













In diesem Blog werden wir einige wichtige Unterschiede zwischen Chat-Completion-Modellen (wie sie über den Endpunkt Chat Completions bereitgestellt werden) und der fortschrittlicheren OpenAI Assistants API erkunden. Wir werden untersuchen, wie diese beiden Ansätze Nachrichten, Gesprächsverlauf, große Dokumente, Codieraufgaben, Kontextfenstergrenzen und mehr behandeln. Wir werden auch betrachten, wie die Assistants API zusätzliche Tools bereitstellt – wie Code-Interpreters, Dokumentabruf und Funktionsaufrufe -, die viele Einschränkungen von Chat-Completions überwinden.
Verständnis von Chat-Completion-Modellen
- Sie senden eine Liste von Nachrichten an das Modell.
- Das Modell generiert eine Antwort.
- Sie erhalten die Antwort als Ausgabe.
Beispielablauf von Chat-Completions
Sie fragen: „Was ist die Hauptstadt von Japan?„
- Das Modell antwortet: „Die Hauptstadt von Japan ist Tokio.„
Dann fragen Sie: „Erzähl mir etwas über die Stadt.„
- Das Modell sagt, es habe keinen Kontext und weiß nicht, auf welche Stadt Sie sich beziehen, da es den Nachrichtenverlauf nicht von Natur aus im gleichen Gesprächszustand speichert.
Einschränkungen von Chat-Completion-Modellen
1. Kein dauerhafter Nachrichtenverlauf
Ein Nachteil ist das Fehlen eines Nachrichtenverlaufs. Bei Chat-Vervollständigungen erinnert sich das Modell nicht automatisch an vorherige Nachrichten. Wenn Sie beispielsweise zuerst fragen: „Was ist die Hauptstadt Japans?“ und dann einfach sagen: „Erzähl mir etwas über die Stadt“, kann das Modell oft den Namen der Stadt nicht referenzieren, es sei denn, Sie geben ihn manuell erneut an.
2. Keine direkte Dokumentenverarbeitung
Chat-Vervollständigungsmodelle unterstützen auch nicht direkt die Verarbeitung großer Dokumente. Wenn Sie beispielsweise ein 500-seitiges PDF haben und etwas wie „Wie hoch war der Gewinn meines Unternehmens im ersten Quartal 2023?“ abfragen möchten, benötigen Sie einen Prozess namens retrieval-augmented generation (RAG). Dies beinhaltet:
- Das Dokument in Text umwandeln
- Es in kleinere Abschnitte aufteilen
- Diese Abschnitte in Embeddings umwandeln
- Speichern in einer Vektordatenbank
- Die relevanten Abschnitte zur Abfragezeit abrufen und sie dann als Kontext an das Modell übergeben
3. Herausforderungen bei Codieraufgaben
Ein weiteres Problem ist die Handhabung von Rechenaufgaben. Wenn Sie Chat-Vervollständigungen bitten, etwas wie das Umkehren eines Strings zu tun, könnte das Modell eine falsche oder unvollständige Antwort generieren. Zum Beispiel:
# Example question to a Chat Completion model
reverse("Subscribetotalib")
# Hypothetical incorrect output
# "bilattoebircsubs"
Es kann auch falsche oder veraltete Informationen zum aktuellen Datum geben, da es an Echtzeit-Rechenkapazitäten fehlt.
4. Begrenztes Kontextfenster
Chat-Vervollständigungsmodelle haben ein festes maximales Token-Limit. Wenn Sie dieses Limit überschreiten, können Sie nicht alle notwendigen Informationen in einer einzigen Anfrage übermitteln. Diese Einschränkung kann den Fluss von groß angelegten Gesprächen oder kontextreichen Aufgaben stören.
5. Synchronverarbeitung
Schließlich sind Chat-Vervollständigungsmodelle synchron. Sobald Sie eine Frage stellen, müssen Sie auf eine einzelne Antwort warten. Sie können nicht mehrere Anfragen parallel einreichen und die Ergebnisse dann ohne sorgfältige Koordination kombinieren.
Einführung der Assistants API
Die OpenAI Assistants API adressiert die oben genannten Herausforderungen, indem sie Ihnen ermöglicht, KI-Assistenten mit zusätzlichen Fähigkeiten zu erstellen. Sie bietet:
- Anweisungen. Ähnlich wie eine Systemnachricht definieren diese, was Ihr Assistent tun soll.
- Threads. Alle vorherigen Nachrichten werden in Threads gespeichert, sodass der Assistent den Kontext über mehrere Runden hinweg beibehalten kann.
- Werkzeuge. Dazu gehören Funktionen wie einen Code-Interpreter, Dokumentenabruf und Funktionsaufrufe.
- Modelle. Derzeit werden GPT-4 (1106 Vorschau) unterstützt und in Zukunft wird es benutzerdefinierte feinabgestimmte Modelle unterstützen.
Werkzeuge in der Assistants API
- Code-Interpreter. Wenn eine Rechenaufgabe angefordert wird – wie das Umkehren eines Strings oder das Finden des heutigen Datums – kann der Assistent ein Code-Interpreter-Tool verwenden, um Python-Code auszuführen. Der Assistent gibt dann das richtige Ergebnis zurück, anstatt sich ausschließlich auf Token-Vorhersagen zu verlassen.
- Abruf. Mit dem Abruf können Sie bis zu 20 Dateien (jeweils bis zu 52 MB und bis zu 2 Millionen Token pro Datei) hochladen. Wenn Sie eine Abfrage stellen, kann der Assistent direkt auf diese Dateien verweisen, was die Handhabung großer Dokumente wesentlich vereinfacht.
- Funktionsaufruf. Sie können eine Funktion definieren, die Ihre interne Datenbank abfragt (für Aufgaben wie die Überprüfung von Verkaufszahlen). Der Assistent wird dann darum bitten, diese Funktion mit den erforderlichen Argumenten aufzurufen, und Sie geben dann die Ergebnisse an den Assistenten zurück. Auf diese Weise kann das Modell aktuelle Daten nutzen, über die es normalerweise nicht verfügen würde.
- Behandlung größerer Kontextfenster. Die Threads in der Assistants-API wählen dynamisch aus, welche Nachrichten als Kontext einbezogen werden sollen, was dabei hilft, größere Mengen an Konversationen zu handhaben. Das bedeutet, dass Sie nicht mehr streng an ein kleines Kontextfenster gebunden sind.
Beispielhafte Implementierung
Hier ist ein Beispiel-Python-Schnipsel, der zeigt, wie man einen Assistenten erstellt, Anweisungen festlegt, Tools aktiviert und dann Abfragen unter Verwendung von Threads ausführt. Dieser Code veranschaulicht den asynchronen Arbeitsablauf und die Verwendung von Funktionen wie der Code-Interpretation.
Erstellen des Assistenten
# Step 1: Create the Assistant
from openai import OpenAI
client = OpenAI()
my_assistant = client.beta.assistants.create(
instructions="You are a personal math tutor. When asked a question, write and run Python code to answer the question.",
name="Math Tutor",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview",
)
print(my_assistant)
Erstellen eines Threads
# Step 2: Create a Thread
thread = client.beta.threads.create()
print(f"Thread ID: {thread.id}")
'''
Response
{
"id": "thread_abc123",
"object": "thread",
"created_at": 1699012949,
"metadata": {},
"tool_resources": {}
}
'''
print(json.dumps(run.model_dump(), indent =4))
Eine Frage stellen
# Step 3: Ask a Question
question_1 = "Reverse the string 'openaichatgpt'."
message_1 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_1
)
Die Abfrage asynchron ausführen
# Run the Query Asynchronously
run_1 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the run status
current_run = client.beta.threads.runs.retrieve(run_id=run_1.id)
print(f"Initial Run Status: {current_run.status}")
# Once completed, retrieve the messages
messages = client.beta.threads.messages.list(thread_id=thread.id)
print(json.dumps(messages.model_dumps(), indent=4))
Ausgabe:
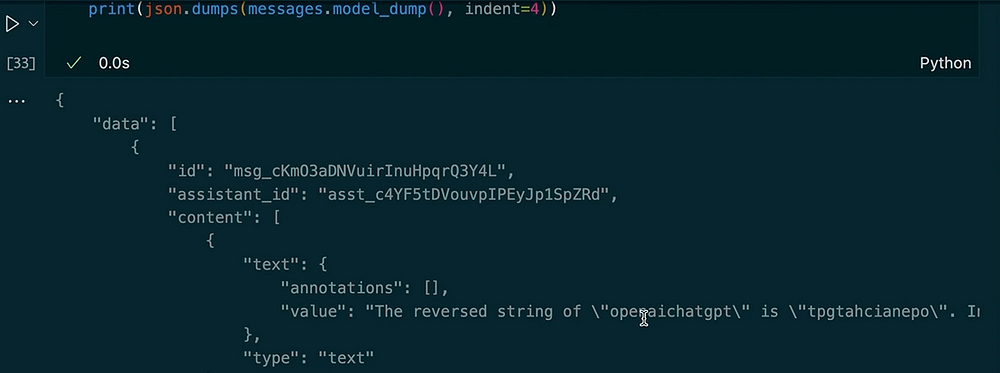
Das Stellen einer weiteren Frage im selben Thread
# Ask Another Question in the Same Thread
question_2 = "Make the previous input uppercase and tell me the length of the string."
message_2 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_2
)
# Run the second query
run_2 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the new run status
current_run_2 = client.beta.threads.runs.retrieve(run_id=run_2.id)
print(f"Second Run Status: {current_run_2.status}")
# Retrieve the new messages
messages_2 = client.beta.threads.messages.list(thread_id=thread.id)
for msg in messages_2:
print(msg.content)
Ausgabe:

In diesem Beispiel sehen Sie, wie der Thread den Kontext beibehält. Wenn wir den Assistenten bitten, den String umzukehren, verwendet er das Code-Interpreter-Tool. Als nächstes bitten wir um eine Großbuchstaben-Version der vorherigen Eingabe und erhalten die Länge. Der Assistent erinnert sich aufgrund der gespeicherten Thread-Nachrichten an unsere vorherige Frage.
Die OpenAI Assistants API bietet eine umfangreiche Palette von Funktionen, die über die typischen Chat-Vervollständigungsmodelle hinausgehen. Sie behält die Nachrichtenhistorie im Auge, unterstützt die Abfrage großer Dokumente, führt Python-Code für Berechnungen aus, verwaltet größere Kontexte und ermöglicht die Funktionsaufrufe für fortgeschrittene Integrationen. Wenn Sie Echtzeitberechnungen, dokumentenbasierte Fragen und Antworten oder dynamischere Interaktionen in Ihren KI-Anwendungen benötigen, bietet die Assistants API Lösungen, die die Kernbeschränkungen herkömmlicher Chat-Vervollständigungen ansprechen.
Unter Verwendung dieser Anweisungen, Threads, Tools (wie Code-Interpreter und Abfrage), und Funktionsaufrufe können Sie anspruchsvolle KI-Assistenten erstellen, die nahtlos alles von der Umkehrung von Zeichenfolgen bis zur Abfrage interner Datenbanken handhaben. Dieser neue Ansatz kann transformieren, wie wir KI-gesteuerte Systeme in realen Szenarien aufbauen und nutzen.
Vielen Dank fürs Lesen!
Lass uns auf LinkedIn vernetzen!
Source:
https://dzone.com/articles/chat-completion-models-vs-openai-assitance-api