













Comme discuté dans mon précédent article sur les architectures de données mettant l’accent sur les tendances émergentes, le traitement des données est l’un des éléments clés de l’architecture moderne des données. Cet article discute des différentes alternatives à la bibliothèque Pandas pour une meilleure performance dans votre architecture de données.
Le traitement des données et l’analyse des données sont des tâches cruciales dans le domaine de la science des données et de l’ingénierie des données. À mesure que les ensembles de données deviennent plus importants et plus complexes, les outils traditionnels comme pandas peuvent rencontrer des difficultés en termes de performance et de scalabilité. Cela a conduit au développement de plusieurs bibliothèques alternatives, chacune conçue pour relever des défis spécifiques en matière de manipulation et d’analyse des données.
Introduction
Les bibliothèques suivantes se sont imposées comme des outils puissants pour le traitement des données :
- Pandas – L’outil traditionnel pour la manipulation des données en Python
- Dask – Étend pandas pour le traitement de données à grande échelle et distribué
- DuckDB – Une base de données analytique en interne pour des requêtes SQL rapides
- Modin – Un remplacement direct de pandas avec des performances améliorées
- Polars – Une bibliothèque DataFrame haute performance construite en Rust
- FireDucks – Une alternative accélérée par le compilateur à pandas
- Datatable – Une bibliothèque haute performance pour la manipulation des données
Chacune de ces bibliothèques offre des fonctionnalités uniques et des avantages, répondant à différents cas d’utilisation et exigences de performance. Explorons chacune en détail :
Pandas
Pandas est une bibliothèque polyvalente et bien établie dans la communauté des sciences des données. Elle offre des structures de données robustes (DataFrame et Series) et des outils complets pour le nettoyage et la transformation des données. Pandas excelle dans l’exploration et la visualisation des données, avec une documentation étendue et un support de la communauté.
Cependant, elle rencontre des problèmes de performance avec de grands ensembles de données, est limitée aux opérations monofils, et peut avoir une utilisation élevée de la mémoire pour de grands ensembles de données. Pandas est idéal pour les ensembles de données de petite à moyenne taille (jusqu’à quelques Go) et lorsque des manipulations et analyses de données étendues sont nécessaires.
Dask
Dask étend pandas pour le traitement de données à grande échelle, offrant un calcul parallèle sur plusieurs cœurs CPU ou des clusters et une computation hors mémoire pour les ensembles de données plus grands que la RAM disponible. Il met à l’échelle les opérations pandas sur les big data et s’intègre bien à l’écosystème PyData.
Cependant, Dask ne prend en charge qu’un sous-ensemble de l’API pandas et peut être complexe à configurer et à optimiser pour le calcul distribué. Il est mieux adapté au traitement d’ensembles de données extrêmement volumineux qui ne rentrent pas en mémoire ou nécessitent des ressources de calcul distribué.
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
Pour de meilleures performances, chargez les données avec Dask en utilisant
dd.from_dict(data, npartitions=4à la place du dataframe Pandasdd.from_pandas(df_pandas, npartitions=4)
Résultat
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
DuckDB
DuckDB est une base de données analytique en processus qui offre des requêtes analytiques rapides en utilisant un moteur de requêtes vectorisé par colonnes. Il prend en charge SQL avec des fonctionnalités supplémentaires et ne présente aucune dépendance externe, rendant la configuration simple. DuckDB offre des performances exceptionnelles pour les requêtes analytiques et une intégration facile avec Python et d’autres langages.
Cependant, il n’est pas adapté aux charges de travail transactionnelles à volume élevé et offre des options de concurrence limitées. DuckDB excelle dans les charges de travail analytiques, surtout lorsque les requêtes SQL sont préférées.
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
Résultat
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
Modin
Modin vise à être un remplacement direct de pandas, en utilisant plusieurs cœurs de CPU pour une exécution plus rapide et en étendant les opérations pandas sur des systèmes distribués. Il nécessite des modifications de code minimales pour être adopté et offre un potentiel d’améliorations significatives de la vitesse sur des systèmes multi-cœurs.
Cependant, Modin peut avoir des améliorations de performance limitées dans certains scénarios et est encore en développement actif. Il est préférable pour les utilisateurs cherchant à accélérer les flux de travail pandas existants sans changements majeurs de code.
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
Sortie
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polars est une bibliothèque DataFrame haute performance construite sur Rust, présentant une disposition mémoire colonne efficace et une API d’évaluation paresseuse pour une planification de requêtes optimisée. Elle offre une vitesse exceptionnelle pour les tâches de traitement de données et une évolutivité pour gérer de grands ensembles de données.
Cependant, Polars a une API différente de celle de pandas, nécessitant un certain apprentissage, et peut avoir des difficultés avec des ensembles de données extrêmement volumineux (plus de 100 Go). Elle est idéale pour les scientifiques des données et les ingénieurs travaillant avec des ensembles de données de taille moyenne à grande qui privilégient la performance.
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
Sortie
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
FireDucks offre une compatibilité totale avec l’API pandas, une exécution multi-threadée et une exécution paresseuse pour une optimisation efficace du flux de données. Il dispose d’un compilateur à l’exécution qui optimise l’exécution du code, offrant des améliorations de performance significatives par rapport à pandas. FireDucks permet une adoption facile grâce à sa compatibilité avec l’API pandas et à l’optimisation automatique des opérations de données.
Cependant, il est relativement nouveau et peut avoir moins de support de la communauté et une documentation limitée par rapport aux bibliothèques plus établies.
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
Sortie
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
Datatable
Datatable est une bibliothèque haute performance pour la manipulation de données, offrant un stockage de données orienté colonne, une implémentation native en C pour tous les types de données, et un traitement de données multi-thread. Il offre une vitesse exceptionnelle pour les tâches de traitement des données, une utilisation efficace de la mémoire, et est conçu pour manipuler de grands ensembles de données (jusqu’à 100 Go). L’API de Datatable est similaire à celle de data.table de R.
Cependant, il dispose d’une documentation moins complète par rapport à pandas, moins de fonctionnalités, et n’est pas compatible avec Windows. Datatable est idéal pour le traitement de grands ensembles de données sur une seule machine, notamment lorsque la vitesse est cruciale.
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
Sortie
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
Comparaison des performances
- Chargement des données : 34 fois plus rapide que pandas pour un ensemble de données de 5,7 Go
- Tri des données : 36 fois plus rapide que pandas
- Opérations de regroupement : 2 fois plus rapide que pandas
Datatable excelle dans les scénarios impliquant le traitement de données à grande échelle, offrant des améliorations significatives de performance par rapport à pandas pour des opérations telles que le tri, le regroupement et le chargement de données. Ses capacités de traitement multi-thread en font une solution particulièrement efficace pour l’utilisation de processeurs multi-cœurs modernes
Conclusion
En conclusion, le choix de la bibliothèque dépend de facteurs tels que la taille de l’ensemble de données, les exigences de performance et les cas d’utilisation spécifiques. Alors que pandas reste polyvalent pour les ensembles de données plus petits, des alternatives comme Dask et FireDucks offrent des solutions solides pour le traitement de données à grande échelle. DuckDB excelle dans les requêtes analytiques, Polars offre de hautes performances pour les ensembles de données de taille moyenne, et Modin vise à mettre à l’échelle les opérations pandas avec des changements de code minimes.
Le diagramme à barres ci-dessous montre les performances des bibliothèques, en utilisant le DataFrame pour la comparaison. Les données sont normalisées pour montrer les pourcentages.
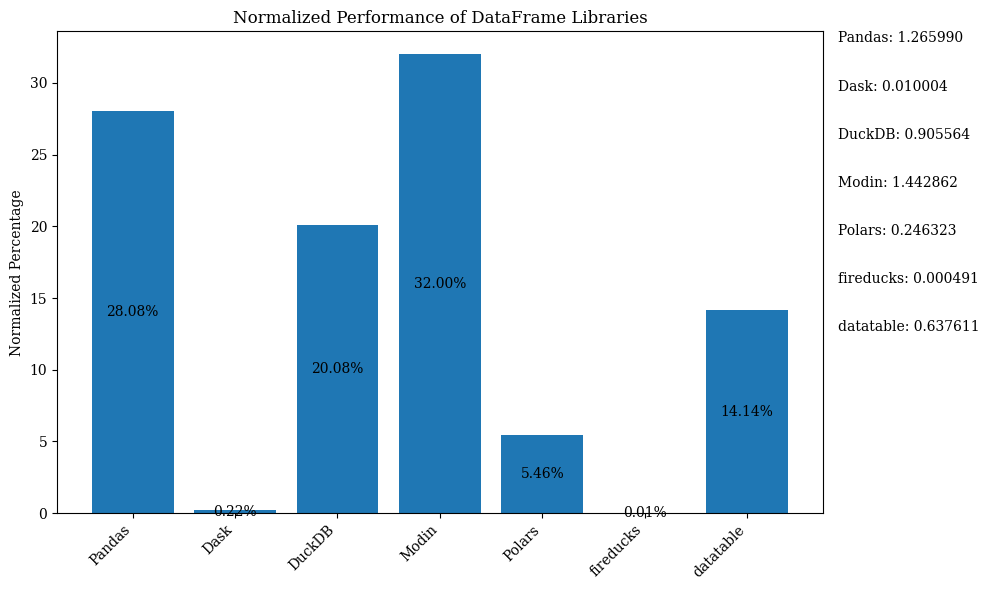
Pour le code Python qui montre le diagramme à barres ci-dessus avec des données normalisées, consultez le Carnet Jupyter. Utilisez Google Colab car FireDucks n’est disponible que sur Linux
Tableau Comparatif
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| Pandas | Modéré | Bas | N/A (Original) | Petits à moyens ensembles de données, exploration des données | Polyvalence, écosystème riche | Slow avec de grands ensembles de données, single-threaded |
| Dask | Élevée | Très élevée | Élevée | Grands ensembles de données, informatique distribuée | Met à l’échelle les opérations pandas, traitement distribué | Configuration complexe, support partiel de l’API pandas |
| DuckDB | Très élevée | Modérée | Bas | Requêtes analytiques, analyse basée sur SQL | Requêtes SQL rapides, intégration facile | Non adapté aux charges de travail transactionnelles, concurrence limitée |
| Modin | Élevé | Élevé | Très élevé | Accélérer les workflows pandas existants | Adoption facile, utilisation multi-core | Améliorations limitées dans certains scénarios |
| Polars | Très élevé | Élevé | Modéré | Jeux de données de taille moyenne à grande, critique en termes de performance | Vitesse exceptionnelle, API moderne | Courbe d’apprentissage, difficultés avec des données très volumineuses |
| FireDucks | Très élevé | Élevé | Très élevé | Jeux de données volumineux, API similaire à pandas avec performances | Optimisation automatique, compatibilité avec pandas | Nouvelle bibliothèque, moins de support de la communauté |
| Datatable | Très élevé | Élevé | Modéré | Jeux de données volumineux sur une seule machine | Traitement rapide, utilisation efficace de la mémoire | Fonctionnalités limitées, pas de prise en charge de Windows |
Ce tableau offre un aperçu rapide des forces, des limitations et des meilleurs cas d’utilisation de chaque bibliothèque, permettant une comparaison facile sur différents aspects tels que la performance, la scalabilité et la similarité de l’API avec pandas.
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas