













Como se discutió en mi artículo anterior sobre arquitecturas de datos que enfatizan las tendencias emergentes, el procesamiento de datos es uno de los componentes clave en la arquitectura de datos moderna. Este artículo analiza varias alternativas a la biblioteca Pandas para obtener un mejor rendimiento en su arquitectura de datos.
El procesamiento de datos y el análisis de datos son tareas cruciales en el campo de la ciencia de datos y la ingeniería de datos. A medida que los conjuntos de datos crecen en tamaño y complejidad, las herramientas tradicionales como Pandas pueden tener dificultades con el rendimiento y la escalabilidad. Esto ha llevado al desarrollo de varias bibliotecas alternativas, cada una diseñada para abordar desafíos específicos en la manipulación y análisis de datos.
Introducción
Las siguientes bibliotecas han surgido como herramientas poderosas para el procesamiento de datos:
- Pandas – El caballo de batalla tradicional para la manipulación de datos en Python
- Dask – Extiende Pandas para el procesamiento de datos a gran escala y distribuido
- DuckDB – Una base de datos analítica en proceso para consultas SQL rápidas
- Modin – Un reemplazo directo de Pandas con un rendimiento mejorado
- Polars – Una biblioteca de DataFrame de alto rendimiento construida en Rust
- FireDucks – Una alternativa acelerada por compilador a pandas
- Datatable – Una biblioteca de alto rendimiento para la manipulación de datos
Cada una de estas bibliotecas ofrece características y beneficios únicos, atendiendo a diferentes casos de uso y requisitos de rendimiento. Exploremos cada una en detalle:
Pandas
Pandas es una biblioteca versátil y bien establecida en la comunidad de ciencia de datos. Ofrece estructuras de datos robustas (DataFrame y Series) y herramientas completas para la limpieza y transformación de datos. Pandas se destaca en la exploración y visualización de datos, con una extensa documentación y soporte de la comunidad.
Sin embargo, enfrenta problemas de rendimiento con grandes conjuntos de datos, está limitado a operaciones de un solo hilo y puede tener un alto consumo de memoria para grandes conjuntos de datos. Pandas es ideal para conjuntos de datos pequeños a medianos (hasta unos pocos GB) y cuando se requieren manipulaciones y análisis de datos extensos.
Dask
Dask extiende pandas para el procesamiento de datos a gran escala, ofreciendo computación paralela a través de múltiples núcleos de CPU o clústeres y computación fuera de núcleo para conjuntos de datos más grandes que la RAM disponible. Escala las operaciones de pandas a grandes datos e integra bien con el ecosistema PyData.
Sin embargo, Dask solo admite un subconjunto de la API de pandas y puede ser complejo de configurar y optimizar para la computación distribuida. Es más adecuado para procesar conjuntos de datos extremadamente grandes que no caben en la memoria o que requieren recursos de computación distribuida.
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
Para un mejor rendimiento, carga datos con Dask usando
dd.from_dict(data, npartitions=4en lugar del dataframe de Pandasdd.from_pandas(df_pandas, npartitions=4)
Salida
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
DuckDB
DuckDB es una base de datos analítica en proceso que ofrece consultas analíticas rápidas utilizando un motor de consultas vectorizado por columnas. Admite SQL con características adicionales y no tiene dependencias externas, lo que facilita la configuración. DuckDB proporciona un rendimiento excepcional para consultas analíticas y una fácil integración con Python y otros lenguajes.
Sin embargo, no es adecuada para cargas de trabajo transaccionales de alto volumen y tiene opciones de concurrencia limitadas. DuckDB destaca en cargas de trabajo analíticas, especialmente cuando se prefieren consultas SQL.
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
Salida
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
Modin
Modin tiene como objetivo ser un reemplazo directo de pandas, utilizando múltiples núcleos de CPU para una ejecución más rápida y escalando las operaciones de pandas a través de sistemas distribuidos. Requiere cambios mínimos en el código para su adopción y ofrece un potencial de mejoras de velocidad significativas en sistemas de múltiples núcleos.
Sin embargo, Modin puede tener mejoras de rendimiento limitadas en algunos escenarios y aún se encuentra en desarrollo activo. Es mejor para los usuarios que buscan acelerar flujos de trabajo existentes de pandas sin grandes cambios en el código.
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
Salida
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polars es una biblioteca de DataFrame de alto rendimiento construida en Rust, que presenta una disposición de memoria columnar eficiente y una API de evaluación perezosa para una planificación de consultas optimizada. Ofrece una velocidad excepcional para tareas de procesamiento de datos y escalabilidad para manejar grandes conjuntos de datos.
Sin embargo, Polars tiene una API diferente de pandas, lo que requiere cierto aprendizaje, y puede tener dificultades con conjuntos de datos extremadamente grandes (más de 100 GB). Es ideal para científicos de datos e ingenieros que trabajan con conjuntos de datos de tamaño medio a grande y que priorizan el rendimiento.
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
Salida
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
FireDucks ofrece total compatibilidad con la API de pandas, ejecución multihilo y ejecución perezosa para una optimización eficiente del flujo de datos. Presenta un compilador en tiempo de ejecución que optimiza la ejecución del código, proporcionando mejoras de rendimiento significativas sobre pandas. FireDucks permite una adopción fácil debido a su compatibilidad con la API de pandas y la optimización automática de las operaciones de datos.
Sin embargo, es relativamente nuevo y puede tener menos soporte de la comunidad y documentación limitada en comparación con bibliotecas más establecidas.
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
Salida
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
Datatable
Datatable es una biblioteca de alto rendimiento para la manipulación de datos, que cuenta con almacenamiento de datos orientado a columnas, implementación en C nativo para todos los tipos de datos y procesamiento de datos multihilo. Ofrece una velocidad excepcional para tareas de procesamiento de datos, uso eficiente de memoria y está diseñada para manejar grandes conjuntos de datos (hasta 100 GB). La API de Datatable es similar a la de data.table de R.
Sin embargo, tiene menos documentación completa en comparación con pandas, menos funciones y no es compatible con Windows. Datatable es ideal para procesar grandes conjuntos de datos en una sola máquina, particularmente cuando la velocidad es crucial.
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
Salida
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
Comparación de Rendimiento
- Carga de datos: 34 veces más rápido que pandas para un conjunto de datos de 5.7 GB
- Clasificación de datos: 36 veces más rápido que pandas
- Operaciones de agrupamiento: 2 veces más rápido que pandas
Datatable sobresale en escenarios que implican procesamiento de datos a gran escala, ofreciendo mejoras significativas en el rendimiento sobre pandas para operaciones como clasificación, agrupamiento y carga de datos. Sus capacidades de procesamiento multihilo lo hacen particularmente efectivo para utilizar procesadores modernos de múltiples núcleos
Conclusión
En conclusión, la elección de la biblioteca depende de factores como el tamaño del conjunto de datos, los requisitos de rendimiento y los casos de uso específicos. Si bien pandas sigue siendo versátil para conjuntos de datos más pequeños, alternativas como Dask y FireDucks ofrecen soluciones sólidas para el procesamiento de datos a gran escala. DuckDB destaca en consultas analíticas, Polars proporciona un alto rendimiento para conjuntos de datos de tamaño medio, y Modin tiene como objetivo escalar las operaciones de pandas con cambios mínimos en el código.
El diagrama de barras a continuación muestra el rendimiento de las bibliotecas, utilizando el DataFrame para la comparación. Los datos están normalizados para mostrar los porcentajes.
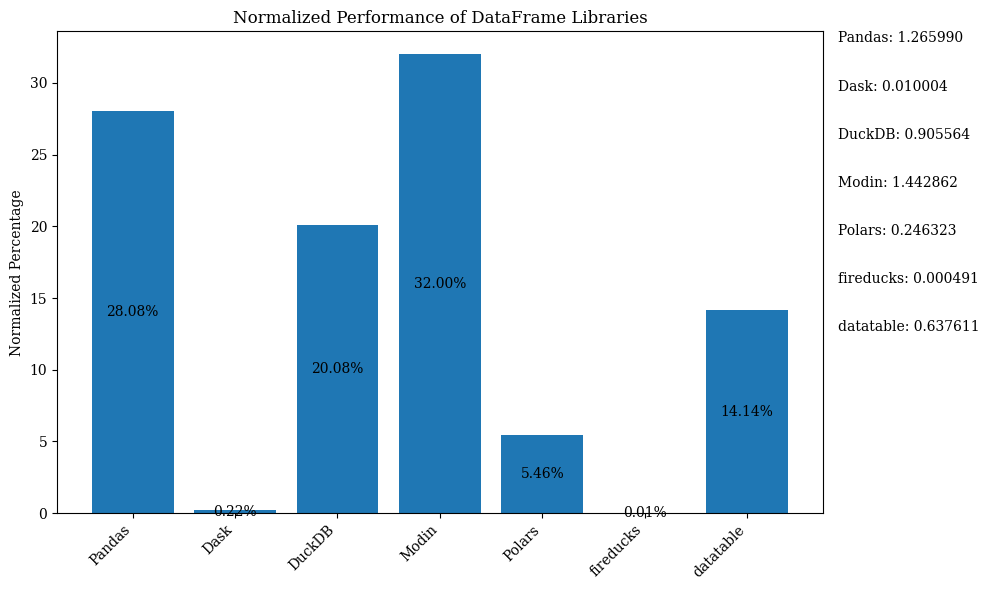
Para el código de Python que muestra el gráfico de barras anterior con datos normalizados, consulte el Jupyter Notebook. Utilice Google Colab ya que FireDucks está disponible solo en Linux
Tabla de comparación
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| Pandas | Moderado | Bajo | N/A (Original) | Conjuntos de datos pequeños a medianos, exploración de datos | Versatilidad, rico ecosistema | Lento con conjuntos de datos grandes, de un solo hilo |
| Dask | Alto | Muy alto | Alto | Conjuntos de datos grandes, computación distribuida | Escala las operaciones de pandas, procesamiento distribuido | Configuración compleja, soporte parcial de la API de pandas |
| DuckDB | Muy alto | Moderado | Bajo | Consultas analíticas, análisis basado en SQL | Consultas SQL rápidas, integración fácil | No apto para cargas de trabajo transaccionales, concurrencia limitada |
| Modin | Alto | Alto | Muy alto | Aceleración de flujos de trabajo existentes de pandas | Adopción sencilla, utilización de múltiples núcleos | Mejoras limitadas en algunos escenarios |
| Polars | Muy alto | Alto | Moderado | Conjuntos de datos de medianos a grandes, críticos en rendimiento | Velocidad excepcional, API moderna | Curva de aprendizaje, problemas con datos muy grandes |
| FireDucks | Muy alto | Alto | Muy alto | Conjuntos de datos grandes, API similar a pandas con rendimiento | Optimización automática, compatibilidad con pandas | Biblioteca más nueva, menos soporte de la comunidad |
| Datatable | Muy alto | Alto | Moderado | Conjuntos de datos grandes en una sola máquina | Procesamiento rápido, uso eficiente de la memoria | Funcionalidades limitadas, sin soporte para Windows |
Esta tabla proporciona una visión general rápida de las fortalezas, limitaciones y mejores casos de uso de cada biblioteca, permitiendo una fácil comparación en diferentes aspectos como rendimiento, escalabilidad y similitud de API con pandas.
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas