













Neste blog, vamos explorar algumas diferenças fundamentais entre os modelos de conclusão de chat (como aqueles fornecidos pelo endpoint de Conclusões de Chat) e a API mais avançada do OpenAI Assistants. Vamos detalhar como essas duas abordagens lidam com mensagens, histórico de conversa, documentos grandes, tarefas de codificação, limites da janela de contexto e mais. Também veremos como a API Assistants fornece ferramentas adicionais — como interpretadores de código, recuperação de documentos e chamadas de função — que superam muitas limitações das conclusões de chat.
Entendendo os Modelos de Conclusão de Chat
- Você envia uma lista de mensagens para o modelo.
- O modelo gera uma resposta.
- Você recebe a resposta como saída.
Exemplo de Fluxo de Conclusões de Chat
Você pergunta: “Qual é a capital do Japão?”
- O modelo responde: “A capital do Japão é Tóquio.”
Então, você pergunta: “Me conte algo sobre a cidade.”
- O modelo diz que não tem contexto e não sabe qual cidade você está se referindo porque não acompanha inherentemente o histórico das mensagens no mesmo estado de conversa.
Limitações dos Modelos de Conclusão de Chat
1. Sem Histórico de Mensagens Persistente
Uma desvantagem é a falta de histórico de mensagens. Nas conclusões de chat, o modelo não se lembra automaticamente das mensagens anteriores. Por exemplo, se você primeiro perguntar: “Qual é a capital do Japão?” e então simplesmente disser: “Me conte algo sobre a cidade”, o modelo muitas vezes não consegue referenciar o nome da cidade a menos que você o forneça manualmente novamente.
2. Sem Manipulação Direta de Documentos
Os modelos de conclusão de chat também não suportam diretamente a manipulação de grandes documentos. Se você tiver um PDF de 500 páginas e quiser consultar algo como: “Qual foi a margem de lucro da minha empresa no Q1 de 2023?”, você precisaria de um processo chamado geração aumentada por recuperação (RAG). Isso envolve:
- Converter o documento em texto
- Dividi-lo em partes menores
- Converter essas partes em embeddings
- Armazená-las em um banco de dados vetorial
- Recuperar as partes relevantes no momento da consulta e, em seguida, passá-las como contexto para o modelo
3. Desafios com Tarefas de Programação
Outro problema é lidar com tarefas computacionais. Se você pedir às conclusões de chat para fazer algo como inverter uma string, o modelo pode gerar uma resposta errada ou incompleta. Por exemplo:
# Example question to a Chat Completion model
reverse("Subscribetotalib")
# Hypothetical incorrect output
# "bilattoebircsubs"
Ele também pode fornecer informações incorretas ou desatualizadas sobre a data atual, uma vez que não possui capacidades computacionais em tempo real.
4. Janela de Contexto Limitada
Os modelos de conclusão de chat têm um limite máximo fixo de tokens. Se você exceder esse limite, não poderá passar todas as informações necessárias em uma única solicitação. Essa limitação pode interromper o fluxo de conversas em larga escala ou tarefas com muito contexto.
5. Processamento Síncrono
Por fim, os modelos de conclusão de chat são síncronos. Uma vez que você faz uma pergunta, é necessário aguardar por uma única resposta. Você não pode enviar várias solicitações em paralelo e depois combinar os resultados sem uma orquestração cuidadosa.
Apresentando a API de Assistentes
A API de Assistentes da OpenAI aborda os desafios acima permitindo que você construa assistentes de IA com capacidades adicionais. Ela fornece:
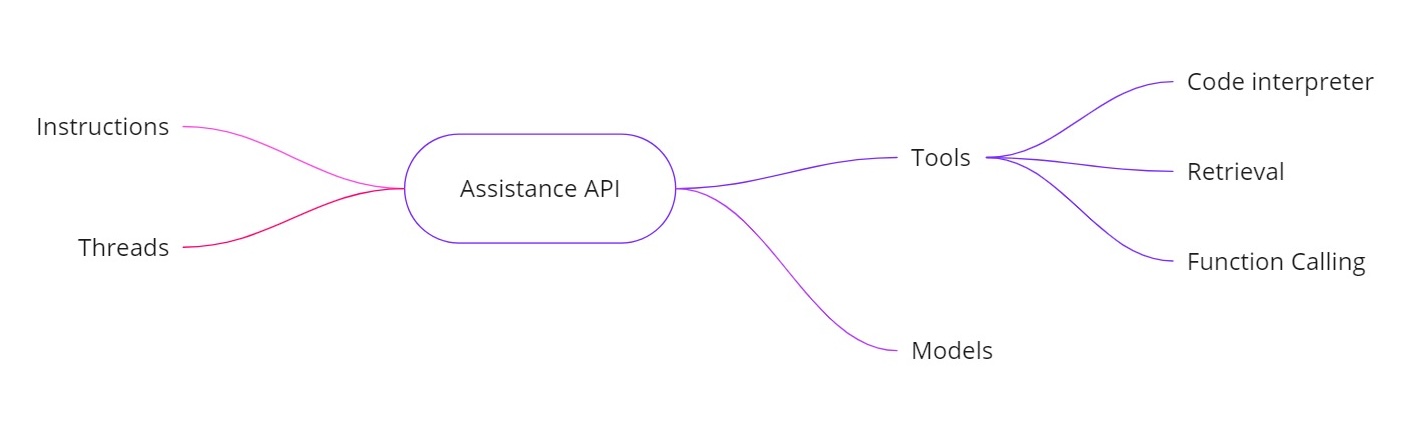
- Instruções. Semelhante a uma mensagem do sistema, essas definem o que seu assistente deve fazer.
- Threads. Todas as mensagens anteriores são armazenadas em threads, para que o assistente possa manter o contexto ao longo de várias interações.
- Ferramentas. Estas incluem recursos como um interpretador de código, recuperação de documentos e chamada de funções.
- Modelos. Atualmente suporta o GPT‑4 (prévia 1106) e suportará modelos personalizados ajustados no futuro.
Ferramentas na API de Assistentes
- Interpretador de código. Quando uma tarefa computacional é solicitada — como inverter uma string ou encontrar a data de hoje — o assistente pode usar uma ferramenta de interpretador de código para executar código Python. O assistente então retorna o resultado correto, em vez de depender apenas de previsões de tokens.
- Recuperação. Com a recuperação, você pode enviar até 20 arquivos (cada um com até 52 MB e até 2 milhões de tokens por arquivo). Quando você faz uma consulta, o assistente pode referenciar esses arquivos diretamente, tornando o manuseio de documentos grandes muito mais simples.
- Chamada de função. Você pode definir uma função que consulta seu banco de dados interno (para tarefas como verificar números de vendas). O assistente solicitará a chamada dessa função com os argumentos necessários, e você então retornará os resultados ao assistente. Dessa forma, o modelo pode utilizar dados atualizados que normalmente não teria.
- Manipulação de janelas de contexto maiores. Os threads na API dos Assistentes selecionam dinamicamente quais mensagens incluir como contexto, ajudando a lidar com maiores quantidades de conversa. Isso significa que você não está mais estritamente vinculado a uma pequena janela de contexto.
Exemplo de Implementação
Abaixo está um trecho de código Python mostrando como criar um assistente, definir instruções, habilitar ferramentas e então executar consultas usando threads. Este código ilustra o fluxo de trabalho assíncrono e o uso de recursos como interpretação de código.
Criando o Assistente
# Step 1: Create the Assistant
from openai import OpenAI
client = OpenAI()
my_assistant = client.beta.assistants.create(
instructions="You are a personal math tutor. When asked a question, write and run Python code to answer the question.",
name="Math Tutor",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview",
)
print(my_assistant)
Criando um Thread
# Step 2: Create a Thread
thread = client.beta.threads.create()
print(f"Thread ID: {thread.id}")
'''
Response
{
"id": "thread_abc123",
"object": "thread",
"created_at": 1699012949,
"metadata": {},
"tool_resources": {}
}
'''
print(json.dumps(run.model_dump(), indent =4))
Fazendo uma Pergunta
# Step 3: Ask a Question
question_1 = "Reverse the string 'openaichatgpt'."
message_1 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_1
)
Executando a Consulta Assincronamente
# Run the Query Asynchronously
run_1 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the run status
current_run = client.beta.threads.runs.retrieve(run_id=run_1.id)
print(f"Initial Run Status: {current_run.status}")
# Once completed, retrieve the messages
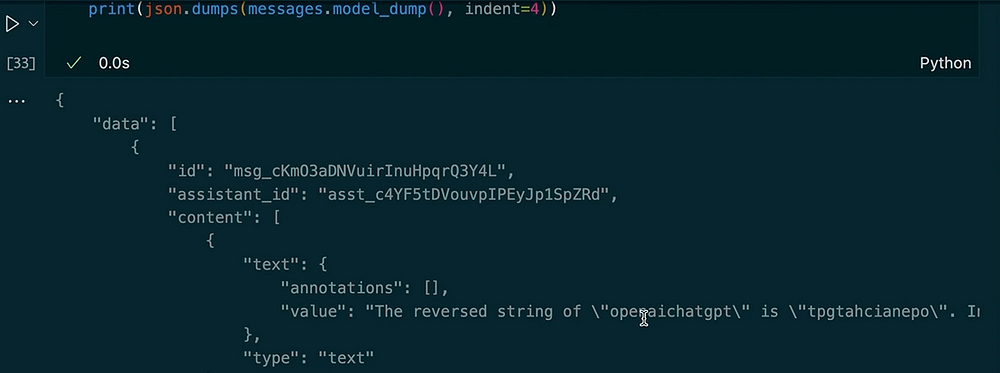
messages = client.beta.threads.messages.list(thread_id=thread.id)
print(json.dumps(messages.model_dumps(), indent=4))
Saída:
Fazendo Outra Pergunta na Mesma Conversa
# Ask Another Question in the Same Thread
question_2 = "Make the previous input uppercase and tell me the length of the string."
message_2 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_2
)
# Run the second query
run_2 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the new run status
current_run_2 = client.beta.threads.runs.retrieve(run_id=run_2.id)
print(f"Second Run Status: {current_run_2.status}")
# Retrieve the new messages
messages_2 = client.beta.threads.messages.list(thread_id=thread.id)
for msg in messages_2:
print(msg.content)
Saída:

Neste exemplo, você pode ver como a conversa mantém o contexto. Quando pedimos ao assistente para inverter a string, ele usa a ferramenta de intérprete de código. Em seguida, pedimos uma versão em maiúsculas da entrada anterior e obtemos o comprimento. O assistente lembra da nossa pergunta anterior devido às mensagens armazenadas na conversa.
A API dos Assistentes da OpenAI oferece um conjunto robusto de recursos que vai além dos modelos típicos de conclusão de chat. Ela mantém o registro do histórico de mensagens, suporta a recuperação de documentos grandes, executa código Python para cálculos, gerencia contextos maiores e permite chamadas de função para integrações avançadas. Se você precisa de cálculos em tempo real, perguntas e respostas baseadas em documentos ou interações mais dinâmicas em suas aplicações de IA, a API dos Assistentes oferece soluções que abordam as limitações centrais das conclusões de chat padrão.
Usando essas instruções, conversas, ferramentas (como intérprete de código e recuperação) e chamadas de função, você pode criar assistentes de IA sofisticados que lidam perfeitamente com tudo, desde inverter strings até consultar bancos de dados internos. Essa nova abordagem pode transformar a maneira como construímos e usamos sistemas impulsionados por IA em cenários do mundo real.
Obrigado por ler!
Vamos nos conectar no LinkedIn!
Source:
https://dzone.com/articles/chat-completion-models-vs-openai-assitance-api