













כפי שדובר במאמר הקודם שלי על ארכיטקטורות נתונים המדגישות מגמות עולות, עיבוד נתונים הוא אחד מרכיבי המפתח בארכיטקטורה המודרנית של הנתונים. מאמר זה מדבר על אפשרויות שונות לספריית Pandas לביצועים טובים יותר בארכיטקטורת הנתונים שלך.
עיבוד נתונים וניתוח נתונים הם משימות קריטיות בתחום מדעי הנתונים וההנדסה של נתונים. כאשר סטי הנתונים גדלים ומורכבים יותר, כלים מסורתיים כמו pandas עשויים להתמודד עם בעיות בביצועים ובקידמה. זה הוביל לפיתוח מספר ספריות אלטרנטיביות, כל אחת מעוצבת לטיפול באתגרים ספציפיים בניהול וניתוח נתונים.
הקדמה
הספריות הבאות זכו בזיהומן ככלי עוצמתיים לעיבוד נתונים:
- Pandas – העבודה המסורתית לניהול נתונים בפייתון
- Dask – מרחיב את pandas לעיבוד נתונים בגדלים גדולים ומבנה מבוזר
- DuckDB – מסד נתונים אנליטי בתהליך לשאילתות SQL מהירות
- Modin – החלפה נטוית ל-pandas עם ביצועים משופרים
- פולארס – ספריית DataFrame ביצועית בנויה על Rust
- FireDucks – אלטרנטיבה מאוצרת ל־pandas המאיצה קומפיילר
- טבלת נתונים – ספריית ביצועית לעיבוד נתונים
כל אחת מהספריות הללו מציעה תכונות ייחודיות ויתרונות שמגיבים לצרכי ביצועים שונים. בואו נבדוק כל אחת מהן בפרט:
pandas
pandas היא ספריית גמישה ומוכרת בקרב קהילת מדעי הנתונים. היא מציעה מבני נתונים חזקים (DataFrame ו־Series) וכלים מקיפים לניקוי והמרת נתונים. pandas מצטיינת בחקירת נתונים ותצוגה, עם תיעוד מפורט ותמיכה בקהילה.
עם זאת, היא נתקלת בבעיות ביצועים עם קבצי נתונים גדולים, מוגבלת לפעולות באשר רק באשר ויכולה לצרוך זיכרון בגודל גדול עבור קבצי נתונים גדולים. pandas אידיאלית לקבצי נתונים בגודל קטן עד בינוני (עד כמה ג'יגה־בייטים) וכאשר נדרשים עיבוד וניתוח נתונים נרחבים.
Dask
Dask מרחיב את pandas עבור עיבוד נתונים בקנה מידה גדול, מציע חישוב מקביל על פני מספר ליבות CPU או אשכולות וחישוב out-of-core עבור קבצי נתונים שגדולים מה-RAM הזמין. הוא משפר את פעולות ה-pandas לנתונים גדולים ומשתלב היטב עם אקוסיסטמת PyData.
עם זאת, Dask תומך רק בתת-סט של API של pandas ויכול להיות מורכב להגדיר ולאופטימיזציה עבור חישוב מבוזר. הוא מתאים ביותר לעיבוד של קבצי נתונים עצומים מאוד שאינם מתאימים לזיכרון או דורשים משאבים לחישוב מבוזר.
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
לקבלת ביצועים טובים יותר, טען נתונים עם Dask באמצעות
dd.from_dict(data, npartitions=4במקום ה-Pandas dataframedd.from_pandas(df_pandas, npartitions=4)
פלט
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
DuckDB
DuckDB הוא מסד נתונים אנליטי בתהליך הרצה המציע שאילתות אנליטיות מהירות באמצעות מנוע שאילתה columnar-vectorized. הוא תומך ב-SQL עם תכונות נוספות ואין לו תלות חיצונית, מה שהופך את ההתקנה לפשוטה. DuckDB מספק ביצועים יוצאי דופן לשאילתות אנליטיות ואינטגרציה קלה עם Python ושפות אחרות.
עם זאת, הוא אינו מתאים לעומסי עבודה טרנזקציונליים בגודל גבוה ויש לו אפשרויות קונקורנציה מוגבלות. DuckDB מתצלח בעבודות אנליטיות, במיוחד כאשר שאילתות SQL מועדפות.
