













Как обсуждалось в моей предыдущей статье о архитектурах данных, подчеркивающих новые тенденции, обработка данных является одним из ключевых компонентов современной архитектуры данных. Эта статья обсуждает различные альтернативы библиотеке Pandas для повышения производительности вашей архитектуры данных.
Обработка данных и анализ данных являются решающими задачами в области науки о данных и инженерии данных. Поскольку наборы данных становятся все больше и сложнее, традиционные инструменты, такие как pandas, могут испытывать трудности с производительностью и масштабируемостью. Это привело к разработке нескольких альтернативных библиотек, каждая из которых предназначена для решения конкретных задач в манипуляции и анализе данных.
Введение
Следующие библиотеки стали мощными инструментами для обработки данных:
- Pandas – традиционный рабочий инструмент для манипуляции данными в Python
- Dask – расширяет pandas для обработки данных в больших объемах и распределенной среде
- DuckDB – встроенная аналитическая база данных для быстрых SQL-запросов
- Modin – замена pandas с улучшенной производительностью
- Полярные – библиотека высокой производительности DataFrame, построенная на Rust
- FireDucks – ускоренная компилятором альтернатива pandas
- Таблица данных – библиотека высокой производительности для манипулирования данными
Каждая из этих библиотек предлагает уникальные функции и преимущества, отвечая различным случаям использования и требованиям к производительности. Давайте подробнее рассмотрим каждую из них:
Pandas
Pandas – универсальная и хорошо установленная библиотека в сообществе данных. Он предлагает надежные структуры данных (DataFrame и Series) и обширные инструменты для очистки и преобразования данных. Pandas отличается в исследовании данных и визуализации, с обширной документацией и поддержкой сообщества.
Однако он сталкивается с проблемами производительности при работе с большими наборами данных, ограничен однопоточными операциями и может иметь высокое использование памяти при работе с большими наборами данных. Pandas идеален для небольших и средних наборов данных (до нескольких ГБ) и при необходимости обширной манипуляции и анализа данных.
Даск
Dask расширяет возможности pandas для обработки данных в крупномасштабном масштабе, предлагая параллельные вычисления на нескольких ядрах ЦПУ или кластерах, а также вычисления вне памяти для наборов данных, превышающих доступную оперативную память. Он масштабирует операции pandas для больших данных и хорошо интегрируется с экосистемой PyData.
Однако Dask поддерживает только подмножество API pandas и может быть сложным для настройки и оптимизации для распределенных вычислений. Он лучше всего подходит для обработки крайне больших наборов данных, которые не помещаются в память или требуют ресурсов распределенных вычислений.
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
Для повышения производительности, загружайте данные с помощью Dask используя
dd.from_dict(data, npartitions=4вместо датафрейма Pandasdd.from_pandas(df_pandas, npartitions=4)
Вывод
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
DuckDB
DuckDB — это аналитическая база данных в процессе выполнения, которая предлагает быстрые аналитические запросы с использованием колонно-ориентированного векторизованного движка запросов. Она поддерживает SQL с дополнительными функциями и не имеет внешних зависимостей, что делает настройку простой. DuckDB обеспечивает исключительную производительность для аналитических запросов и легкую интеграцию с Python и другими языками.
Однако она не подходит для высоконагруженных транзакционных рабочих нагрузок и имеет ограниченные возможности параллельного выполнения. DuckDB отлично справляется с аналитическими рабочими нагрузками, особенно когда предпочтительны SQL-запросы.
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
Вывод
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
Modin
Modin стремится стать заменой для pandas, используя несколько ядер процессора для более быстрой работы и масштабирования операций pandas на распределенных системах. Он требует минимальных изменений в коде для адаптации и предлагает потенциал для значительных улучшений скорости на многопроцессорных системах.
Однако Modin может иметь ограниченные улучшения производительности в некоторых сценариях и все еще находится в активной разработке. Он лучше всего подходит для пользователей, стремящихся ускорить существующие рабочие процессы pandas без значительных изменений в коде.
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
Выход
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polars — это библиотека DataFrame с высокой производительностью, построенная на Rust, с эффективной по памяти колонной структурой данных и API ленивой оценки для оптимизированного планирования запросов. Она предлагает исключительную скорость для задач обработки данных и масштабируемость для работы с большими наборами данных.
Однако у Polars другой API, чем у pandas, что требует некоторого обучения, и она может испытывать трудности с экстремально большими наборами данных (более 100 ГБ). Она идеально подходит для дата-сайентистов и инженеров, работающих со средними и большими наборами данных, которые придают значение производительности.
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
Выход
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
FireDucks предлагает полную совместимость с API pandas, многопоточное выполнение и ленивое выполнение для эффективной оптимизации потока данных. Она включает компилятор времени выполнения, который оптимизирует выполнение кода, обеспечивая значительные улучшения производительности по сравнению с pandas. FireDucks позволяет легко адаптироваться благодаря своей совместимости с API pandas и автоматической оптимизации операций с данными.
Тем не менее, это относительно новая библиотека и может иметь меньше поддержки сообщества и ограниченную документацию по сравнению с более устоявшимися библиотеками.
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
Вывод
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
Datatable
Datatable – это высокопроизводительная библиотека для манипуляции данными, которая предлагает колонноориентированное хранение данных, реализацию на чистом C для всех типов данных и многопоточную обработку данных. Она обеспечивает исключительную скорость для задач обработки данных, эффективное использование памяти и предназначена для работы с большими наборами данных (до 100 ГБ). API Datatable аналогичен data.table в R.
Тем не менее, у нее менее полная документация по сравнению с pandas, меньше функций и она не совместима с Windows. Datatable идеально подходит для обработки больших наборов данных на одном компьютере, особенно когда скорость имеет решающее значение.
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
Вывод
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
Сравнение производительности
- Загрузка данных: в 34 раза быстрее, чем pandas для набора данных объемом 5,7 ГБ
- Сортировка данных: в 36 раз быстрее, чем pandas
- Группировка операций: в 2 раза быстрее, чем pandas
Datatable превосходит в сценариях, связанных с обработкой данных в больших масштабах, предлагая значительные улучшения производительности по сравнению с pandas для операций, таких как сортировка, группировка и загрузка данных. Его многопоточные возможности обработки делают его особенно эффективным для использования современных многоядерных процессоров
Заключение
В заключение, выбор библиотеки зависит от таких факторов, как размер набора данных, требования к производительности и конкретные случаи использования. Хотя pandas остается универсальным для небольших наборов данных, альтернативы, такие как Dask и FireDucks, предлагают сильные решения для обработки данных в большом масштабе. DuckDB отлично справляется с аналитическими запросами, Polars обеспечивает высокую производительность для наборов данных среднего размера, а Modin нацелен на масштабирование операций pandas с минимальными изменениями в коде.
Гистограмма ниже показывает производительность библиотек, используя DataFrame для сравнения. Данные нормализованы для отображения процентов.
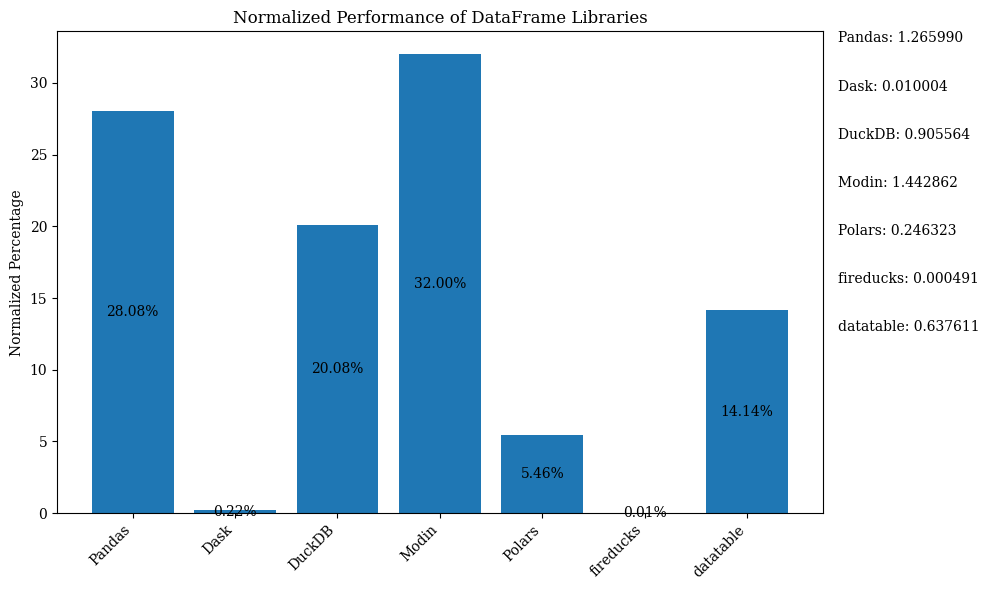
Для получения кода на Python, который показывает вышеуказанную гистограмму с нормализованными данными, обратитесь к Jupyter Notebook. Используйте Google Colab, так как FireDucks доступен только на Linux
Сравнительная таблица
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| Pandas | Умеренный | Низкий | Н/Д (оригинал) | Небольшие и средние наборы данных, исследование данных | Универсальность, богатая экосистема | Медленный с большими наборами данных, однопоточный |
| Dask | Высокий | Очень высокий | Высокий | Большие наборы данных, распределенные вычисления | Масштабирует операции pandas, распределенная обработка | Сложная настройка, частичная поддержка API pandas |
| DuckDB | Очень высокий | Умеренный | Низкий | Аналитические запросы, анализ на основе SQL | Быстрые SQL-запросы, легкая интеграция | Не для транзакционной нагрузки, ограниченная параллельность |
| Modin | Высокая | Высокая | Очень высокая | Ускорение существующих рабочих процессов pandas | Простое принятие, использование многоядерности | Ограниченные улучшения в некоторых сценариях |
| Polars | Очень высокая | Высокая | Умеренная | Средние и крупные наборы данных, критичные для производительности | Исключительная скорость, современный API | Крутая кривая обучения, проблемы с очень большими данными |
| FireDucks | Очень высокая | Высокая | Очень высокая | Большие наборы данных, API, похожее на pandas с производительностью | Автоматическая оптимизация, совместимость с pandas | Новая библиотека, меньшая поддержка сообщества |
| Datatable | Очень высокая | Высокая | Умеренная | Большие наборы данных на одном компьютере | Быстрая обработка, эффективное использование памяти | Ограниченный функционал, отсутствие поддержки Windows |
Эта таблица предоставляет быстрый обзор сильных сторон, ограничений и лучших случаев использования каждой библиотеки, позволяя легкое сравнение по различным аспектам, таким как производительность, масштабируемость и сходство API с pandas.
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas