













このブログでは、チャット完了モデル(チャット完了エンドポイントを介して提供されるもの)と、より高度なOpenAIアシスタントAPIのいくつかの重要な違いを探ります。これらの2つのアプローチがメッセージ、会話履歴、大きな文書、コーディングタスク、コンテキストウィンドウの制限などをどのように処理するかを分解します。また、アシスタントAPIが、チャット完了の多くの制限を克服するための追加ツール(コードインタープリタ、文書取得、関数呼び出しなど)をどのように提供するかについても見ていきます。
チャット完了モデルの理解
- モデルにメッセージのリストを送信します。
- モデルは応答を生成します。
- 応答を出力として受け取ります。
チャット完了の例の流れ
あなたが尋ねます: “日本の首都はどこですか?”
- モデルは応答します: “日本の首都は東京です。”
次に、あなたが尋ねます: “その都市について何か教えてください。”
- モデルは、コンテキストがないため、どの都市を指しているのかわからないと答えます。なぜなら、同じ会話の状態でメッセージ履歴を本質的に追跡していないからです。
チャット完了モデルの制限
1. 永続的なメッセージ履歴なし
1つの欠点は、メッセージ履歴の不足です。 チャットの完了では、モデルは以前のメッセージを自動的に記憶しません。 たとえば、「日本の首都は何ですか?」と最初に尋ねてから単に「その都市について何か教えてください」と言うと、モデルは都市の名前を参照できないことがよくあります。手動で再度提供する必要があります。
2. 直接文書の取り扱いがない
チャットの完了モデルは、大規模な文書の取り扱いを直接サポートしていません。 たとえば、500ページのPDFを持っていて、「2023年第1四半期に会社がどれだけ利益率を上げたか?」などのクエリをしたい場合、検索増強生成(RAG)というプロセスが必要です。 これには次の手順が含まれます:
- 文書をテキストに変換する
- それを小さなチャンクに分割する
- それらのチャンクを埋め込みに変換する
- それらをベクトルデータベースに保存する
- クエリ時に関連するチャンクを取得し、それをモデルにコンテキストとして渡す
3. コーディングタスクに関する課題
別の問題は、計算タスクの取り扱いです。 文字列を逆にするなどの作業をチャット完了に依頼すると、モデルが間違ったか不完全な回答を生成する可能性があります。 たとえば:
# Example question to a Chat Completion model
reverse("Subscribetotalib")
# Hypothetical incorrect output
# "bilattoebircsubs"
また、リアルタイムの計算能力がないため、現在の日付に関する誤ったまたは古い情報を提供することがあります。
4. 限られたコンテキストウィンドウ
チャット補完モデルには、固定の最大トークン制限があります。この制限を超えると、必要なすべての情報を単一のリクエストに送信することができません。この制限により、大規模な会話やコンテキスト重視のタスクの流れが妨げられる可能性があります。
5. 同期処理
最後に、チャット補完モデルは同期的です。質問をすると、単一の応答を待たなければなりません。複数のリクエストを並行して送信して結果を注意深く組み合わせることはできません。
アシスタントAPIの紹介
OpenAIアシスタントAPIは、追加の機能を備えたAIアシスタントを構築できるようにすることで、上記の課題に対処します。以下を提供します:
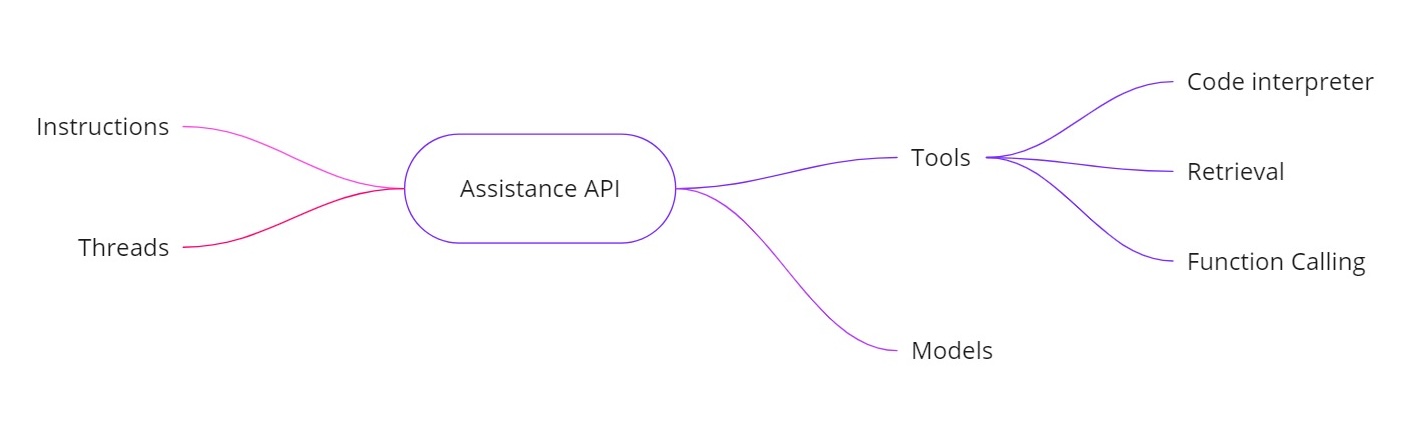
- 指示。システムメッセージと同様に、アシスタントが行うべきことを定義します。
- スレッド。以前のメッセージはすべてスレッドに保存されるため、アシスタントは複数のターンを通じてコンテキストを保持できます。
- ツール。これには、コードインタプリター、ドキュメントの取得、および関数呼び出しなどの機能が含まれます。
- モデル。現在はGPT-4(1106プレビュー)をサポートしており、将来的にはカスタムファインチューニングされたモデルをサポートします。
アシスタントAPIのツール
- コードインタープリター。計算タスクがリクエストされた場合 – 例えば文字列を逆にしたり今日の日付を見つけたりする場合 – アシスタントはPythonコードを実行するためのコードインタープリターツールを使用できます。その後、アシスタントはトークン予測だけに頼らず、正しい結果を返します。
- 検索。検索を使用すると、最大20個のファイル(各ファイル最大52MB、1ファイルあたり最大200万トークン)をアップロードできます。クエリ時に、アシスタントはそれらのファイルを直接参照し、大規模なドキュメントの処理を簡略化できます。
- 関数呼び出し。セールスデータを確認するなど、内部データベースをクエリする関数を定義できます。アシスタントは、必要な引数でその関数を呼び出すように要求し、その結果をアシスタントに返します。これにより、モデルは通常は持っていない最新データを利用できます。
- より大きなコンテキストウィンドウの扱い。Assistants APIのスレッドは、どのメッセージをコンテキストとして含めるかを動的に選択し、会話の大量処理をサポートします。つまり、もはや小さなコンテキストウィンドウに厳密に拘束される必要はありません。
実装例
以下は、アシスタントの作成方法、命令の設定、ツールの有効化、およびスレッドを使用したクエリの実行方法を示すサンプルPythonスニペットです。このコードは非同期ワークフローとコード解釈などの機能の使用を示しています。
アシスタントの作成
# Step 1: Create the Assistant
from openai import OpenAI
client = OpenAI()
my_assistant = client.beta.assistants.create(
instructions="You are a personal math tutor. When asked a question, write and run Python code to answer the question.",
name="Math Tutor",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview",
)
print(my_assistant)
スレッドの作成
# Step 2: Create a Thread
thread = client.beta.threads.create()
print(f"Thread ID: {thread.id}")
'''
Response
{
"id": "thread_abc123",
"object": "thread",
"created_at": 1699012949,
"metadata": {},
"tool_resources": {}
}
'''
print(json.dumps(run.model_dump(), indent =4))
質問の提示
# Step 3: Ask a Question
question_1 = "Reverse the string 'openaichatgpt'."
message_1 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_1
)
クエリを非同期で実行
# Run the Query Asynchronously
run_1 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the run status
current_run = client.beta.threads.runs.retrieve(run_id=run_1.id)
print(f"Initial Run Status: {current_run.status}")
# Once completed, retrieve the messages
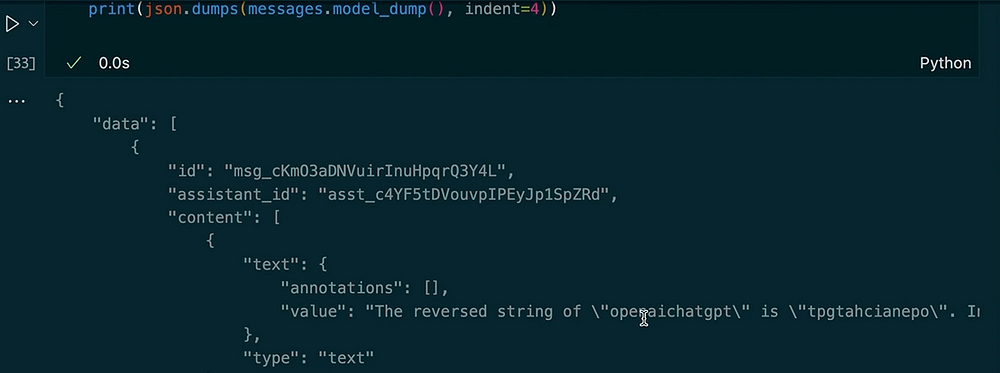
messages = client.beta.threads.messages.list(thread_id=thread.id)
print(json.dumps(messages.model_dumps(), indent=4))
出力:
同じスレッドで別の質問をする
# Ask Another Question in the Same Thread
question_2 = "Make the previous input uppercase and tell me the length of the string."
message_2 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_2
)
# Run the second query
run_2 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the new run status
current_run_2 = client.beta.threads.runs.retrieve(run_id=run_2.id)
print(f"Second Run Status: {current_run_2.status}")
# Retrieve the new messages
messages_2 = client.beta.threads.messages.list(thread_id=thread.id)
for msg in messages_2:
print(msg.content)
出力:

この例では、スレッドがコンテキストを保持していることがわかります。アシスタントに文字列を逆にするように依頼すると、コードインタープリターツールが使用されます。次に、前の入力の大文字バージョンを要求し、長さを取得します。アシスタントは、保存されたスレッドメッセージによって以前の質問を覚えています。
OpenAI Assistants APIは、典型的なチャット補完モデルを超える機能の堅牢なセットを提供しています。メッセージ履歴を追跡し、大規模なドキュメントの取得をサポートし、Pythonコードを実行して計算を行い、大きなコンテキストを管理し、高度な統合のための関数呼び出しを可能にします。リアルタイムの計算、ドキュメントベースのQ&A、またはAIアプリケーションでのより動的な相互作用が必要な場合、Assistants APIは、標準的なチャット補完の主な制限に対処するソリューションを提供しています。
これらの手順、スレッド、ツール(コードインタプリターや取得など)、および関数呼び出しを使用すると、文字列を逆にしたり、内部データベースのクエリを実行するなど、さまざまなことをシームレスに処理する洗練されたAIアシスタントを作成できます。この新しいアプローチは、現実世界のシナリオでAI駆動システムを構築し使用する方法を変革することができます。
お読みいただきありがとうございます!
LinkedInでつながりましょう!
Source:
https://dzone.com/articles/chat-completion-models-vs-openai-assitance-api