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
פלט
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
Modin
Modin יועדה להיות חלופה נוחה ל-pandas, השתמשות בכמה ליבות CPU לביצוע מהיר והתפשטות פעולות pandas על מערכות מבוזרות. זה מחייב שינויים מינימליים בקוד כדי לאמץ ומציע אפשרות לשיפורי מהירות משמעותיים במערכות מרובות ליבות.
עם זאת, Modin עשויה להציע שיפורי ביצועים מוגבלים בסקירות מסוימות ונמצאת עדיין בפיתוח פעיל. זה מומלץ למשתמשים המחפשים להאיץ את זרימות העבודה של pandas הקיימות מבלי שינויים ראשיים בקוד.
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
פלט
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polars היא ספריית DataFrame ביצועית ביותר שנבנית על Rust, המציעה תצורת זיכרון עמוקה בידיעות ו- API של הערכה עצלה לתכנון שאילתות מאובטימלי. זה מציע מהירות יוצאת דופן למשימות עיבוד נתונים וקידמה לטיפוח מערכות גדולות.
עם זאת, ל-Polars יש API שונה מ-pandas, הדורשת למידה מסוימת, ועשויה להתמודד עם מערכות נתונים ענקיות מאוד (100 GB+). זה אידיאלי עבור מדעני נתונים ומהנדסים העובדים עם מערכות נתונים בינוניות עד גדולות שמעריכים ביצועים.
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
פלט
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
FireDucks מציעה תאימות מלאה עם API של pandas, ביצוע בר-ת'רד רב-ת'רד וביצוע עצל לאופטימיזציה יעילה של זרימת נתונים. זה מציע מהירות יעילה למשימות עיבוד נתונים וקיימות לטיפוח מערכות גדולות נתונים.
אך, זה יחסית חדש ועשוי לקבל תמיכה קהילתית פחותה ותיעוד מוגבל בהשוואה לספריות מוכחות יותר.
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
פלט
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
טבלה
טבלה היא ספריית ביצועים גבוהים לעיבוד נתונים, המציעה אחסון נתונים ממוקד עמודות, יישום בשפת C המקומית לכל סוגי הנתונים, ועיבוד נתונים ב- multi-threaded. היא מציעה מהירות יוצאת דופן למשימות עיבוד נתונים, שימוש יעיל בזיכרון, ומיועדת לטיפול בקבוצות נתונים גדולות (עד 100 ג'יגה-בייט). ממשק ה- API של טבלה דומה ל- data.table של R.
עם זאת, יש לה תיעוד פחות רחב בהשוואה ל- pandas, פחות תכונות, והיא לא תואמת ל- Windows. טבלה היא אידיאלית לעיבוד קבוצות נתונים גדולות על מחשב יחיד, במיוחד כאשר מהירות חיונית.
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
פלט
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
השוואת ביצועים
- טעינת נתונים: 34 פעמים מהיר יותר מ- pandas עבור קבוצת נתונים בגודל 5.7GB
- מיון נתונים: 36 פעמים מהיר יותר מ- pandas
- פעולות קיבוץ: 2 פעמים מהיר יותר מ- pandas
טבלה מתמחה בתרחישים הכוללים עיבוד נתונים בגדל רב, מציעה שיפורי ביצועים משמעותיים על pandas לפעולות כמו מיון, קיבוץ, וטעינת נתונים. יכולות העיבוד ב- multi-threaded שלה עושות אותה במיוחד יעילה לניצול של מעבדים מרובי ליבות מודרניים
מסקנה
בסיכום, בחירת הספרייה תלויה בגורמים כגון גודל קבוצת הנתונים, דרישות ביצועים ותרחישי שימוש ספציפיים. בעוד ש־pandas נשארת רב-תכליתית עבור קבוצות נתונים קטנות, אלטרנטיבות כמו Dask ו־FireDucks מציעות פתרונות חזקים לעיבוד נתונים בגדלים גדולים. DuckDB מצטיינת בשאילתות אנליטיות, Polars מספקת ביצועים גבוהים עבור קבוצות נתונים בגודל בינוני, ו־Modin פועלת להגדלת פעולות pandas עם שינויים בקוד מינימליים.
תרשים הברים למטה מציג את הביצועים של הספריות, באמצעות DataFrame להשוואה. הנתונים נורמלים להצגת האחוזים.
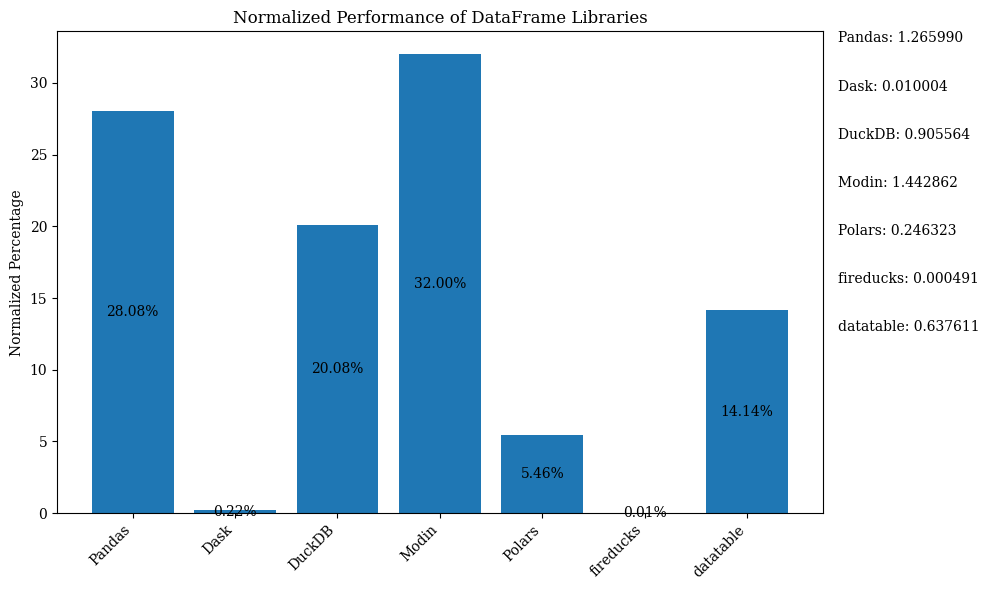
לקוד Python שמציג את תרשים הברים הנ"ל עם הנתונים הנורמליים, ראו את ה־Jupyter Notebook. השתמשו ב־Google Colab מאחר ו־FireDucks זמינה רק עבור Linux
טבלת השוואה
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| pandas | בינוני | נמוך | לא זמין (מקורי) | קבוצות נתונים קטנות עד בינוניות, חקירת נתונים | רב-תכליתית, אקוסיסטמה עשירה | איטית עם קבוצות נתונים גדולות, עם תהליך יחיד |
| Dask | גבוה | גבוה מאוד | גבוה | קבוצות נתונים גדולות, חישוב מבוזר | מגדילה פעולות pandas, עיבוד מבוזר | הגדרה מורכבת, תמיכה חלקית ב־pandas API |
| DuckDB | גבוה מאוד | בינוני | נמוך | שאילתות אנליטיות, ניתוח מבוסס SQL | שאילתות SQL מהירות, שילוב קל | לא מתאים לעומסי עבודה טרנזקציוניים, זריזות מוגבלת |
| Modin | גבוה | גבוה | גבוה מאוד | האצת זרימות עבודה קיימות ב־pandas | קל לאימוץ, השתמשות ברב-ליבות | שיפורים מוגבלים בתרחישים מסוימים |
| Polars | גבוה מאוד | גבוה | רגיל | קבצים בגודל בינוני עד גדול, חיוניות בביצועים | מהירות יוצאת דופן, API מודרני | רמת למידה, קושי עם נתונים בגודל עצום |
| FireDucks | גבוה מאוד | גבוה | גבוה מאוד | קבצים גדולים, API בסגנון pandas עם ביצועים | אופטימיזציה אוטומטית, תאימות ל־pandas | ספרייה חדשה יותר, תמיכה קהילתית פחותה |
| Datatable | גבוה מאוד | גבוה | רגיל | קבצים גדולים על מחשב אישי אחד | עיבוד מהיר, שימוש יעיל בזיכרון | תכונות מוגבלות, אין תמיכה ב־Windows |
טבלה זו מספקת סקירה מהירה של נקודות חוזק, הגבלות ומקרי השימוש הטובים ביותר של כל ספרייה, מאפשרת השוואה קלה בין תחומים שונים כגון ביצועים, קידמה ודמיון API ל־pandas.
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas