













In questo blog, esploreremo alcune differenze chiave tra i modelli di completamento della chat (come quelli forniti tramite l’endpoint Chat Completions) e l’avanzata API degli OpenAI Assistants. Analizzeremo come questi due approcci gestiscono i messaggi, la cronologia delle conversazioni, i documenti di grandi dimensioni, le attività di codifica, i limiti della finestra di contesto e altro ancora. Esamineremo anche come l’API degli Assistants fornisca strumenti aggiuntivi, come interpreti di codice, recupero di documenti e chiamate di funzioni, che superano molte limitazioni dei completamenti della chat.
Comprensione dei modelli di completamento della chat
- Invii un elenco di messaggi al modello.
- Il modello genera una risposta.
- Ricevi la risposta in output.
Flusso di esempio dei completamenti della chat
Chiedi: “Qual è la capitale del Giappone?”
- Il modello risponde: “La capitale del Giappone è Tokyo.”
Poi, chiedi: “Raccontami qualcosa sulla città.”
- Il modello dice di non avere contesto e di non sapere a quale città ti riferisci perché non tiene intrinsecamente traccia della cronologia dei messaggi nello stesso stato di conversazione.
Limitazioni dei modelli di completamento della chat
1. Nessuna cronologia dei messaggi persistente
Un inconveniente è la mancanza di cronologia dei messaggi. Nelle completamenti della chat, il modello non ricorda automaticamente i messaggi precedenti. Ad esempio, se chiedi prima “Qual è la capitale del Giappone?” e poi dici semplicemente “Dimmi qualcosa sulla città”, il modello spesso non riesce a fare riferimento al nome della città a meno che tu non lo fornisca manualmente di nuovo.
2. Nessuna Gestione Diretta dei Documenti
I modelli di completamento della chat non supportano direttamente la gestione di documenti di grandi dimensioni. Se hai un PDF di 500 pagine e vuoi interrogare qualcosa come “Quanto margine di profitto ha fatto la mia azienda nel primo trimestre del 2023?”, avresti bisogno di un processo chiamato generazione potenziata da recupero (RAG). Questo implica:
- Convertire il documento in testo
- Dividere il documento in segmenti più piccoli
- Convertire quei segmenti in embedding
- Memorizzarli in un database vettoriale
- Recuperare i segmenti rilevanti al momento della query, passandoli poi come contesto al modello
3. Sfide Con Compiti di Codifica
Un altro problema è gestire compiti computazionali. Se chiedi ai completamenti della chat di fare qualcosa come invertire una stringa, il modello potrebbe generare una risposta sbagliata o incompleta. Ad esempio:
# Example question to a Chat Completion model
reverse("Subscribetotalib")
# Hypothetical incorrect output
# "bilattoebircsubs"
Potrebbe anche fornire informazioni sbagliate o obsolete sulla data attuale, poiché manca di capacità computazionali in tempo reale.
4. Finestra di Contesto Limitata
I modelli di completamento della chat hanno un limite massimo fisso di token. Se superi questo limite, non puoi inserire tutte le informazioni necessarie in una singola richiesta. Questa limitazione può interrompere il flusso delle conversazioni su larga scala o dei compiti ricchi di contesto.
5. Elaborazione sincrona
Infine, i modelli di completamento della chat sono sincroni. Una volta fatta una domanda, devi aspettare una singola risposta. Non puoi inviare più richieste in parallelo e poi combinare i risultati senza una precisa orchestrazione.
Presentazione dell’API degli Assistenti
L’API degli Assistenti OpenAI affronta le sfide sopra menzionate consentendoti di costruire assistenti AI con capacità aggiuntive. Fornisce:
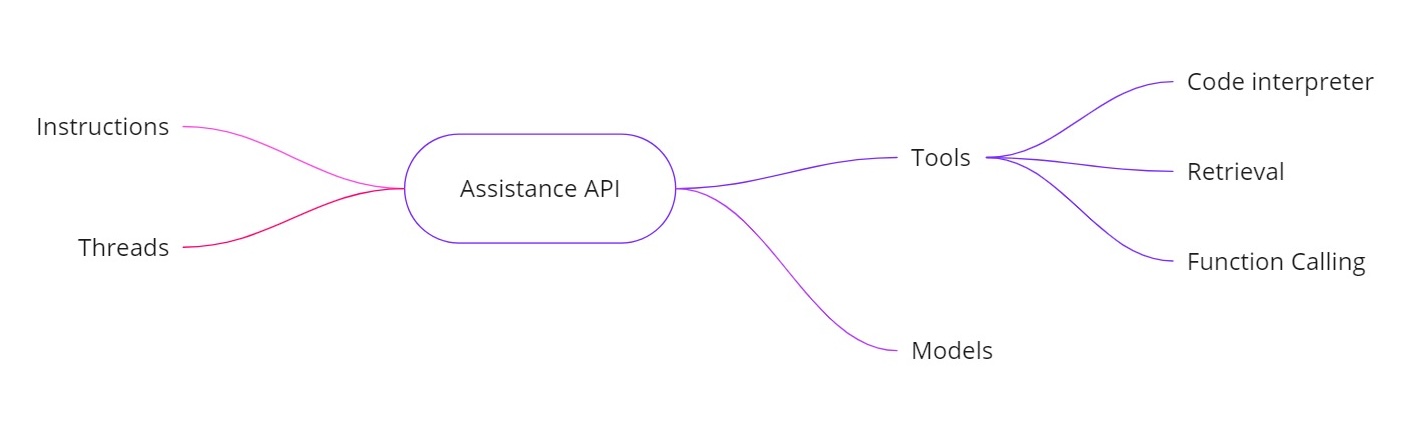
- Istruzioni. Simili a un messaggio di sistema, queste definiscono cosa il tuo assistente deve fare.
- Thread. Tutti i messaggi precedenti sono memorizzati nei thread, in modo che l’assistente possa mantenere il contesto su più turni.
- Strumenti. Questi includono funzionalità come un interprete di codice, il recupero di documenti e la chiamata di funzioni.
- Modelli. Attualmente supporta GPT-4 (anteprima 1106) e supporterà modelli personalizzati ottimizzati in futuro.
Strumenti nell’API degli Assistenti
- Interprete di codice. Quando viene richiesta un’attività computazionale, come invertire una stringa o trovare la data odierna, l’assistente può utilizzare uno strumento interprete di codice per eseguire codice Python. L’assistente restituisce quindi il risultato corretto, anziché affidarsi esclusivamente alle previsioni dei token.
- Recupero. Con il recupero, puoi caricare fino a 20 file (ciascuno fino a 52 MB e fino a 2 milioni di token per file). Quando fai una query, l’assistente può fare riferimento direttamente a quei file, semplificando notevolmente la gestione di documenti di grandi dimensioni.
- Chiamata di funzioni. Puoi definire una funzione che interroga il tuo database interno (per compiti come il controllo delle cifre di vendita). L’assistente chiederà di chiamare quella funzione con gli argomenti richiesti, e quindi tu restituisci i risultati all’assistente. In questo modo, il modello può utilizzare dati aggiornati che non avrebbe altrimenti.
- Gestione di finestre di contesto più ampie. I thread nell’API degli Assistenti selezionano dinamicamente quali messaggi includere come contesto, aiutandolo a gestire quantità maggiori di conversazione. Ciò significa che non sei più strettamente legato a una piccola finestra di contesto.
Esempio di Implementazione
Di seguito è riportato un esempio di snippet Python che mostra come creare un assistente, impostare istruzioni, abilitare strumenti e quindi eseguire query utilizzando i thread. Questo codice illustra il flusso di lavoro asincrono e l’uso di funzionalità come l’interpretazione del codice.
Creazione dell’Assistente
# Step 1: Create the Assistant
from openai import OpenAI
client = OpenAI()
my_assistant = client.beta.assistants.create(
instructions="You are a personal math tutor. When asked a question, write and run Python code to answer the question.",
name="Math Tutor",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview",
)
print(my_assistant)
Creazione di un Thread
# Step 2: Create a Thread
thread = client.beta.threads.create()
print(f"Thread ID: {thread.id}")
'''
Response
{
"id": "thread_abc123",
"object": "thread",
"created_at": 1699012949,
"metadata": {},
"tool_resources": {}
}
'''
print(json.dumps(run.model_dump(), indent =4))
Posta una Domanda
# Step 3: Ask a Question
question_1 = "Reverse the string 'openaichatgpt'."
message_1 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_1
)
Esecuzione della Query in Modo Asincrono
# Run the Query Asynchronously
run_1 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the run status
current_run = client.beta.threads.runs.retrieve(run_id=run_1.id)
print(f"Initial Run Status: {current_run.status}")
# Once completed, retrieve the messages
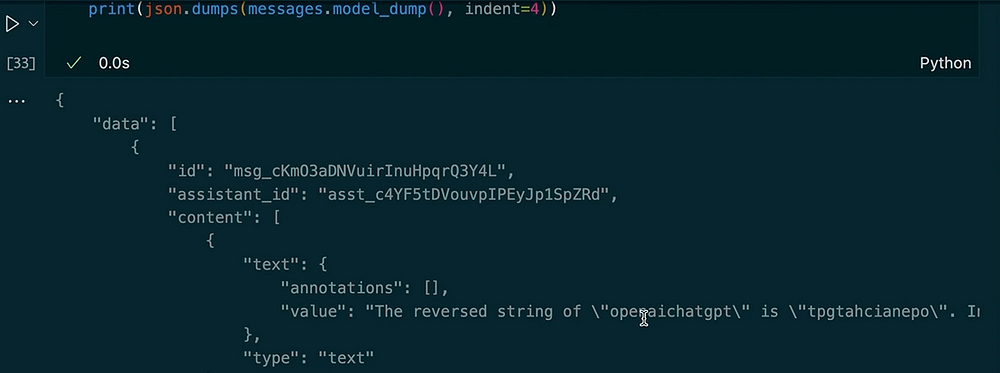
messages = client.beta.threads.messages.list(thread_id=thread.id)
print(json.dumps(messages.model_dumps(), indent=4))
Output:
Chiedere un’altra domanda nella stessa discussione
# Ask Another Question in the Same Thread
question_2 = "Make the previous input uppercase and tell me the length of the string."
message_2 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_2
)
# Run the second query
run_2 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the new run status
current_run_2 = client.beta.threads.runs.retrieve(run_id=run_2.id)
print(f"Second Run Status: {current_run_2.status}")
# Retrieve the new messages
messages_2 = client.beta.threads.messages.list(thread_id=thread.id)
for msg in messages_2:
print(msg.content)
Output:

In questo esempio, puoi vedere come la discussione mantenga il contesto. Quando chiediamo all’assistente di invertire la stringa, utilizza lo strumento interprete del codice. Successivamente, chiediamo una versione in maiuscolo dell’input precedente e otteniamo la lunghezza. L’assistente ricorda la nostra domanda precedente grazie ai messaggi archiviati nella discussione.
L’API degli Assistenti OpenAI fornisce un insieme robusto di funzionalità che vanno oltre i tipici modelli di completamento della chat. Tieni traccia della cronologia dei messaggi, supporta il recupero di documenti di grandi dimensioni, esegue codice Python per i calcoli, gestisce contesti più ampi e consente la chiamata di funzioni per integrazioni avanzate. Se hai bisogno di calcoli in tempo reale, domande e risposte basate su documenti o interazioni più dinamiche nelle tue applicazioni di intelligenza artificiale, l’API degli Assistenti offre soluzioni che affrontano le limitazioni principali dei completamenti standard della chat.
Utilizzando queste istruzioni, discussioni, strumenti (come l’interprete del codice e il recupero) e chiamata di funzioni, puoi creare assistenti AI sofisticati che gestiscono senza problemi tutto, dall’inversione delle stringhe alla consultazione di database interni. Questo nuovo approccio può trasformare il modo in cui costruiamo e utilizziamo sistemi guidati dall’IA in scenari reali.
Grazie per la lettura!
Source:
https://dzone.com/articles/chat-completion-models-vs-openai-assitance-api