













在这个博客中,我们将探讨聊天完成模型(如通过Chat Completions终端提供的模型)与更先进的OpenAI Assistants API之间的一些关键区别。我们将分析这两种方法如何处理消息、对话历史、大型文档、编码任务、上下文窗口限制等。我们还将看看Assistants API如何提供额外工具——如代码解释器、文档检索和函数调用——来克服许多聊天完成的限制。
了解聊天完成模型
- 您向模型发送消息列表。
- 模型生成响应。
- 您将响应作为输出接收。
聊天完成示例流程
您问:“日本的首都是哪里?”
- 模型回答:“日本的首都是东京。”
然后,您问:“告诉我关于这个城市的一些事情。”
- 模型表示没有上下文,不知道您指的是哪个城市,因为它并不会固有地跟踪同一对话状态中的消息历史。
聊天完成模型的限制
1. 没有持久的消息历史
一个缺点是缺乏消息历史。在聊天完成中,模型不会自动记住先前的消息。例如,如果你首先问:“日本的首都是什么?”然后简单地说:“告诉我一些关于这个城市的事”,模型通常无法引用城市的名称,除非你手动再次提供它。
2. 不支持直接处理文档
聊天完成模型也不直接支持处理大型文档。如果你有一个500页的PDF,并想查询类似“我公司在2023年第一季度的利润率是多少?”的问题,你需要一个称为检索增强生成(RAG)的过程。这包括:
- 将文档转换为文本
- 将其分割为更小的块
- 将这些块转换为嵌入
- 将它们存储在向量数据库中
- 在查询时检索相关块,然后将它们作为上下文传递给模型
3. 编码任务的挑战
另一个问题是处理计算任务。如果你要求聊天完成做一些像反转字符串的事情,模型可能会生成错误或不完整的答案。例如:
# Example question to a Chat Completion model
reverse("Subscribetotalib")
# Hypothetical incorrect output
# "bilattoebircsubs"
它也可能提供关于当前日期的不正确或过时的信息,因为它缺乏实时计算能力。
4. 有限的上下文窗口
聊天生成模型有一个固定的最大令牌限制。如果超过这个限制,就无法将所有必要的信息放入一个请求中。这一限制可能会干扰大规模对话或以上下文为重的任务的流畅性。
5. 同步处理
最后,聊天生成模型是同步的。一旦你提出问题,就必须等待单一的回答。你不能并行提交多个请求,然后在没有精心协调的情况下合并结果。
介绍助手API
OpenAI助手API 通过允许你构建具有额外功能的AI助手来解决上述挑战。它提供:
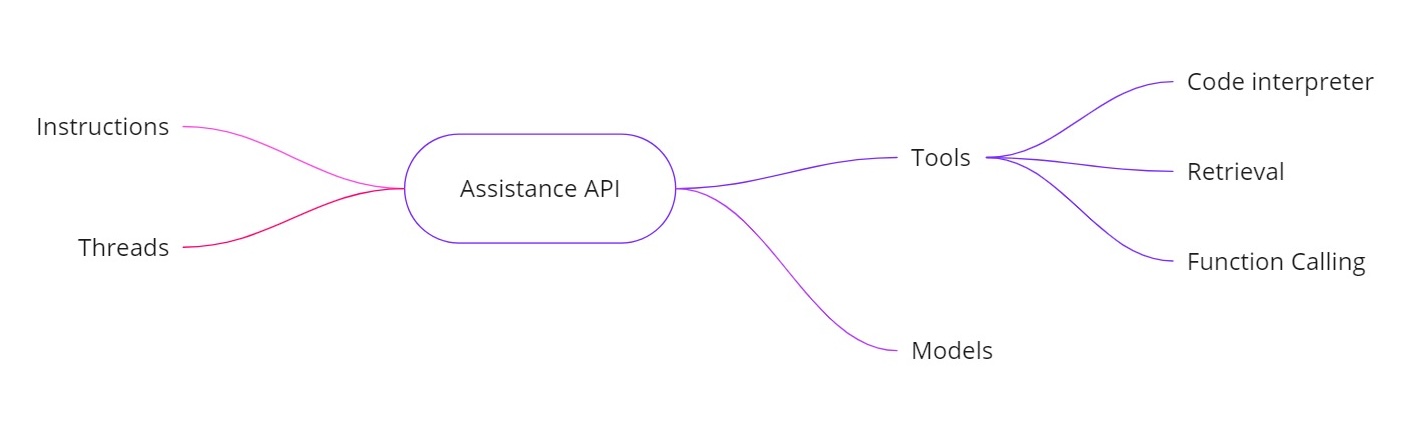
- 指令。类似于系统消息,这些指令定义了你的助手应该做什么。
- 线程。所有先前的消息都存储在线程中,以便助手可以在多个回合中保持上下文。
- 工具。这些包括代码解释器、文档检索和函数调用等功能。
- 模型。它目前支持GPT‑4(1106预览),未来将支持自定义微调模型。
助手API中的工具
- 代码解释器。当请求进行计算任务时,比如反转字符串或查找今天的日期,助手可以使用代码解释器工具来运行Python代码。助手然后返回正确的结果,而不仅仅依靠令牌预测。
- 检索。通过检索,您可以上传多达20个文件(每个文件最多52 MB,每个文件最多200万个令牌)。当您进行查询时,助手可以直接引用这些文件,使大型文档处理变得更加简单。
- 函数调用。您可以定义一个查询内部数据库的函数(用于任务如检查销售数据)。助手将请求调用该函数并提供所需的参数,然后您将结果返回给助手。这样,模型可以利用通常无法获得的最新数据。
- 处理更大的上下文窗口。助手API中的线程动态选择要包含在上下文中的消息,帮助处理更多的对话内容。这意味着您不再严格受限于一个小的上下文窗口。
示例实现
下面是一个示例Python代码片段,展示如何创建一个助手,设置指令,启用工具,然后使用线程运行查询。这段代码说明了异步工作流程以及代码解释等功能的使用。
创建助手
# Step 1: Create the Assistant
from openai import OpenAI
client = OpenAI()
my_assistant = client.beta.assistants.create(
instructions="You are a personal math tutor. When asked a question, write and run Python code to answer the question.",
name="Math Tutor",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview",
)
print(my_assistant)
创建一个线程
# Step 2: Create a Thread
thread = client.beta.threads.create()
print(f"Thread ID: {thread.id}")
'''
Response
{
"id": "thread_abc123",
"object": "thread",
"created_at": 1699012949,
"metadata": {},
"tool_resources": {}
}
'''
print(json.dumps(run.model_dump(), indent =4))
提出问题
# Step 3: Ask a Question
question_1 = "Reverse the string 'openaichatgpt'."
message_1 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_1
)
异步运行查询
# Run the Query Asynchronously
run_1 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the run status
current_run = client.beta.threads.runs.retrieve(run_id=run_1.id)
print(f"Initial Run Status: {current_run.status}")
# Once completed, retrieve the messages
messages = client.beta.threads.messages.list(thread_id=thread.id)
print(json.dumps(messages.model_dumps(), indent=4))
输出:
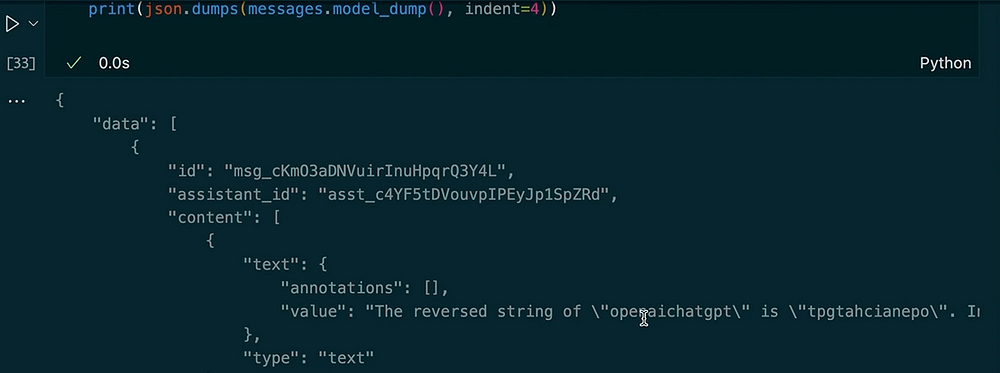
在同一个线程中提出另一个问题
# Ask Another Question in the Same Thread
question_2 = "Make the previous input uppercase and tell me the length of the string."
message_2 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_2
)
# Run the second query
run_2 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the new run status
current_run_2 = client.beta.threads.runs.retrieve(run_id=run_2.id)
print(f"Second Run Status: {current_run_2.status}")
# Retrieve the new messages
messages_2 = client.beta.threads.messages.list(thread_id=thread.id)
for msg in messages_2:
print(msg.content)
输出:

在这个示例中,您可以看到线程如何保持上下文。当我们要求助手反转字符串时,它使用了代码解释工具。接下来,我们要求前一个输入的大写版本并获取长度。助手会记住我们之前的问题,这是由于存储的线程消息。
OpenAI Assistants API提供了一套强大的功能,超越了典型的聊天完成模型。它可以跟踪消息历史记录,支持大型文档检索,执行Python代码进行计算,管理更大的上下文,并允许进行函数调用以实现高级集成。如果您需要实时计算、基于文档的问答,或者在AI应用中需要更动态的交互,Assistants API提供的解决方案可以解决标准聊天完成的核心限制。
使用这些说明、线程、工具(如代码解释器和检索)以及函数调用,您可以创建出色的AI助手,无缝处理从字符串反转到查询内部数据库的所有内容。这种新方法可以改变我们在真实场景中构建和使用基于AI的系统的方式。
感谢您的阅读!
Source:
https://dzone.com/articles/chat-completion-models-vs-openai-assitance-api