













Conforme discutido em meu artigo anterior sobre arquiteturas de dados enfatizando tendências emergentes, o processamento de dados é um dos principais componentes na arquitetura de dados moderna. Este artigo discute várias alternativas à biblioteca Pandas para melhorar o desempenho em sua arquitetura de dados.
O processamento de dados e a análise de dados são tarefas cruciais no campo da ciência de dados e engenharia de dados. À medida que os conjuntos de dados crescem em tamanho e complexidade, ferramentas tradicionais como o pandas podem enfrentar problemas de desempenho e escalabilidade. Isso levou ao desenvolvimento de várias bibliotecas alternativas, cada uma projetada para lidar com desafios específicos na manipulação e análise de dados.
Introdução
As seguintes bibliotecas surgiram como ferramentas poderosas para o processamento de dados:
- Pandas – O cavalo de batalha tradicional para manipulação de dados em Python
- Dask – Estende o pandas para processamento de dados em larga escala e distribuído
- DuckDB – Um banco de dados analítico em processo para consultas SQL rápidas
- Modin – Um substituto direto para o pandas com desempenho aprimorado
- Polars – Uma biblioteca de DataFrame de alto desempenho construída em Rust
- FireDucks – Uma alternativa acelerada por compilador ao pandas
- Datatable – Uma biblioteca de alto desempenho para manipulação de dados
Cada uma dessas bibliotecas oferece recursos e benefícios únicos, atendendo a diferentes casos de uso e requisitos de desempenho. Vamos explorar cada uma em detalhes:
Pandas
Pandas é uma biblioteca versátil e bem estabelecida na comunidade de ciência de dados. Oferece estruturas de dados robustas (DataFrame e Series) e ferramentas abrangentes para limpeza e transformação de dados. O Pandas se destaca na exploração e visualização de dados, com extensa documentação e suporte da comunidade.
No entanto, enfrenta problemas de desempenho com conjuntos de dados grandes, é limitado a operações de thread único e pode ter alto uso de memória para conjuntos de dados grandes. O Pandas é ideal para conjuntos de dados pequenos a médios (até alguns GB) e quando são necessárias manipulação e análise extensivas de dados.
Dask
Dask estende o pandas para processamento de dados em larga escala, oferecendo computação paralela em vários núcleos de CPU ou clusters e computação out-of-core para conjuntos de dados maiores que a RAM disponível. Ele dimensiona operações pandas para big data e se integra bem ao ecossistema PyData.
No entanto, o Dask suporta apenas um subconjunto da API do pandas e pode ser complexo de configurar e otimizar para computação distribuída. É mais adequado para processar conjuntos de dados extremamente grandes que não cabem na memória ou requerem recursos de computação distribuída.
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
Para melhor desempenho, carregue dados com Dask usando
dd.from_dict(data, npartitions=4no lugar do dataframe do Pandasdd.from_pandas(df_pandas, npartitions=4)
Resultado
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
DuckDB
DuckDB é um banco de dados analítico em processo que oferece consultas analíticas rápidas usando um mecanismo de consulta vetorizado por coluna. Ele suporta SQL com recursos adicionais e não possui dependências externas, o que torna a configuração simples. DuckDB oferece desempenho excepcional para consultas analíticas e integração fácil com Python e outras linguagens.
No entanto, não é adequado para cargas de trabalho transacionais de alto volume e possui opções de concorrência limitadas. DuckDB se destaca em cargas de trabalho analíticas, especialmente quando consultas SQL são preferidas.
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
Resultado
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
Modin
Modin tem como objetivo ser um substituto direto para o pandas, utilizando múltiplos núcleos de CPU para uma execução mais rápida e escalando operações do pandas em sistemas distribuídos. Requer mudanças mínimas de código para adoção e oferece potencial para melhorias significativas de velocidade em sistemas multi-core.
No entanto, Modin pode ter melhorias de desempenho limitadas em alguns cenários e ainda está em desenvolvimento ativo. É ideal para usuários que buscam acelerar fluxos de trabalho existentes do pandas sem grandes mudanças de código.
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
Output
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polars é uma biblioteca de DataFrame de alto desempenho construída em Rust, apresentando um layout de memória colunar eficiente e uma API de avaliação preguiçosa para planejamento de consultas otimizado. Oferece velocidade excepcional para tarefas de processamento de dados e escalabilidade para lidar com grandes conjuntos de dados.
No entanto, Polars possui uma API diferente do pandas, exigindo um aprendizado adicional, e pode ter dificuldades com conjuntos de dados extremamente grandes (100 GB+). É ideal para cientistas de dados e engenheiros que trabalham com conjuntos de dados de médio a grande porte e priorizam o desempenho.
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
Output
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
FireDucks oferece total compatibilidade com a API do pandas, execução multi-threaded e execução preguiçosa para otimização eficiente do fluxo de dados. Possui um compilador em tempo de execução que otimiza a execução de código, proporcionando melhorias significativas de desempenho em relação ao pandas. FireDucks permite uma adoção fácil devido à sua compatibilidade com a API do pandas e à otimização automática das operações de dados.
No entanto, é relativamente novo e pode ter menos suporte da comunidade e documentação limitada em comparação com bibliotecas mais estabelecidas.
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
Resultado
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
Tabela de Dados
A Datatable é uma biblioteca de alto desempenho para manipulação de dados, apresentando armazenamento de dados orientado a colunas, implementação nativa em C para todos os tipos de dados e processamento de dados com várias threads. Oferece velocidade excepcional para tarefas de processamento de dados, uso eficiente de memória e é projetada para lidar com grandes conjuntos de dados (até 100 GB). A API da Datatable é semelhante à data.table do R.
No entanto, possui documentação menos abrangente em comparação com o pandas, menos recursos e não é compatível com o Windows. A Datatable é ideal para processar grandes conjuntos de dados em uma única máquina, especialmente quando a velocidade é crucial.
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
Resultado
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
Comparação de Desempenho
- Carregamento de dados: 34 vezes mais rápido que o pandas para um conjunto de dados de 5,7GB
- Classificação de dados: 36 vezes mais rápido do que o pandas
- Operações de agrupamento: 2 vezes mais rápido do que o pandas
A Datatable se destaca em cenários envolvendo processamento de dados em grande escala, oferecendo melhorias significativas de desempenho em relação ao pandas para operações como classificação, agrupamento e carregamento de dados. Suas capacidades de processamento com várias threads a tornam particularmente eficaz para utilizar processadores modernos com vários núcleos
Conclusão
Em conclusão, a escolha da biblioteca depende de fatores como tamanho do conjunto de dados, requisitos de desempenho e casos de uso específicos. Enquanto o pandas permanece versátil para conjuntos de dados menores, alternativas como Dask e FireDucks oferecem soluções robustas para processamento de dados em larga escala. DuckDB se destaca em consultas analíticas, Polars oferece alto desempenho para conjuntos de dados de tamanho médio, e Modin visa escalar operações do pandas com mudanças mínimas de código.
O diagrama de barras abaixo mostra o desempenho das bibliotecas, usando o DataFrame para comparação. Os dados estão normalizados para mostrar as porcentagens.
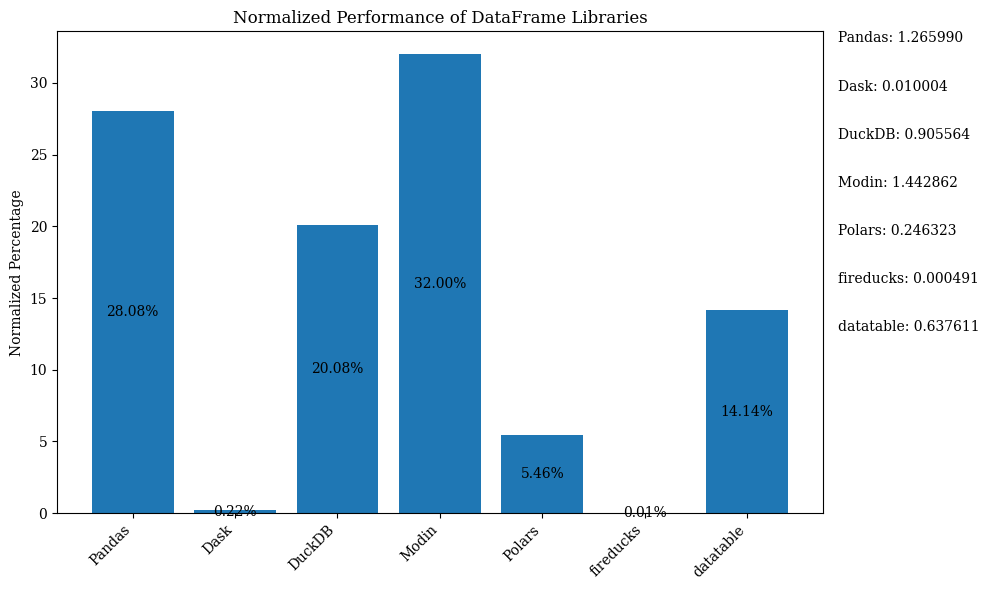
Para o código Python que mostra o gráfico de barras acima com dados normalizados, consulte o Jupyter Notebook. Use o Google Colab, pois o FireDucks está disponível apenas no Linux
Gráfico de Comparação
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| Pandas | Moderado | Baixo | N/A (Original) | Conjuntos de dados pequenos a médios, exploração de dados | Versatilidade, ecossistema rico | Lento com conjuntos de dados grandes, mononúcleo |
| Dask | Alto | Muito Alto | Alto | Conjuntos de dados grandes, computação distribuída | Escalabilidade de operações do pandas, processamento distribuído | Configuração complexa, suporte parcial à API do pandas |
| DuckDB | Muito Alto | Moderado | Baixo | Consultas analíticas, análise baseada em SQL | Consultas SQL rápidas, integração fácil | Não para cargas de trabalho transacionais, concorrência limitada |
| Modin | Alto | Alto | Muito alto | Acelerando fluxos de trabalho existentes do pandas | Adoção fácil, utilização de múltiplos núcleos | Melhorias limitadas em alguns cenários |
| Polars | Muito alto | Alto | Moderado | Conjuntos de dados de médio a grande porte, críticos em desempenho | Velocidade excepcional, API moderna | Curva de aprendizado, dificuldades com dados muito grandes |
| FireDucks | Muito alto | Alto | Muito alto | Conjuntos de dados grandes, API semelhante ao pandas com desempenho | Otimização automática, compatibilidade com pandas | Biblioteca mais recente, menos suporte da comunidade |
| Datatable | Muito alto | Alto | Moderado | Conjuntos de dados grandes em uma única máquina | Processamento rápido, uso eficiente de memória | Recursos limitados, sem suporte para Windows |
Esta tabela fornece uma visão geral rápida das forças, limitações e melhores casos de uso de cada biblioteca, permitindo uma comparação fácil em diferentes aspectos, como desempenho, escalabilidade e similaridade de API com o pandas.
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas