













引言
讀者們好,這是在我們對PyTorch進行的一系列文章中的另一篇文章。這篇文章是為熟悉PyTorch基本概念並希望进一步提升的用戶而寫的。雖然我們在早前的文章中已經 covered 了如何實現一個基本的分類器,但在這篇文章中,我們將討論如何使用PyTorch實現更複雜的深度學習功能。這篇文章的一些目標是让您了解。
- PyTorch類如
nn.Module、nn.Functional、nn.Parameter之間的差異以及何時使用何者 - 如何自定義您的訓練選項,例如為不同層次使用不同的學習速率、不同的學習率計劃
- 自定義權重初始化
那麼,讓我們開始吧。
nn.Module與nn.Functional
這在工作中尤其常見,特別是當您閱讀開源代码時。在PyTorch中,層次通常作為torch.nn.Module物件或torch.nn.Functional函數實現。應該使用哪個?哪個比较好?
在第二部分中,我們已經提到了 torch.nn.Module 基本上是 PyTorch 的基石。它的運作方式是首先定義一個 nn.Module 物件,然後調用其 forward 方法來運行它。这是一种面向对象的做事方式。
另一方面,nn.functional 提供了一些以函數形式存在的層/激活,可以直接調用於輸入,而不需要定義一個物件。例如,為了重縮放一個影像张量,你會對一個影像张量調用 torch.nn.functional.interpolate。
那麼,我們該如何選擇使用哪個呢?當我們实现的層/激活/损失有損失時。
理解有状态性
通常,任何層都可以看作是一個函數。例如,卷積操作只是一堆乘法和加法操作。所以,我們應該把它實現為一個函數才對吧?但等等,層持有權重需要在訓練時進行存儲和更新。因此,從程式的角度來看,層不僅僅是一個函數。它還需要持有在訓練網絡時会发生变化的數據。
我现在想要你強調一個事实,那就是卷積層持有的數據會變化。這意味著該層具有狀態,隨著我們的訓練而變化。為了實現卷積操作的函數,我們還需要定義一個數據結構來保存層的權重,與函數本身分開。然後,將這個外部數據結構作為我們的函數的輸入。
或者,為了省去麻煩,我們可以直接定義一個類來保存數據結構,並將卷積操作作為成員函數。這將真正簡化我們的任務,因為我們不必擔心函數外的有状态變量。在這些情況下,我們會更喜欢使用nn.Module物件,其中我們有權重或其他可能定義層行為的狀態。例如, Dropout / Batch Norm 層在訓練和推理時行為 differently.
另一方面,當不需要狀態或權重時,可以使用nn.functional。例如,調整大小(nn.functional.interpolate)、平均池化(nn.functional.AvgPool2d)。
儘管上有理由,大部分的nn.Module類都有其nn.functional對等物件。然而,上面線索的推理在實際工作中是要被尊重的。
nn.Parameter
在 PyTorch 中,一個重要的類別是 `nn.Parameter` 類別,這個類別在 PyTorch 的入门教科書中驚訝地被很少覆盖。考慮以下案例。
每個 `nn.Module` 都有一個 `parameters()` 函數,該函數返回,嗯,它就是可訓練的參數。我們必須隐式地定義這些參數是什麼。在 `nn.Conv2d` 的定義中,PyTorch 的作者將權重和偏置定義為層的 `parameters`。然而,注意一件事,當我們定義 `net` 时,我們不需要將 `nn.Conv2d` 的 `parameters` 添加到 `net` 的 `parameters`。這是由於將 `nn.Conv2d` 物件設定為 `net` 物件的成員而隐式地发生的。
這是由 `nn.Parameter` 類別 internally facilitated,該類別是 `Tensor` 類別的子類別。當我們呼叫 `parameters()` 函數一個 `nn.Module` 物件時,它返回所有它的成員,這些是 `nn.Parameter` 物件。
實際上,所有 `nn.Module` 類別的訓練權重都是實作為 `nn.Parameter` 物件。無論何時,一個 `nn.Module` (在我們的案例中是 `nn.Conv2d`)被指定為另一個 `nn.Module` 的成員,被指派物件的 “parameters”(即 `nn.Conv2d` 的權重)也被添加到正在指派的物件的 “parameters”(`net` 物件的參數)。這稱為註冊 `nn.Module` 的 “parameters”。
如果你嘗試將一個張量賦值給 `nn.Module` 物件,除非你將其定義為 `nn.Parameter` 物件,不然它不會在 `parameters()` 方法中顯示出來。這是為了方便在需要缓存一個非導數張量的情況,例如在 RNN 情況下緩存先前的輸出。
nn.ModuleList 和 nn.ParameterList()
我記得當我地在 PyTorch 中實現 YOLO v3 時,我必須使用 `nn.ModuleList`。我必須通過解析一個包含網絡結構的文本文件來創建網絡。我將所有相應的 `nn.Module` 物件存儲在一個 Python 列表中,然後將該列表作為我代表網絡的 `nn.Module` 物件的成員。
為了簡化,就像這樣。
正如你所見,與我們註冊单个模塊不同,將Python列表分配給模塊的參數 Inside the list does not register. To fix this, we wrap our list with the nn.ModuleList class, and then assign it as a member of the network class.
同理,可以通過將列表包裹在 nn.ParameterList 類內來註冊列表中的張量。
權重初始化
權重初始化可以影響你训緄的结果。而且,你可能需要為不同類型的層使用不同的權重初始化方案。這可以通過 modules 和 apply 函數來實現。modules 是 nn.Module 類的成員函數,返回包含 nn.Module 成員对象的迭代器,這些對象是一個 nn.Module 函數的成員。然後對每個 nn.Module 使用 apply 函數來設定其初始化。
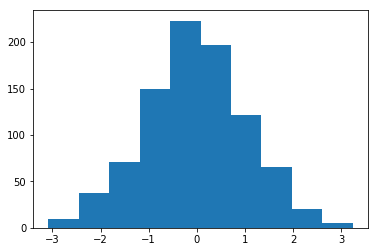
初始化均值為1、標準差為1的權重直方圖
在 torch..nn.init 模塊中可以找到許多在職初始化函數。
moduless() vs children()
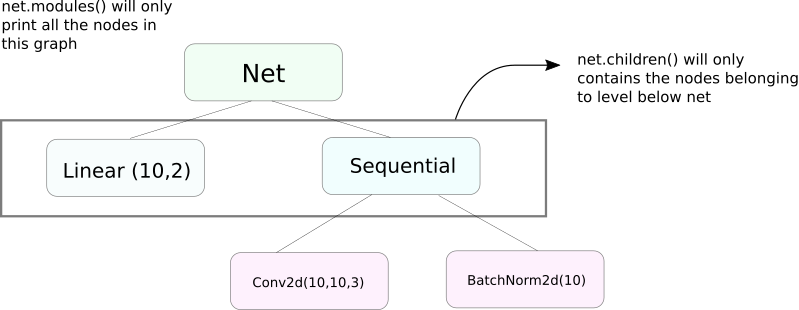
一个非常相似於moduless功能的函式是children。這兩個函式的差異雖然细微但非常重要的是。我們知道,一個nn.Module物件可以包含其他nn.Module物件作為其數據成員。
children()只會返回一個nn.Module物件列表,這些物件是對children被呼叫物件的數據成員。
另一方面,nn.Modules會遞迴地进入每個nn.Module物件內,建立一個每一個nn.Module物件的列表,直到沒有nn.module物件為止。注意,modules()也会將其被呼叫的nn.Module物件作為列表的一部分返回。
注意,上面這段描述對所有從nn.Module類別派生的物件/類別都成立。
所以,當我們初始化權重時,我們可能會想要使用modules()功能,因為我們無法進入nn.Sequential物件並初始化其成員的權重。
打印有關網絡的信息
我們可能需要印出有關網絡的信息,無論是給用戶還是用於调试目的。PyTorch提供了一個非常實用的方法,使用其named_*函數打印有關網絡的大量信息。有4個這樣的函數。
named_parameters。返回一個迭代器,該迭代器給出一個包含名稱的參數(如果一個卷積層被指定為self.conv1,那麼它的參數將是conv1.weight和conv1.bias)和nn.Parameter的__repr__函數返回的值
2. named_modules。與上方相同,但迭代器返回模塊
3. named_children與上方相同,但迭代器返回模塊,如同children()返回
4. named_buffers返回緩冲張量,如Batch Norm層的運行均值
不同層次使用不同學習率
在這一節中,我們將學習如何為我們的不同層次使用不同的學習率。通常,我們將涵蓋如何為不同層次或偏置和權重為不同 parameter groups 設定不同的超參數。
這個念頭實質上相当簡單。在我們之前的貼文裡,我們實現了一個CIFAR分類器,當時是把網絡的所有參數作為一個整體傳給優化器物件。
然而,`torch.optim` 類別讓我們可以提供一个不同學習率的參數集合的字典形式。
在上述情況中,`fc1` 的參數使用了 0.01 的學習率和 0.99 的momentum。如果對一個參數組(如 `fc2`)没指定超參數,它們將使用傳遞給優化器函數的超參數的默認值。你可以根據不同的層或者參數是權重還是偏置,使用我們上面介紹的 `named_parameters()` 函數創建參數列表。
學習率計劃
學習率的計劃是你要調節的一個主要超參數。PyTorch 提供了 `torch.optim.lr_scheduler` 模組來支持學習率的計劃,該模組具有各種學習率計劃。以下示例展示了一種類型的學習率計劃。
上述排程器每次在達到milestones清單中的汛期時,都會將學習率乘以gamma。在我們的案例中,在第10n個和第20n個汛期時,學習率會被乘以0.1。您還需要在您的代碼中寫入scheduler.step行,該行在汛期循環中,以便更新學習率。
通常,訓練循環由兩個嵌套循環組成,其中一个循環遍歷汛期,而嵌套的一个則遍歷該汛期的批次。請確保在汛期循環的開始處調用scheduler.step,以便更新您的學習率。請注意不要在批次循環中寫入,否则您的學習率可能會在第10個批次而不是第10n個汛期更新。
還記住scheduler.step並不是optim.step的替換品,您還需要在反向傳播向後時每次調用optim.step。 (這將是在“批次”循環中)。
保存您的模型
您可能想為後續的推理使用保存您的模型,或者可能只想創建訓練檢查點。當谈到在PyTorch中保存模型時,您有两个選擇。
第一個是使用torch.save。這等於使用Pickle序列化整個nn.Module物件。這將整個模型保存到磁盤上。您可以後續使用torch.load將此模型加載到記憶體中。
以上將儲存整個模型、權重和架構。如果您只需要保存權重,而不需要保存整個模型,您可以只保存模型的state_dict。state_dict基本上是一個字典,將網絡中的nn.Parameter物件映射到它們的值。
如上所示,您可以將现有的state_dict載入nn.Module物件中。注意,這不涉及保存整個模型,只是權重。在載入state_dict之前,您需要創建網絡層。如果網絡架構與我們保存state_dict的架构不完全相同,PyTorch將會扔出一個錯誤。
結論
這完成了我們對於PyTorch一些較進階特性的討論。我希望您在本篇文章中閱讀到的內容將幫助您實現可能的复雜深度學習想法。以下是一些進階學習的連結,如果您有興趣的話。
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced