo modulo torch.optim.lr_scheduler, che include una varietà di pianificazioni del tasso di apprendimento. L’esempio seguente dimostra un esempio del genere.
L’scheduler citato multiplica il tasso di apprendimento per gamma ogni volta che raggiungiamo gli epoch contenuti nella lista milestones. Nel nostro caso, il tasso di apprendimento viene moltiplicato per 0.1 agli epoch 10n e 20n. Devi anche scrivere la riga scheduler.step nel loop del tuo codice che si occupa degli epoch per aggiornare il tasso di apprendimento.
Di solito, il loop di addestramento è composto da due loop annidati, uno per gli epoch e l’altro per i batch di ciascun epoch. Assicurati di chiamare scheduler.step all’inizio del loop degli epoch così il tuo tasso di apprendimento viene aggiornato. Bada a come non lo scrivi nel loop del batch, altrimenti il tuo tasso di apprendimento potrebbe essere aggiornato al 10° batch invece che al 10n° epoch.
ricorda anche che scheduler.step non è un sostituto per optim.step e devi chiamare optim.step ogni volta che fai backprop. (Ciò sarebbe nel loop “batch”).
Salvataggio del tuo Modello
Potresti voler salvare il tuo modello per usarlo in futuro per le inferenze, o forse solo per creare punti di controllo dell’addestramento. Quando si tratta di salvare i modelli in PyTorch, ci sono due opzioni.
La prima è usare torch.save. Questo è equivalente a serializzare l’intero oggetto nn.Module usando Pickle. Salva l’intero modello sul disco. Puoi caricare questo modello in memoria più tardi con torch.load.
La riga precedente salverà l’intero modello con i pesi e l’architettura. Se solo devi salvare i pesi, invece di salvare l’intero modello, puoi salvare solo lo state_dict del modello. Lo state_dict è in sostanza un dizionario che mappa gli oggetti nn.Parameter di una rete ai loro valori.
Come mostrato sopra, è possibile caricare un esistente state_dict in un oggetto nn.Module. Notare che questo non comporta la salvataggio dell’intero modello ma solo i parametri. Devi creare la rete con le layer prima di caricare lo state dict. Se l’architettura della rete non è esattamente la stessa di quella dalla quale abbiamo salvato lo state_dict, PyTorch lancierà un errore.
Un oggetto ottimizzatore da torch.optim anche ha un oggetto state_dict che viene usato per memorizzare iiperparametri degli algoritmi di ottimizzazione. Può essere salvato e caricato in maniera simile a quella descritta prima chiamando load_state_dict su un oggetto ottimizzatore.
Conclusione
Questo conclude la nostra discussione su alcune delle caratteristiche avanzate di PyTorch. Spero che le cose che hai letto in questo post ti aiuteranno a implementare idee complesse di apprendimento profondo che potresti aver concepito. Ecco i link per ulteriori studi se sei interessato.
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced