













In deze blog gaan we enkele belangrijke verschillen verkennen tussen chat-completiemodellen (zoals die worden geleverd via het Chat Completions-eindpunt) en de geavanceerdere OpenAI Assistants API. We zullen analyseren hoe deze twee benaderingen berichten, gespreksgeschiedenis, grote documenten, programmeertaken, contextvenstergrenzen en meer behandelen. We zullen ook bekijken hoe de Assistants API aanvullende tools biedt — zoals code-interpreters, documentopvraging en functieaanroeping — die veel beperkingen van chat-completies overwinnen.
Begrip van Chat Completie Modellen
- Je stuurt een lijst met berichten naar het model.
- Het model genereert een reactie.
- Je ontvangt de reactie als output.
Voorbeeldstroom van Chat Completies
Je vraagt: “Wat is de hoofdstad van Japan?”
- Het model antwoordt: “De hoofdstad van Japan is Tokio.”
Vervolgens vraag je: “Vertel me iets over de stad.”
- Het model zegt dat het geen context heeft en niet weet over welke stad je het hebt, omdat het niet inherent de berichtgeschiedenis bijhoudt in dezelfde gespreksstatus.
Beperkingen van Chat Completie Modellen
1. Geen Persistente Berichtgeschiedenis
Een nadeel is het ontbreken van berichtgeschiedenis. In chatvoltooiingen onthoudt het model niet automatisch eerdere berichten. Als je bijvoorbeeld eerst vraagt: “Wat is de hoofdstad van Japan?” en dan gewoon zegt: “Vertel me iets over de stad,” kan het model vaak niet naar de naam van de stad verwijzen, tenzij je die opnieuw handmatig verstrekt.
2. Geen Directe Documentenverwerking
Chatvoltooiingsmodellen ondersteunen ook niet direct het verwerken van grote documenten. Als je bijvoorbeeld een PDF van 500 pagina’s hebt en iets wilt opvragen zoals: “Hoeveel winstmarge heeft mijn bedrijf gemaakt in het eerste kwartaal van 2023?” dan heb je een proces genaamd retrieval-augmented generation (RAG) nodig. Dit omvat:
- Het document omzetten naar tekst
- Het opsplitsen in kleinere brokken
- Die brokken omzetten naar embeddings
- Ze opslaan in een vector database
- De relevante brokken ophalen op het moment van de query en ze vervolgens als context aan het model doorgeven
3. Uitdagingen bij Coderingstaken
Een ander probleem is het omgaan met rekenkundige taken. Als je chatvoltooiingen vraagt om iets te doen, zoals het omkeren van een string, kan het model een verkeerd of onvolledig antwoord genereren. Bijvoorbeeld:
# Example question to a Chat Completion model
reverse("Subscribetotalib")
# Hypothetical incorrect output
# "bilattoebircsubs"
Het kan ook onjuiste of verouderde informatie geven over de huidige datum, aangezien het geen realtime rekenmogelijkheden heeft.
4. Beperkt Contextvenster
Chat completion models hebben een vast maximum aantal tokens. Als je deze limiet overschrijdt, kun je niet alle benodigde informatie in één verzoek doorgeven. Deze beperking kan de voortgang van grootschalige gesprekken of contextzware taken verstoren.
5. Synchrone verwerking
Ten slotte zijn chat completion-modellen synchroon. Zodra je een vraag stelt, moet je wachten op een enkel antwoord. Je kunt niet meerdere verzoeken parallel indienen en vervolgens de resultaten combineren zonder zorgvuldige orchestratie.
Introductie van de Assistants API
De OpenAI Assistants API adresseert de bovenstaande uitdagingen door je in staat te stellen AI-assistenten met aanvullende mogelijkheden te bouwen. Het biedt:
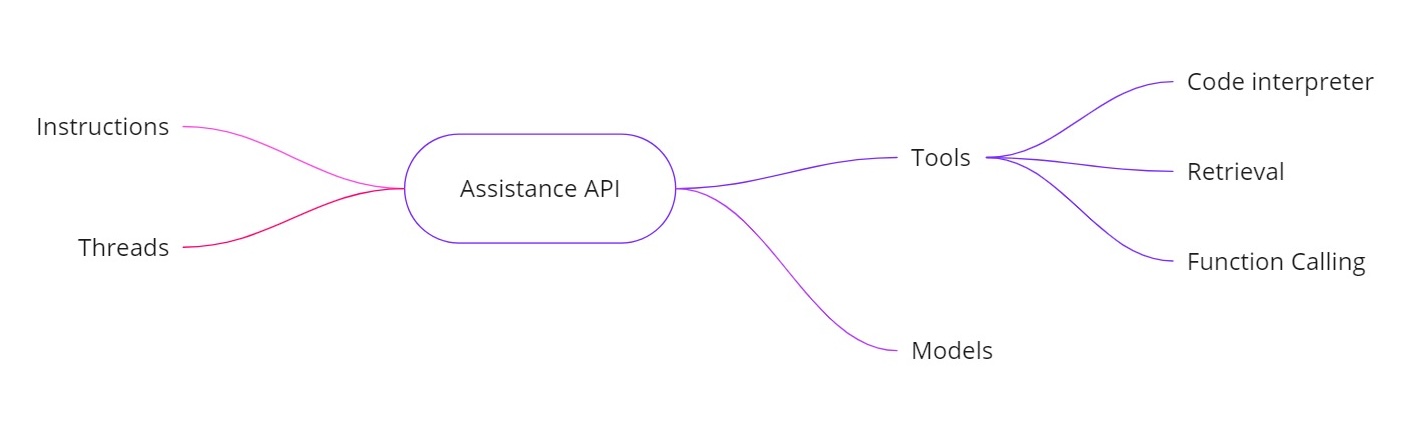
- Instructies. Vergelijkbaar met een systeembericht, deze definiëren wat je assistent moet doen.
- Threads. Alle eerdere berichten worden opgeslagen in threads, zodat de assistent de context over meerdere beurten kan behouden.
- Tools. Deze omvatten functies zoals een code-interpreter, ophalen van documenten en functieaanroepen.
- Modellen. Het ondersteunt momenteel GPT‑4 (1106 preview) en zal in de toekomst aangepaste fijnafgestemde modellen ondersteunen.
Tools in de Assistants API
- Code interpreter. Wanneer een berekeningstaak wordt aangevraagd, zoals het omkeren van een string of het vinden van de datum van vandaag, kan de assistent een code-interpreterstool gebruiken om Python-code uit te voeren. De assistent geeft dan het juiste resultaat terug, in plaats van uitsluitend te vertrouwen op tokenvoorspellingen.
- Opvragen. Met opvragen kunt u tot 20 bestanden uploaden (elk tot 52 MB en tot 2 miljoen tokens per bestand). Wanneer u een query uitvoert, kan de assistent rechtstreeks naar die bestanden verwijzen, waardoor het hanteren van grote documenten veel eenvoudiger wordt.
- Functieoproep. U kunt een functie definiëren die uw interne database bevraagt (voor taken zoals het controleren van verkoopcijfers). De assistent zal vragen om die functie met de vereiste argumenten aan te roepen, en u geeft dan de resultaten terug aan de assistent. Op deze manier kan het model actuele gegevens benutten die het normaal gesproken niet zou hebben.
- Verwerken van grotere contextvensters. De threads in de Assistants API selecteren dynamisch welke berichten moeten worden opgenomen als context, waardoor het beter grote hoeveelheden conversatie aankan. Dit betekent dat u niet langer strikt gebonden bent aan een klein contextvenster.
Voorbeeldimplementatie
Hieronder staat een voorbeeld van een Python-snippet die laat zien hoe u een assistent kunt maken, instructies kunt instellen, tools kunt inschakelen en vervolgens queries kunt uitvoeren met behulp van threads. Deze code illustreert de asynchrone workflow en het gebruik van functies zoals code-interpretatie.
Assistent maken
# Step 1: Create the Assistant
from openai import OpenAI
client = OpenAI()
my_assistant = client.beta.assistants.create(
instructions="You are a personal math tutor. When asked a question, write and run Python code to answer the question.",
name="Math Tutor",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview",
)
print(my_assistant)
Thread maken
# Step 2: Create a Thread
thread = client.beta.threads.create()
print(f"Thread ID: {thread.id}")
'''
Response
{
"id": "thread_abc123",
"object": "thread",
"created_at": 1699012949,
"metadata": {},
"tool_resources": {}
}
'''
print(json.dumps(run.model_dump(), indent =4))
Vraag stellen
# Step 3: Ask a Question
question_1 = "Reverse the string 'openaichatgpt'."
message_1 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_1
)
Query asynchroon uitvoeren
# Run the Query Asynchronously
run_1 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the run status
current_run = client.beta.threads.runs.retrieve(run_id=run_1.id)
print(f"Initial Run Status: {current_run.status}")
# Once completed, retrieve the messages
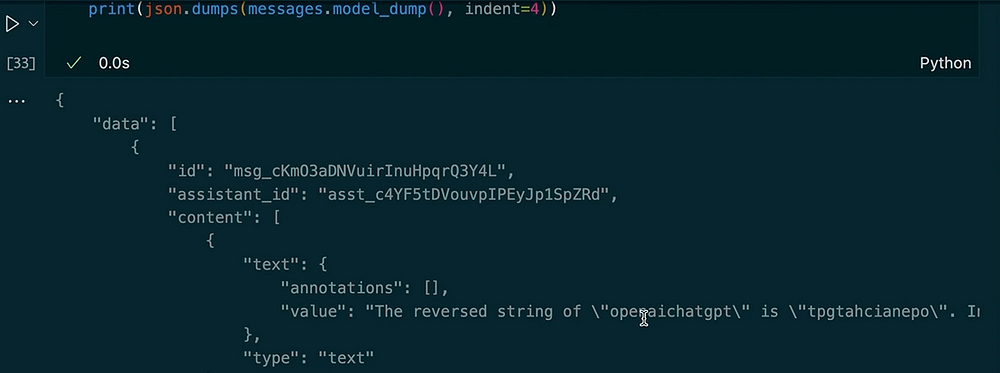
messages = client.beta.threads.messages.list(thread_id=thread.id)
print(json.dumps(messages.model_dumps(), indent=4))
Output:
Een andere vraag stellen in dezelfde thread
# Ask Another Question in the Same Thread
question_2 = "Make the previous input uppercase and tell me the length of the string."
message_2 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_2
)
# Run the second query
run_2 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the new run status
current_run_2 = client.beta.threads.runs.retrieve(run_id=run_2.id)
print(f"Second Run Status: {current_run_2.status}")
# Retrieve the new messages
messages_2 = client.beta.threads.messages.list(thread_id=thread.id)
for msg in messages_2:
print(msg.content)
Uitvoer:

In dit voorbeeld zie je hoe de thread de context behoudt. Wanneer we de assistent vragen om de string om te keren, gebruikt het de code-interpretertool. Vervolgens vragen we om een hoofdletterversie van de vorige invoer en krijgen de lengte ervan. De assistent herinnert zich onze eerdere vraag vanwege de opgeslagen threadberichten.
De OpenAI Assistants API biedt een uitgebreide reeks functies die verder gaan dan de gebruikelijke chat-completiemodellen. Het houdt de berichtengeschiedenis bij, ondersteunt het ophalen van grote documenten, voert Python-code uit voor berekeningen, beheert grotere contexten en maakt functieaanroepen mogelijk voor geavanceerde integraties. Als je realtime berekeningen nodig hebt, op documenten gebaseerde vraag en antwoord, of meer dynamische interacties in je AI-toepassingen, biedt de Assistants API oplossingen die de kernbeperkingen van standaard chat-completies aanpakken.
Met behulp van deze instructies, threads, tools (zoals code-interpreter en ophalen) en functieaanroepen, kun je geavanceerde AI-assistenten creëren die naadloos alles afhandelen, van het omkeren van strings tot het bevragen van interne databases. Deze nieuwe aanpak kan transformeren hoe we AI-gedreven systemen bouwen en gebruiken in real-world scenario’s.
Bedankt voor het lezen!
Source:
https://dzone.com/articles/chat-completion-models-vs-openai-assitance-api