













이 블로그에서는 채팅 완성 모델(채팅 완성 엔드포인트를 통해 제공되는 것과 같은)과 더 고급 OpenAI 어시스턴트 API 간의 주요 차이를 탐색할 것입니다. 이 두 접근 방식이 메시지, 대화 기록, 대형 문서, 코딩 작업, 컨텍스트 창 제한 등을 처리하는 방법을 자세히 살펴볼 것입니다. 또한 어시스턴트 API가 코드 해석기, 문서 검색, 함수 호출과 같은 추가 도구를 제공하여 채팅 완성의 많은 제한을 극복하는 방법도 살펴볼 것입니다.
채팅 완성 모델 이해
- 모델에 메시지 목록을 보냅니다.
- 모델이 응답을 생성합니다.
- 응답을 출력으로 받습니다.
채팅 완성 예시 흐름
질문합니다: “일본의 수도는 무엇인가요?”
- 모델이 응답합니다: “일본의 수도는 도쿄입니다.”
그런 다음 다음과 같이 질문합니다: “도시에 대해 알려주세요.”
- 모델은 컨텍스트가 없다고 말하며, 동일 대화 상태에서 메시지 기록을 내재적으로 유지하지 않기 때문에 어떤 도시를 의미하는지 알 수 없다고 합니다.
채팅 완성 모델의 제한
1. 지속적인 메시지 기록이 없음
한 가지 단점은 메시지 기록의 부재입니다. 채팅 완성물에서 모델은 이전 메시지를 자동으로 기억하지 않습니다. 예를 들어, “일본의 수도는 무엇입니까?”라고 먼저 묻고 나중에 간단히 “그 도시에 대해 알려주세요.”라고 말하면 모델은 종종 도시의 이름을 참조할 수 없습니다. 수동으로 다시 제공하지 않는 한.
2. 직접 문서 처리 불가능
채팅 완성 모델은 큰 문서를 직접 처리하는 것을 지원하지 않습니다. 500 페이지짜리 PDF를 가지고 있고 “2023년 제1분기에 회사가 얼마의 이윤율을 올렸는지”와 같은 쿼리를 하려면, 검색 보강 생성 (RAG)이라는 과정이 필요합니다. 이 과정은 다음과 같습니다:
- 문서를 텍스트로 변환
- 작은 청크로 분할
- 그 청크를 임베딩으로 변환
- 벡터 데이터베이스에 저장
- 쿼리 시 관련 청크를 검색한 다음 모델에 컨텍스트로 전달
3. 코딩 작업에 대한 도전
다른 문제는 계산 작업을 처리하는 것입니다. 채팅 완성물에게 문자열을 뒤집는 등의 작업을 수행하도록 요청하면, 모델은 잘못된 또는 불완전한 답변을 생성할 수 있습니다. 예를 들어:
# Example question to a Chat Completion model
reverse("Subscribetotalib")
# Hypothetical incorrect output
# "bilattoebircsubs"
실시간 계산 능력이 부족하므로 현재 날짜에 대한 잘못된 또는 오래된 정보를 제공할 수도 있습니다.
4. 제한된 컨텍스트 창
채팅 완성 모델은 고정된 최대 토큰 제한이 있습니다. 이 제한을 초과하면 모든 필요한 정보를 단일 요청에 넣을 수 없습니다. 이 제한은 대규모 대화나 맥락이 많은 작업의 흐름을 방해할 수 있습니다.
5. 동기 처리
마지막으로, 채팅 완성 모델은 동기식입니다. 질문을 한 번 하면 단일 응답을 기다려야 합니다. 결과를 조화롭게 조합하지 않고 병렬로 여러 요청을 제출할 수 없습니다.
어시스턴트 API 소개
OpenAI 어시스턴트 API는 추가 기능이 있는 AI 어시스턴트를 구축할 수 있도록 위의 문제를 해결합니다. 다음을 제공합니다:
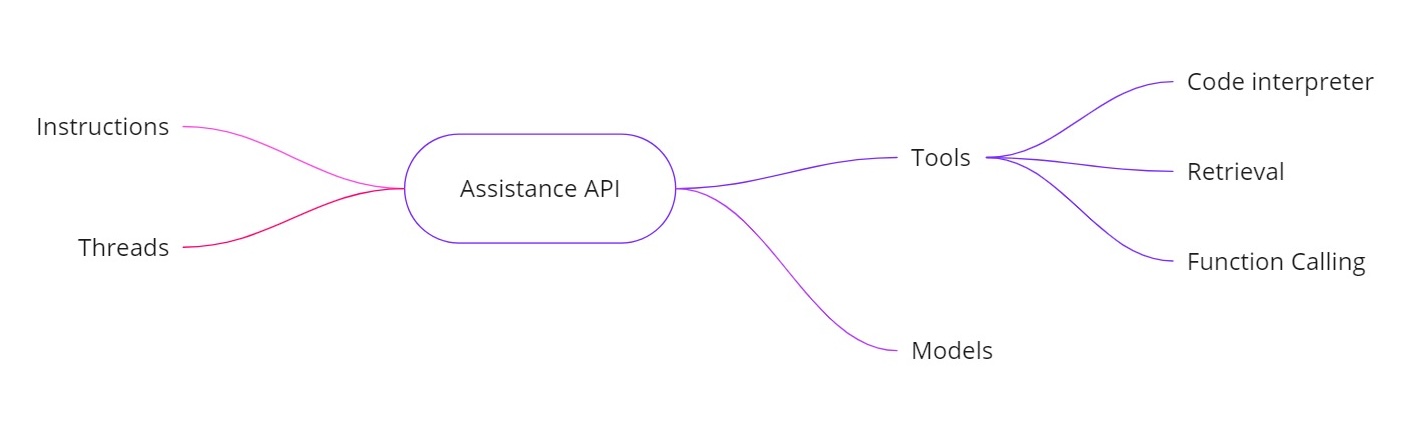
- 지침. 시스템 메시지와 유사하게, 이는 당신의 어시스턴트가 무엇을 해야 하는지를 정의합니다.
- 쓰레드. 이전 메시지가 모두 쓰레드에 저장되므로 어시스턴트는 여러 차례에 걸쳐 맥락을 유지할 수 있습니다.
- 도구. 이에는 코드 해석기, 문서 검색 및 함수 호출과 같은 기능이 포함됩니다.
- 모델. 현재 GPT‑4 (1106 미리보기)를 지원하며 향후 사용자 정의 미세 조정 모델을 지원할 것입니다.
어시스턴트 API의 도구
- 코드 해석기. 계산 작업이 요청될 때 — 예를 들어 문자열 뒤집기 또는 오늘 날짜 찾기 — 조수는 Python 코드를 실행하는 코드 해석기 도구를 사용할 수 있습니다. 그러면 모델은 토큰 예측만에 의존하는 대신 올바른 결과를 반환합니다.
- 검색. 검색을 통해 최대 20개의 파일(각 파일 당 최대 52MB 및 파일 당 최대 200만 토큰)을 업로드할 수 있습니다. 쿼리할 때 조수는 이러한 파일을 직접 참조하여 대량 문서 처리를 훨씬 간단하게 할 수 있습니다.
- 함수 호출. 내부 데이터베이스를 쿼리하는 함수를 정의할 수 있습니다(예: 매출 데이터 확인). 그러면 조수는 필요한 인수로 해당 함수를 호출하도록 요청할 것이며, 그런 다음 결과를 조수에게 반환합니다. 이렇게 하면 모델이 일반적으로 가지지 않는 최신 데이터를 활용할 수 있습니다.
- 더 큰 컨텍스트 창 핸들링. Assistants API의 스레드는 대화에서 포함할 메시지를 동적으로 선택하여 더 많은 대화 양을 처리하는 데 도움을 줍니다. 이렇게 하면 더 이상 작은 컨텍스트 창에 엄격하게 묶이지 않습니다.
예시 구현
아래는 조수를 만들고 지시를 설정하고 도구를 활성화한 다음 스레드를 사용하여 쿼리를 실행하는 방법을 보여주는 샘플 Python 코드 조각입니다. 이 코드는 비동기적인 워크플로우와 코드 해석과 같은 기능 사용법을 설명합니다.
조수 만들기
# Step 1: Create the Assistant
from openai import OpenAI
client = OpenAI()
my_assistant = client.beta.assistants.create(
instructions="You are a personal math tutor. When asked a question, write and run Python code to answer the question.",
name="Math Tutor",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview",
)
print(my_assistant)
스레드 만들기
# Step 2: Create a Thread
thread = client.beta.threads.create()
print(f"Thread ID: {thread.id}")
'''
Response
{
"id": "thread_abc123",
"object": "thread",
"created_at": 1699012949,
"metadata": {},
"tool_resources": {}
}
'''
print(json.dumps(run.model_dump(), indent =4))
질문하기
# Step 3: Ask a Question
question_1 = "Reverse the string 'openaichatgpt'."
message_1 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_1
)
쿼리를 비동기적으로 실행하기
# Run the Query Asynchronously
run_1 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the run status
current_run = client.beta.threads.runs.retrieve(run_id=run_1.id)
print(f"Initial Run Status: {current_run.status}")
# Once completed, retrieve the messages
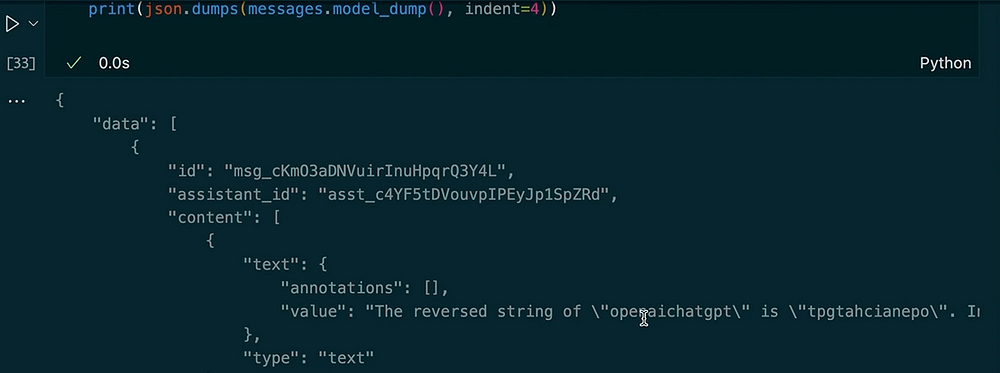
messages = client.beta.threads.messages.list(thread_id=thread.id)
print(json.dumps(messages.model_dumps(), indent=4))
결과:
같은 스레드에서 다른 질문하기
# Ask Another Question in the Same Thread
question_2 = "Make the previous input uppercase and tell me the length of the string."
message_2 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_2
)
# Run the second query
run_2 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the new run status
current_run_2 = client.beta.threads.runs.retrieve(run_id=run_2.id)
print(f"Second Run Status: {current_run_2.status}")
# Retrieve the new messages
messages_2 = client.beta.threads.messages.list(thread_id=thread.id)
for msg in messages_2:
print(msg.content)
출력:

이 예에서는 스레드가 컨텍스트를 유지하는 방법을 볼 수 있습니다. 문자열을 뒤집도록 도우미에게 요청하면 코드 해석 도구를 사용합니다. 다음으로 이전 입력의 대문자 버전을 요청하고 길이를 얻습니다. 도우미는 저장된 스레드 메시지로 인해 이전 질문을 기억합니다.
OpenAI Assistants API는 일반적인 채팅 완성 모델을 넘어 확장된 기능 세트를 제공합니다. 메시지 기록을 추적하고 대량 문서 검색을 지원하며 계산을 위해 Python 코드를 실행하며 대규모 컨텍스트를 관리하고 고급 통합을 위해 함수 호출을 가능하게 합니다. 실시간 계산, 문서 기반 Q&A 또는 AI 애플리케이션에서 더 동적한 상호 작용이 필요한 경우 Assistants API는 표준 채팅 완성의 핵심 제한을 해결하는 솔루션을 제공합니다.
이러한 지침, 스레드, 도구(코드 해석기 및 검색) 및 함수 호출을 사용하여 역방향 문자열부터 내부 데이터베이스 쿼리까지 모든 것을 원활하게 처리하는 정교한 AI 도우미를 만들 수 있습니다. 이 새로운 접근법은 현실 세계 시나리오에서 AI 기반 시스템을 구축하고 사용하는 방식을 변화시킬 수 있습니다.
읽어 주셔서 감사합니다!
LinkedIn에서 연락해요!
Source:
https://dzone.com/articles/chat-completion-models-vs-openai-assitance-api