













Zoals besproken in mijn vorige artikel over gegevensarchitecturen die opkomende trends benadrukken, is gegevensverwerking een van de belangrijkste componenten in de moderne gegevensarchitectuur. Dit artikel bespreekt verschillende alternatieven voor de Pandas-bibliotheek voor betere prestaties in uw gegevensarchitectuur.
Gegevensverwerking en gegevensanalyse zijn cruciale taken op het gebied van data science en data engineering. Naarmate datasets groter en complexer worden, kunnen traditionele tools zoals pandas moeite hebben met prestaties en schaalbaarheid. Dit heeft geleid tot de ontwikkeling van verschillende alternatieve bibliotheken, die elk zijn ontworpen om specifieke uitdagingen in gegevensmanipulatie en -analyse aan te pakken.
Inleiding
De volgende bibliotheken zijn naar voren gekomen als krachtige tools voor gegevensverwerking:
- Pandas – Het traditionele werkpaard voor gegevensmanipulatie in Python
- Dask – Breidt pandas uit voor grootschalige, gedistribueerde gegevensverwerking
- DuckDB – Een in-process analytische database voor snelle SQL-query’s
- Modin – Een drop-in vervanger voor pandas met verbeterde prestaties
- Polars – Een high-performance DataFrame-bibliotheek gebouwd in Rust
- FireDucks – Een compiler-versnelde alternatief voor pandas
- Datatable – Een high-performance bibliotheek voor gegevensmanipulatie
Elke van deze bibliotheken biedt unieke functies en voordelen, afgestemd op verschillende gebruiksscenario’s en prestatievereisten. Laten we elk ervan in detail verkennen:
Pandas
Pandas is een veelzijdige en goed gevestigde bibliotheek in de data science gemeenschap. Het biedt robuuste datastructuren (DataFrame en Series) en uitgebreide tools voor gegevensreiniging en transformatie. Pandas excelleert in data-exploratie en visualisatie, met uitgebreide documentatie en community-ondersteuning.
Het heeft echter prestatieproblemen met grote datasets, is beperkt tot single-threaded bewerkingen en kan een hoog geheugengebruik hebben voor grote datasets. Pandas is ideaal voor kleinere tot middelgrote datasets (tot een paar GB) en wanneer uitgebreide gegevensmanipulatie en -analyse vereist zijn.
Dask
Dask breidt pandas uit voor gegevensverwerking op grote schaal, waarbij parallelle verwerking wordt geboden over meerdere CPU-cores of clusters en out-of-core berekening voor datasets groter dan het beschikbare RAM-geheugen. Het schaalt pandas-operaties naar big data en integreert goed met het PyData-ecosysteem.
Dask ondersteunt echter slechts een subset van de pandas API en kan complex zijn om in te stellen en te optimaliseren voor gedistribueerde berekeningen. Het is het meest geschikt voor het verwerken van extreem grote datasets die niet in het geheugen passen of gedistribueerde rekencapaciteit vereisen.
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
Voor betere prestaties, laad gegevens met Dask door
dd.from_dict(data, npartitions=4te gebruiken in plaats van het Pandas-datasetdd.from_pandas(df_pandas, npartitions=4)
Output
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
DuckDB
DuckDB is een analytische database in proces die snelle analytische query’s biedt met behulp van een kolomgerichte query-engine. Het ondersteunt SQL met aanvullende functies en heeft geen externe afhankelijkheden, waardoor de installatie eenvoudig is. DuckDB biedt uitzonderlijke prestaties voor analytische query’s en eenvoudige integratie met Python en andere talen.
Het is echter niet geschikt voor werklasten met een hoog volume aan transacties en heeft beperkte opties voor gelijktijdigheid. DuckDB blinkt uit in analytische werklasten, vooral wanneer SQL-query’s de voorkeur hebben.
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
Output
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
Modin
Modin streeft ernaar een plug-and-play vervanging voor pandas te zijn, waarbij meerdere CPU-cores worden gebruikt voor snellere uitvoering en het schalen van pandas-operaties over gedistribueerde systemen. Het vereist minimale codeaanpassingen om over te stappen en biedt potentieel voor aanzienlijke snelheidsverbeteringen op multi-core systemen.
Echter, Modin kan beperkte prestatieverbeteringen hebben in sommige scenario’s en is nog steeds in actieve ontwikkeling. Het is het beste voor gebruikers die bestaande pandas-workflows willen versnellen zonder grote codeaanpassingen.
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
Output
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polars is een high-performance DataFrame-bibliotheek gebouwd in Rust, met een geheugenefficiënte kolomsgewijze geheugenlay-out en een lazy evaluation API voor geoptimaliseerde queryplanning. Het biedt uitzonderlijke snelheid voor dataprocessingtaken en schaalbaarheid voor het verwerken van grote datasets.
Echter, Polars heeft een andere API dan pandas, wat enige leercurve vereist, en kan moeite hebben met extreem grote datasets (100 GB+). Het is ideaal voor datawetenschappers en ingenieurs die werken met middelgrote tot grote datasets en prestaties prioriteren.
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
Output
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
FireDucks biedt volledige compatibiliteit met de pandas API, multi-threaded uitvoering en lazy execution voor efficiënte dataflow-optimalisatie. Het beschikt over een runtime-compiler die code-uitvoering optimaliseert, wat aanzienlijke prestatieverbeteringen biedt ten opzichte van pandas. FireDucks maakt gemakkelijke adoptie mogelijk vanwege de compatibiliteit met de pandas API en de automatische optimalisatie van gegevensbewerkingen.
Echter is het relatief nieuw en heeft het mogelijk minder community-ondersteuning en beperkte documentatie in vergelijking met meer gevestigde bibliotheken.
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
Output
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
Datatable
Datatable is een high-performance bibliotheek voor datamanipulatie, met kolomgeoriënteerde gegevensopslag, een native-C-implementatie voor alle gegevenstypen en multi-threaded gegevensverwerking. Het biedt uitzonderlijke snelheid voor gegevensverwerkingstaken, efficiënt geheugengebruik en is ontworpen voor het verwerken van grote datasets (tot 100 GB). De API van Datatable is vergelijkbaar met die van R’s data.table.
Echter heeft het minder uitgebreide documentatie vergeleken met pandas, minder functies en is het niet compatibel met Windows. Datatable is ideaal voor het verwerken van grote datasets op één machine, vooral wanneer snelheid cruciaal is.
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
Output
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
Prestatievergelijking
- Gegevens laden: 34 keer sneller dan pandas voor een dataset van 5,7GB
- Gegevenssortering: 36 keer sneller dan pandas
- Groepsbewerkingen: 2 keer sneller dan pandas
Datatable blinkt uit in scenario’s met grootschalige gegevensverwerking en biedt aanzienlijke prestatieverbeteringen ten opzichte van pandas voor bewerkingen zoals sorteren, groeperen en gegevensladen. Zijn multi-threaded verwerkingsmogelijkheden maken het bijzonder effectief voor het benutten van moderne multi-core processors
Conclusie
In conclusie hangt de keuze van de bibliotheek af van factoren zoals dataset grootte, prestatievereisten en specifieke gebruiksscenario’s. Terwijl Pandas veelzijdig blijft voor kleinere datasets, bieden alternatieven zoals Dask en FireDucks sterke oplossingen voor grootschalige gegevensverwerking. DuckDB blinkt uit in analytische queries, Polars biedt hoge prestaties voor middelgrote datasets, en Modin streeft ernaar om Pandas-operaties op te schalen met minimale codeaanpassingen.
De staafdiagram hieronder toont de prestaties van de bibliotheken, met behulp van het DataFrame ter vergelijking. De gegevens zijn genormaliseerd om de percentages weer te geven.
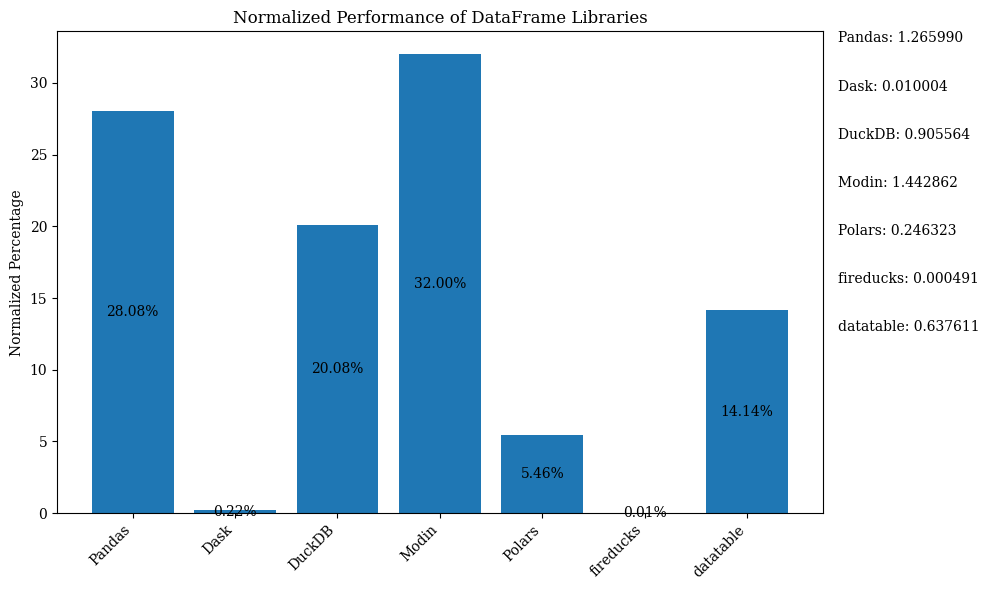
Voor de Python-code die de bovenstaande staafgrafiek met genormaliseerde gegevens weergeeft, raadpleeg de Jupyter Notebook. Gebruik Google Colab omdat FireDucks alleen beschikbaar is op Linux
Vergelijkingstabel
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| Pandas | Gematigd | Laag | N/B (Origineel) | Kleine tot middelgrote datasets, gegevensexploratie | Veelzijdigheid, rijk ecosysteem | Langzaam met grote datasets, single-threaded |
| Dask | Hoog | Zeer hoog | Hoog | Grote datasets, gedistribueerde berekening | Schaalt Pandas-operaties, gedistribueerde verwerking | Complexe setup, gedeeltelijke Pandas API-ondersteuning |
| DuckDB | Zeer hoog | Gematigd | Laag | Analytische queries, op SQL gebaseerde analyse | Snelle SQL-query’s, eenvoudige integratie | Niet voor transactionele workloads, beperkte gelijktijdigheid |
| Modin | Hoog | Hoog | Zeer hoog | Versnellen van bestaande pandas-workflows | Eenvoudige adoptie, multi-core gebruik | Beperkte verbeteringen in sommige scenario’s |
| Polars | Zeer hoog | Hoog | Gematigd | Grote tot zeer grote datasets, prestatiekritisch | Uitzonderlijke snelheid, moderne API | Leercurve, moeite met zeer grote data |
| FireDucks | Zeer hoog | Hoog | Zeer hoog | Grote datasets, pandas-achtige API met prestaties | Automatische optimalisatie, pandas-compatibiliteit | Nieuwere bibliotheek, minder community-ondersteuning |
| Datatable | Zeer hoog | Hoog | Gematigd | Grote datasets op één machine | Snelle verwerking, efficiënt geheugen gebruik | Beperkte functies, geen ondersteuning voor Windows |
Deze tabel biedt een snel overzicht van de sterke punten, beperkingen en beste gebruiksscenario’s van elke bibliotheek, waardoor een eenvoudige vergelijking mogelijk is op verschillende aspecten zoals prestaties, schaalbaarheid en API-gelijkheid met pandas.
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas