













前回の記事で取り上げた新興トレンドを強調したデータアーキテクチャについて、データ処理は現代のデータアーキテクチャにおける主要な要素の一つです。この記事では、データアーキテクチャにおいてより優れたパフォーマンスを提供するPandasライブラリのさまざまな代替手段について議論します。
データ処理とデータ分析はデータサイエンスやデータエンジニアリングの重要なタスクです。データセットがより大きく複雑になるにつれ、Pandasなどの従来のツールはパフォーマンスとスケーラビリティに課題を抱えることがあります。これにより、データ操作と分析の特定の課題に対処するために設計されたいくつかの代替ライブラリの開発が進んでいます。
導入
以下のライブラリは、データ処理において強力なツールとして台頭しています:
- Pandas – Pythonにおけるデータ操作の伝統的な主力ツール
- Dask – 大規模かつ分散データ処理のためにPandasを拡張
- DuckDB – 高速なSQLクエリのためのインプロセス解析データベース
- Modin – パフォーマンスが向上したPandasの代替としての置換品
- Polars – Rust で構築された高性能な DataFrame ライブラリ
- FireDucks – pandas の代替となるコンパイラアクセラレーション
- Datatable – データ操作用の高性能ライブラリ
これらのライブラリは、異なるユースケースとパフォーマンス要件に対応したユニークな機能と利点を提供しています。それぞれを詳しく見てみましょう:
Pandas
Pandas は、データサイエンスコミュニティで多目的で確立されたライブラリです。堅牢なデータ構造(DataFrame および Series)とデータのクリーニングや変換のための包括的なツールを提供しています。 Pandas はデータ探索と可視化に優れており、幅広いドキュメントとコミュニティサポートを備えています。
ただし、大規模なデータセットではパフォーマンスの問題があり、シングルスレッドの操作に限定されており、大規模なデータセットに対して高いメモリ使用量が発生することがあります。 Pandas は、小規模から中規模のデータセット(数 GB まで)や広範なデータ操作と分析が必要な場合に最適です。
Dask
Daskは、大規模データ処理のためにpandasを拡張したもので、複数のCPUコアまたはクラスター間で並列計算を提供し、利用可能なRAMよりも大きなデータセットのためのアウトオブコア計算を提供します。これにより、pandasの操作をビッグデータにスケーリングし、PyDataエコシステムとの統合がスムーズです。
ただし、Daskはpandas APIのサブセットのみをサポートしており、分散コンピューティング用にセットアップおよび最適化することが複雑になることがあります。メモリに収まらない非常に大きなデータセットや分散コンピューティングリソースが必要なデータの処理に最適です。
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
より良いパフォーマンスのために、Daskでデータをロードする際は、Pandasのデータフレーム
dd.from_pandas(df_pandas, npartitions=4)の代わりにdd.from_dict(data, npartitions=4)を使用してください。
出力
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
DuckDB
DuckDBは、インプロセスの分析データベースであり、列ベクトル化されたクエリエンジンを使用して高速な解析クエリを提供します。SQLをサポートし、追加の機能を備え、外部依存関係がないため、セットアップが簡単です。DuckDBは、解析クエリに対する優れたパフォーマンスと、Pythonや他の言語との簡単な統合を提供します。
ただし、高ボリュームのトランザクションワークロードには適しておらず、並行性オプションが限られています。DuckDBは、特にSQLクエリが好まれる場合に、解析ワークロードで優れた性能を発揮します。
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
出力
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
Modin
Modinは、複数のCPUコアを利用してpandasの代替となることを目指し、分散システム全体でpandasの操作をスケーリングするために高速な実行を実現します。採用するためにはコードの変更が最小限で済み、マルチコアシステムでの大幅な速度向上の可能性を提供します。
ただし、一部のシナリオでModinのパフォーマンス向上が限定される場合があり、現在も積極的な開発が行われています。主にコードの大幅な変更をせずに既存のpandasワークフローの高速化を図りたいユーザーに適しています。
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
Output
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polarsは、Rustで構築された高性能DataFrameライブラリであり、メモリ効率のよい列指向のメモリレイアウトと最適化されたクエリプランニングのための遅延評価APIを特徴としています。データ処理タスクに対する優れた速度と大規模なデータセットの処理のスケーラビリティを提供します。
ただし、Polarsはpandasとは異なるAPIを持ち、学習が必要であり、非常に大きなデータセット(100 GB以上)に苦労する可能性があります。パフォーマンスを重視する中〜大規模のデータセットを扱うデータサイエンティストやエンジニア向けに最適です。
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
Output
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
FireDucksは、pandas APIと完全な互換性を持ち、マルチスレッド実行、および遅延実行による効率的なデータフロー最適化を提供します。コード実行を最適化するランタイムコンパイラを特徴とし、pandasよりも大幅なパフォーマンスの向上を提供します。FireDucksは、pandas APIとの互換性とデータ操作の自動最適化により、簡単に採用できます。
ただし、それは比較的新しく、より確立されたライブラリと比較してコミュニティのサポートが少なく、ドキュメントが限られているかもしれません。
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
出力
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
Datatable
Datatableは、列指向のデータストレージ、すべてのデータ型に対するネイティブC実装、およびマルチスレッドのデータ処理を特徴とするデータ操作のためのハイパフォーマンスライブラリです。データ処理タスクに対する卓越した速度、効率的なメモリ使用、大規模データセット(最大100GB)の取り扱いに適しています。DatatableのAPIは、Rのdata.tableに類似しています。
ただし、pandasと比較して包括的なドキュメントが少なく、機能も少なく、Windowsと互換性がありません。Datatableは、速度が重要な場合に特に1台のマシンで大規模データセットを処理するのに適しています。
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
出力
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
パフォーマンス比較
Datatableは、大規模データ処理を必要とするシナリオで優れた性能を発揮し、ソート、グループ化、データの読み込みなどの操作においてpandasに比べて大幅なパフォーマンス向上を提供します。そのマルチスレッド処理機能により、現代のマルチコアプロセッサを効果的に活用するのに特に効果的です。
結論
結論として、ライブラリの選択はデータセットのサイズ、パフォーマンス要件、特定のユースケースなどの要因に依存します。パンダは小規模なデータセットに対して柔軟性がありますが、DaskやFireDucksなどの代替手段は大規模なデータ処理に強力なソリューションを提供しています。DuckDBは解析クエリに優れており、Polarsは中規模のデータセットに高パフォーマンスを提供し、Modinは最小限のコード変更でpandasの操作をスケーリングすることを目指しています。
以下の棒グラフは、データフレームを比較するためにライブラリのパフォーマンスを示しています。データはパーセンテージを表示するために正規化されています。
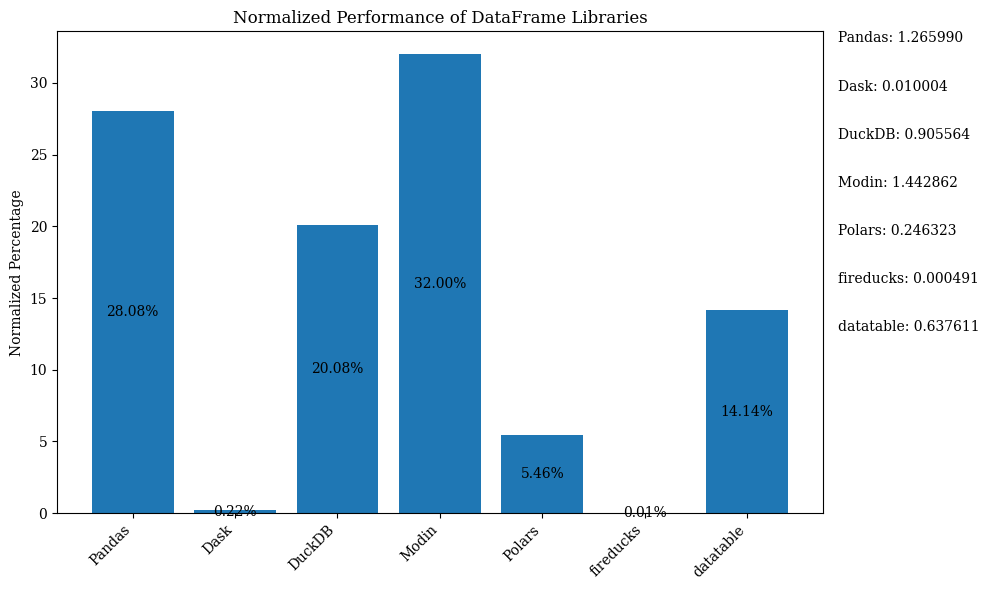
上記のバーチャートを正規化されたデータで表示するPythonコードについては、Jupyter Notebookを参照してください。FireDucksはLinuxのみで利用可能なため、Google Colabを使用してください。
比較チャート
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| Pandas | 適度 | 低 | N/A(元の状態) | 小~中規模のデータセット、データ探索 | 柔軟性、豊富なエコシステム | 大規模なデータセットでは遅い、シングルスレッド |
| Dask | 高 | 非常に高い | 高 | 大規模なデータセット、分散コンピューティング | pandasの操作をスケーリング、分散処理 | 複雑なセットアップ、部分的なpandas APIサポート |
| DuckDB | 非常に高い | 適度 | 低 | 解析クエリ、SQLベースの分析 | 高速なSQLクエリ、簡単な統合 | トランザクションワークロードには不向き、限られた同時実行性 |
| Modin | 高い | 高い | 非常に高い | 既存のpandasワークフローのスピードアップ | 簡単な採用、マルチコア活用 | 特定のシナリオでの改善は限られている |
| Polars | 非常に高い | 高い | 中程度 | 中〜大規模データセット、パフォーマンス重視 | 卓越したスピード、モダンなAPI | 学習曲線、非常に大きなデータに苦戦 |
| FireDucks | 非常に高い | 高い | 非常に高い | 大規模データセット、pandasのようなAPIでパフォーマンス | 自動最適化、pandas互換性 | 新しいライブラリ、コミュニティサポートが少ない |
| Datatable | 非常に高い | 高い | 中程度 | 単一マシンでの大規模データセット | 高速処理、効率的なメモリ使用 | 機能が限られている、Windowsサポートなし |
この表は、各ライブラリの強み、制限、および最適な使用ケースの概要を提供し、パフォーマンス、スケーラビリティ、pandasとのAPI類似性など、さまざまな側面での簡単な比較を可能にします。
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas