













В этом блоге мы собираемся исследовать некоторые ключевые различия между моделями завершения чата (например, теми, которые предоставляются через конечную точку завершения чата) и более продвинутым API-инструментом OpenAI Assistants. Мы разберем, как эти два подхода обрабатывают сообщения, историю разговоров, большие документы, задачи по кодированию, ограничения контекстного окна и многое другое. Мы также рассмотрим, как Assistants API предоставляет дополнительные инструменты – такие как интерпретаторы кода, извлечение документов и вызов функций – которые преодолевают многие ограничения моделей завершения чата.
Понимание моделей завершения чата
- Вы отправляете список сообщений модели.
- Модель генерирует ответ.
- Вы получаете ответ в качестве вывода.
Пример потока завершения чата
Вы спрашиваете: “Какая столица Японии?”
- Модель отвечает: “Столица Японии – Токио.”
Затем вы спрашиваете: “Расскажи что-нибудь о городе.”
- Модель говорит, что у нее нет контекста и не знает, о каком городе вы имеете в виду, потому что она не сохраняет историю сообщений в одном и том же состоянии разговора.
Ограничения моделей завершения чата
1. Нет постоянной истории сообщений
Одним из недостатков является отсутствие истории сообщений. В моделях чатов не автоматически запоминаются предыдущие сообщения. Например, если вы спросите: “Какая столица Японии?” и затем просто скажете: “Расскажи что-нибудь о городе”, модель часто не сможет сослаться на название города, если вы сами не укажете его снова.
2. Отсутствие прямой обработки документов
Модели завершения чата также не поддерживают прямую обработку больших документов. Если у вас есть PDF-файл на 500 страниц и вы хотите задать вопрос вроде: “Какая прибыльная маржа была у моей компании в I квартале 2023 года?”, вам потребуется процесс, называемый расширенная генерация с использованием поиска (RAG). Это включает:
- Преобразование документа в текст
- Разбиение его на более мелкие части
- Преобразование этих частей в эмбеддинги
- Хранение их в векторной базе данных
- Получение необходимых частей во время запроса, а затем передачу их модели в качестве контекста
3. Проблемы с задачами по кодированию
Другая проблема – это обработка вычислительных задач. Если вы просите модели чатов сделать что-то вроде разворачивания строки, модель может сгенерировать неправильный или неполный ответ. Например:
# Example question to a Chat Completion model
reverse("Subscribetotalib")
# Hypothetical incorrect output
# "bilattoebircsubs"
Она также может дать неверную или устаревшую информацию о текущей дате, поскольку не имеет возможности для реального времени вычислений.
4. Ограниченное окно контекста
Модели завершения чата имеют фиксированный максимальный лимит токенов. Если вы превысите этот лимит, вы не сможете передать всю необходимую информацию в один запрос. Это ограничение может нарушить ход разговоров крупномасштабных или контекстно насыщенных задач.
5. Синхронная обработка
Наконец, модели завершения чата синхронны. После того, как вы задали вопрос, вам нужно ждать один ответ. Вы не можете отправлять несколько запросов параллельно и затем объединять результаты без тщательной оркестрации.
Представляем API помощников
API помощников OpenAI решает вышеуказанные проблемы, позволяя вам создавать искусственных помощников с дополнительными возможностями. Он предоставляет:
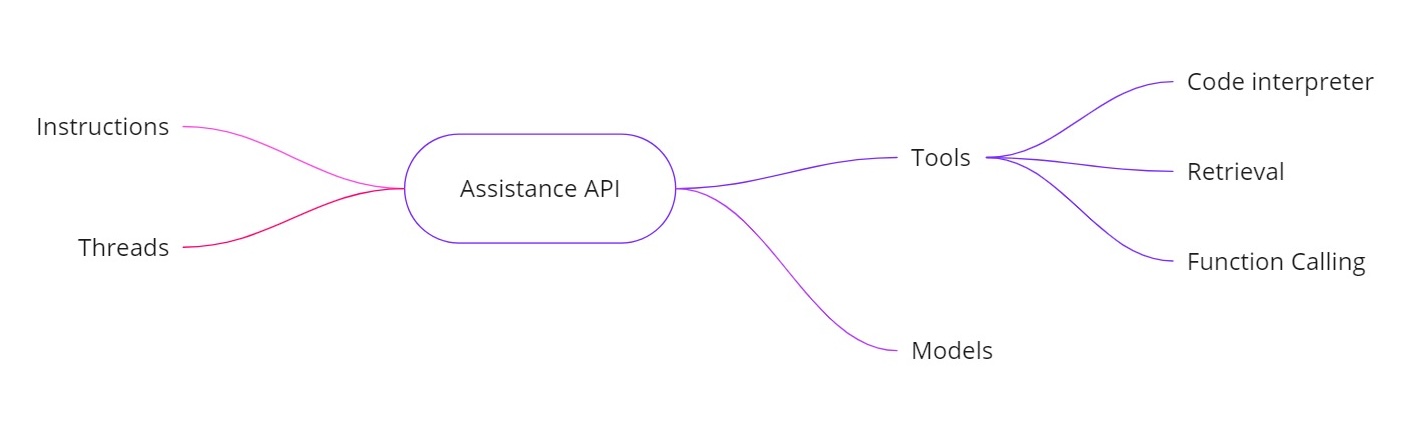
- Инструкции. Подобно системному сообщению, они определяют, что должен делать ваш помощник.
- Ветви. Все предыдущие сообщения хранятся в ветвях, поэтому помощник может сохранять контекст на протяжении нескольких оборотов.
- Инструменты. Сюда входят функции, такие как интерпретатор кода, поиск документов и вызов функций.
- Модели. В настоящее время поддерживается GPT‑4 (1106 preview) и будут поддерживаться индивидуальные модели с тонкой настройкой в будущем.
Инструменты в API помощников
- Интерпретатор кода. Когда запрашивается вычислительная задача — например, реверсирование строки или поиск сегодняшней даты — помощник может использовать инструмент интерпретатора кода для выполнения Python-кода. Затем помощник возвращает правильный результат, а не полагается исключительно на прогнозирование токенов.
- Извлечение. С помощью извлечения вы можете загрузить до 20 файлов (каждый до 52 МБ и до 2 миллионов токенов на файл). Когда вы запрашиваете информацию, помощник может непосредственно ссылаться на эти файлы, что значительно упрощает работу с большими документами.
- Вызов функций. Вы можете определить функцию, которая запрашивает вашу внутреннюю базу данных (для задач, таких как проверка продаж). Помощник запросит вызов этой функции с необходимыми аргументами, и вы затем вернете результаты помощнику. Таким образом, модель может использовать актуальные данные, которых у нее обычно не было бы.
- Обработка более крупных контекстных окон. Потоки в API помощников динамически выбирают, какие сообщения включать в контекст, помогая обрабатывать большие объемы беседы. Это означает, что вы больше не привязаны строго к маленькому контекстному окну.
Пример реализации
Ниже приведен пример кода на Python, показывающий, как создать помощника, установить инструкции, включить инструменты и затем выполнять запросы, используя потоки. Этот код иллюстрирует асинхронный рабочий процесс и использование таких функций, как интерпретация кода.
Создание помощника
# Step 1: Create the Assistant
from openai import OpenAI
client = OpenAI()
my_assistant = client.beta.assistants.create(
instructions="You are a personal math tutor. When asked a question, write and run Python code to answer the question.",
name="Math Tutor",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview",
)
print(my_assistant)
Создание потока
# Step 2: Create a Thread
thread = client.beta.threads.create()
print(f"Thread ID: {thread.id}")
'''
Response
{
"id": "thread_abc123",
"object": "thread",
"created_at": 1699012949,
"metadata": {},
"tool_resources": {}
}
'''
print(json.dumps(run.model_dump(), indent =4))
Задание вопроса
# Step 3: Ask a Question
question_1 = "Reverse the string 'openaichatgpt'."
message_1 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_1
)
Асинхронное выполнение запроса
# Run the Query Asynchronously
run_1 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the run status
current_run = client.beta.threads.runs.retrieve(run_id=run_1.id)
print(f"Initial Run Status: {current_run.status}")
# Once completed, retrieve the messages
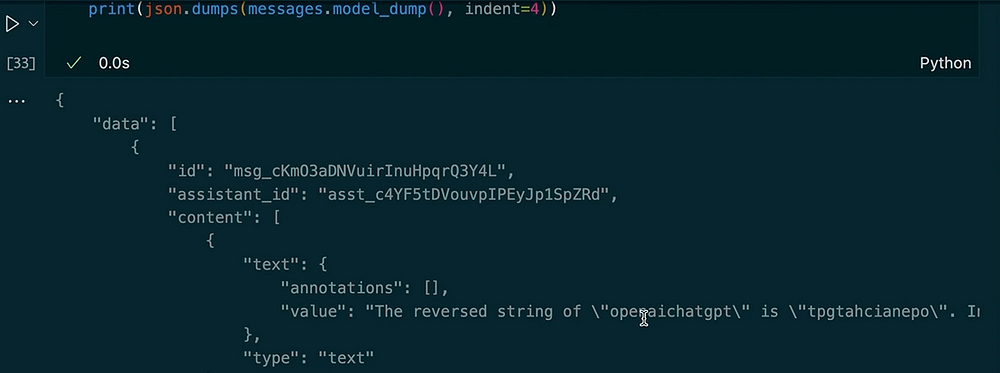
messages = client.beta.threads.messages.list(thread_id=thread.id)
print(json.dumps(messages.model_dumps(), indent=4))
Вывод:
Задание другого вопроса в том же потоке
# Ask Another Question in the Same Thread
question_2 = "Make the previous input uppercase and tell me the length of the string."
message_2 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_2
)
# Run the second query
run_2 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the new run status
current_run_2 = client.beta.threads.runs.retrieve(run_id=run_2.id)
print(f"Second Run Status: {current_run_2.status}")
# Retrieve the new messages
messages_2 = client.beta.threads.messages.list(thread_id=thread.id)
for msg in messages_2:
print(msg.content)
В выводе:

В этом примере вы можете видеть, как поток сохраняет контекст. Когда мы просим помощника перевернуть строку, он использует инструмент интерпретации кода. Затем мы запрашиваем версию в верхнем регистре предыдущего ввода и получаем его длину. Помощник помнит наш предыдущий вопрос благодаря сохраненным сообщениям в потоке.
API помощников OpenAI предоставляет надежный набор функций, которые выходят за рамки типичных моделей завершения чата. Он отслеживает историю сообщений, поддерживает извлечение больших документов, выполняет код Python для вычислений, управляет более крупными контекстами и позволяет вызывать функции для расширенной интеграции. Если вам нужны вычисления в реальном времени, вопросы и ответы на основе документов или более динамичное взаимодействие в ваших приложениях с искусственным интеллектом, API помощников предлагает решения, которые решают основные ограничения стандартных завершений чата.
Используя эти инструкции, потоки, инструменты (например, интерпретатор кода и извлечение) и вызов функций, вы можете создавать сложных помощников по искусственному интеллекту, которые без проблем справляются со всем, начиная от переворачивания строк до запросов к внутренним базам данных. Этот новый подход может изменить способ, которым мы создаем и используем системы на основе искусственного интеллекта в реальных сценариях.
Спасибо за внимание!
Давайте подключимся в LinkedIn!
Source:
https://dzone.com/articles/chat-completion-models-vs-openai-assitance-api