













이전 기사에서 신생 트렌드를 강조한 데이터 아키텍처에 대해 논의한 대로, 데이터 처리는 현대 데이터 아키텍처의 주요 구성 요소 중 하나입니다. 이 기사에서는 데이터 아키텍처에서 더 나은 성능을 위한 Pandas 라이브러리의 다양한 대안에 대해 논의합니다.
데이터 처리와 데이터 분석은 데이터 과학 및 데이터 엔지니어링 분야에서 중요한 작업입니다. 데이터 세트가 커지고 더 복잡해지면 Pandas와 같은 전통적인 도구는 성능과 확장성에 어려움을 겪을 수 있습니다. 이로 인해 데이터 조작 및 분석에서 특정 도전 과제를 해결하기 위해 설계된 여러 대체 라이브러리의 개발이 이루어졌습니다.
소개
다음 라이브러리들이 데이터 처리에 강력한 도구로 부상했습니다:
- Pandas – Python에서 데이터 조작을 위한 전통적인 주역
- Dask – 대규모 분산 데이터 처리를 위해 pandas를 확장
- DuckDB – 빠른 SQL 쿼리를 위한 인프로세스 분석 데이터베이스
- Modin – 성능 향상을 위한 pandas의 대체품
- Polars – 러스트로 구축된 고성능 DataFrame 라이브러리
- FireDucks – 판다스의 대안으로 컴파일 가속화된 옵션
- Datatable – 데이터 조작을 위한 고성능 라이브러리
이러한 라이브러리 각각은 독특한 기능과 이점을 제공하여 다양한 사용 사례와 성능 요구 사항을 충족시킵니다. 각각을 자세히 살펴보겠습니다:
Pandas
Pandas는 데이터 과학 커뮤니티에서 다재다능하고 잘 알려진 라이브러리입니다. 강력한 데이터 구조 (DataFrame 및 Series)와 데이터 정리 및 변환을 위한 포괄적인 도구를 제공합니다. Pandas는 데이터 탐색과 시각화에서 뛰어나며 방대한 문서와 커뮤니티 지원을 제공합니다.
그러나 대규모 데이터셋에서 성능 문제를 겪을 수 있으며 단일 스레드 작업에 제한이 있으며 대규모 데이터셋에 대해 높은 메모리 사용량을 가질 수 있습니다. Pandas는 소형에서 중형 데이터셋 (몇 기가바이트까지) 및 포괄적인 데이터 조작 및 분석이 필요한 경우에 이상적입니다.
Dask
Dask는 대용량 데이터 처리를 위해 pandas를 확장한 것으로, 여러 CPU 코어 또는 클러스터 간 병렬 컴퓨팅 및 사용 가능한 RAM보다 큰 데이터셋을 위한 외부 저장소 계산을 제공합니다. Dask는 pandas 작업을 대규모 데이터에 확장하고 PyData 생태계와 잘 통합됩니다.
그러나 Dask는 pandas API의 일부만 지원하며 분산 컴퓨팅을 위해 설정하고 최적화하는 것이 복잡할 수 있습니다. Dask는 메모리에 맞지 않거나 분산 컴퓨팅 리소스가 필요한 매우 큰 데이터셋을 처리하는 데 가장 적합합니다.
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
더 나은 성능을 위해 Dask로 데이터를로드하십시오 Pandas 데이터프레임의
dd.from_pandas(df_pandas, npartitions=4)대신dd.from_dict(data, npartitions=4)를 사용합니다.
결과
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
DuckDB
DuckDB는 열 기반 벡터화된 쿼리 엔진을 사용하여 빠른 분석 쿼리를 제공하는 인프로세스 분석 데이터베이스입니다. DuckDB는 추가 기능을 갖춘 SQL을 지원하며 외부 종속성이 없어 설정이 간단합니다. DuckDB는 분석 쿼리에 대한 우수한 성능과 Python 및 기타 언어와의 쉬운 통합을 제공합니다.
그러나 높은 볼륨의 트랜잭션 워크로드에는 적합하지 않으며 제한된 동시성 옵션을 갖습니다. DuckDB는 SQL 쿼리를 선호할 때 특히 분석 워크로드에서 뛰어난 성과를 보입니다.
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
결과
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
Modin
Modin은 팬더의 드롭인 대체를 목표로 하며, 여러 CPU 코어를 활용하여 더 빠른 실행과 분산 시스템에서 팬더 작업의 확장을 가능하게 합니다. 채택을 위한 최소한의 코드 변경이 필요하며, 다중 코어 시스템에서 상당한 속도 향상의 가능성을 제공합니다.
그러나 Modin은 일부 시나리오에서 성능 개선이 제한적일 수 있으며 여전히 활발히 개발 중입니다. 주요 코드 변경 없이 기존 팬더 워크플로를 가속화하려는 사용자에게 가장 적합합니다.
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
출력
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polars는 Rust로 구축된 고성능 DataFrame 라이브러리로, 메모리 효율적인 열 기반 메모리 레이아웃과 최적화된 쿼리 계획을 위한 지연 평가 API를 특징으로 합니다. 데이터 처리 작업에 대해 뛰어난 속도를 제공하며, 대규모 데이터셋 처리에 대한 확장성을 가지고 있습니다.
그러나 Polars는 팬더와 다른 API를 가지고 있어 학습이 필요하며, 극도로 큰 데이터셋(100GB 이상) 처리에 어려움을 겪을 수 있습니다. 성능을 우선시하는 중간에서 대규모 데이터셋을 다루는 데이터 과학자와 엔지니어에게 이상적입니다.
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
출력
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
FireDucks는 팬더 API와의 완벽한 호환성, 다중 스레드 실행 및 효율적인 데이터 흐름 최화를 위한 지연 실행을 제공합니다. 코드 실행을 최적화하는 런타임 컴파일러를 특징으로 하여 팬더에 비해 상당한 성능 향상을 제공합니다. FireDucks는 팬더 API 호환성 및 데이터 작업의 자동 최적화 덕분에 쉽게 채택할 수 있습니다.
그러나, 이것은 비교적 새로운 기술이며 더 확립된 라이브러리에 비해 커뮤니티 지원이 적고 문서화가 제한될 수 있습니다.
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
결과
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
데이터테이블
데이터테이블은 열 지향 데이터 저장, 모든 데이터 유형에 대한 네이티브 C 구현, 그리고 멀티스레드 데이터 처리를 특징으로 하는 데이터 조작을 위한 고성능 라이브러리입니다. 데이터 처리 작업에 대해 탁월한 속도, 효율적인 메모리 사용 및 대용량 데이터셋(최대 100GB) 처리를 제공합니다. 데이터테이블의 API는 R의 데이터테이블과 유사합니다. 그러나, 판다스보다 문서화가 덜 되어 있고 기능이 적으며 Windows와 호환되지 않습니다. 데이터테이블은 특히 속도가 중요할 때 단일 기계에서 대용량 데이터셋을 처리하는 데 이상적입니다.
결과
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
성능 비교
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
데이터 로딩: 5.7GB 데이터셋에 대해 판다스보다 34배 빠름
데이터테이블은 대규모 데이터 처리 시나리오에서 우수한 성능 향상을 제공하여 정렬, 그룹화, 데이터 로딩과 같은 작업에 대해 판다스보다 빠른 속도를 보여줍니다. 그의 멀티스레드 처리 능력은 현대적인 멀티코어 프로세서를 활용하는 데 특히 효과적입니다
결론
결론적으로, 라이브러리 선택은 데이터셋 크기, 성능 요구사항 및 특정 사용 사례와 같은 요인에 따라 달라집니다. 판다스는 작은 데이터셋에 대해 다재다능한 성능을 보여주지만, Dask와 FireDucks와 같은 대규모 데이터 처리에 강력한 솔루션을 제공합니다. DuckDB는 분석 쿼리에서 뛰어나며, Polars는 중간 규모의 데이터셋에 대한 고성능을 제공하며, Modin은 판다스 작업을 최소한의 코드 변경으로 확장하는 데 목표를 두고 있습니다.
아래 막대 다이어그램은 라이브러리의 성능을 DataFrame을 사용하여 비교한 것을 보여줍니다. 데이터는 백분율을 표시하기 위해 정규화되었습니다.
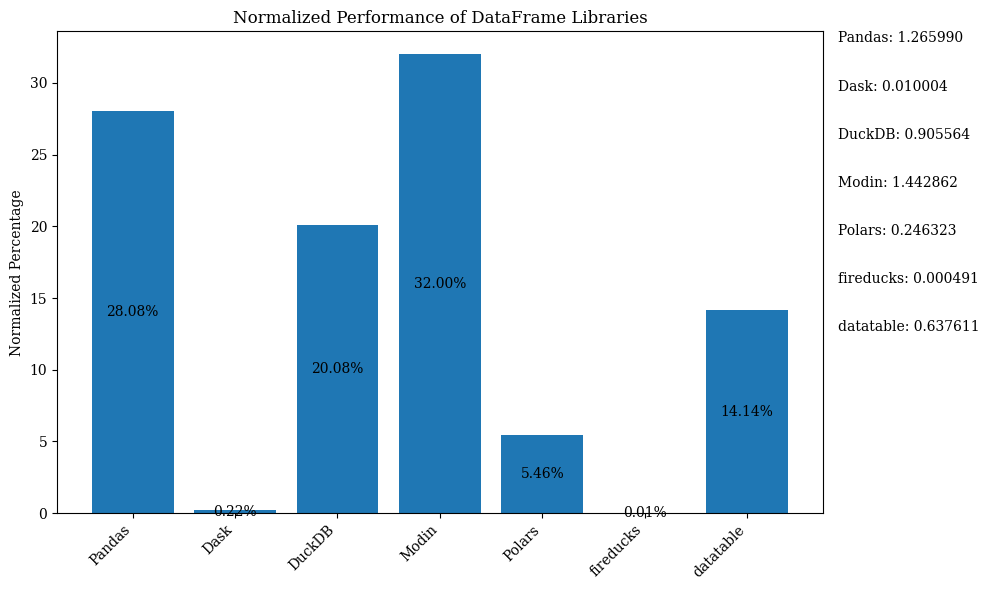
위의 막대 차트를 정규화된 데이터로 표시하는 Python 코드는 Jupyter Notebook를 참조하십시오. FireDucks는 Linux에서만 사용 가능하므로 Google Colab을 사용하십시오.
비교 차트
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| 판다스 | 보통 | 낮음 | 없음 (원본) | 소규모 및 중간 규모 데이터셋, 데이터 탐색 | 다재다능성, 풍부한 생태계 | 대용량 데이터셋에서 느림, 단일 스레드 |
| Dask | 높음 | 매우 높음 | 높음 | 대규모 데이터셋, 분산 컴퓨팅 | 판다스 작업 확장, 분산 처리 | 복잡한 설정, 일부 판다스 API 지원 |
| DuckDB | 매우 높음 | 보통 | 낮음 | 분석 쿼리, SQL 기반 분석 | 빠른 SQL 쿼리, 쉬운 통합 | 거래 작업에는 사용 불가, 제한된 동시성 |
| Modin | 높음 | 높음 | 매우 높음 | 기존 판다 워크플로우 가속화 | 쉬운 채택, 멀티코어 활용 | 일부 시나리오에서의 제한된 개선 |
| Polars | 매우 높음 | 높음 | 보통 | 중대형 데이터셋, 성능 중요 | 뛰어난 속도, 현대적 API | 학습 곡선, 매우 큰 데이터 처리 어려움 |
| FireDucks | 매우 높음 | 높음 | 매우 높음 | 대규모 데이터셋, 성능을 갖춘 판다스와 유사한 API | 자동 최적화, 판다스 호환성 | 새로운 라이브러리, 커뮤니티 지원 부족 |
| Datatable | 매우 높음 | 높음 | 보통 | 단일 기기의 대규모 데이터셋 | 빠른 처리, 효율적인 메모리 사용 | 기능 제한, Windows 지원 없음 |
이 표는 각 라이브러리의 장점, 한계, 최상의 사용 사례에 대한 빠른 개요를 제공하여 성능, 확장성 및 판다스와의 API 유사성과 같은 다양한 측면에서 쉬운 비교를 가능하게 합니다.
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas