













В этой короткой статье мы посмотрим на процесс одобрения кредитов с помощью различных инструментов и техник. Мы начнем с анализа данных о кредитах и применения логистической регрессии для предсказания исходов кредитных запросов. на этом базируясь, мы интегрируем BERT для природных языковых процессов, чтобы улучшить точность предсказаний. Чтобы истолковать предсказания, мы будем использовать фреймворки объяснения SHAP и LIME, предоставляя Insights о важности признаков и поведении модели. Наконец, мы исследуем потенциал природных языковых процессов через LangChain для автоматизации предсказаний кредитов с использованием природного языкового искусства.
Файл ноутбука, используемый в этой статье, доступен на GitHub.
Введение
В этой статье мы рассмотрим различные техники для одобрения кредитов, используя модели, такие как логистическая регрессия и BERT, и применяя SHAP и LIME для интерпретации моделей. Мы также исследуем потенциал использования LangChain для автоматизации предсказаний кредитов с использованием природного языкового искусства.
Создание учетной записи SingleStore Cloud
В предыдущей статье показаны шаги для создания бесплатной учетной записи SingleStore Cloud. Мы будем использовать Свободный Слой Общего использования и примут标准 names для Workspace and Database.
Импорт ноутбука
Мы скачаем ноутбук с GitHub (указан ранее).
Слева от меню на портале SingleStore Cloud выберите Разработка > Data Studio.
В правом верхнем углу страницы выберите Новая нотация > Импорт из файла.Utilizaremos el asistente para localizar y importar la nota que descargamos de GitHub.
Ejecutar la Nota
Después de verificar que estamos conectados a nuestro espacio de trabajo SingleStore, ejecutaremos las celdas una por una.
Empezaremos instalando las bibliotecas necesarias e importando las dependencias, seguido de cargar los datos de préstamos de un archivo CSV que contiene casi 600 filas. Debido a que algunas filas tienen datos faltantes, eliminaremos las incompletas para el análisis inicial, reduciendo el conjunto de datos a unas 500 filas.
A continuación, prepararemos los datos además y separaremos las características y las variables objetivo.
Las visualizaciones pueden proporcionar un gran insight en los datos y empezaremos creando un mapa de calor que muestra la correlación entre las características numéricas, como se muestra en la Figura 1.
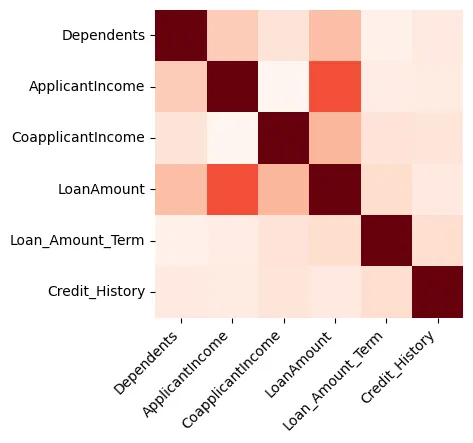
Figura 1: Mapa de calor
Podemos ver que la Cantidad del Préstamo y la Ingreso del Solicitante están fuertemente relacionadas.
Si graficamos la Cantidad del Préstamo contra Ingreso del Solicitante, podemos ver que la mayoría de los puntos están hacia la parte inferior izquierda del diagrama de dispersión, como se muestra en la Figura 2.
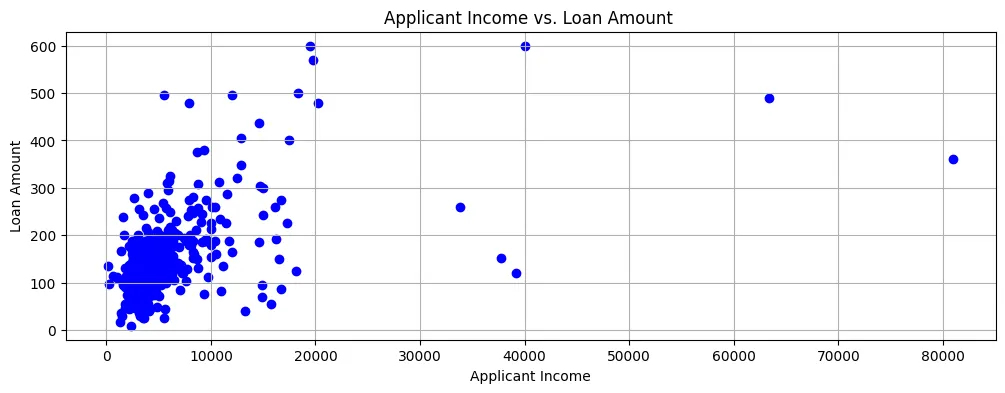
Figura 2: Diagrama de dispersión
Por lo tanto, los ingresos son generalmente bastante bajos y las solicitudes de préstamos son también para cantidades relativamente pequeñas.
Мы также можем создать гистограмму для суммы кредита, дохода заявителя и дохода соапликанта, как показано на рисунке 3.
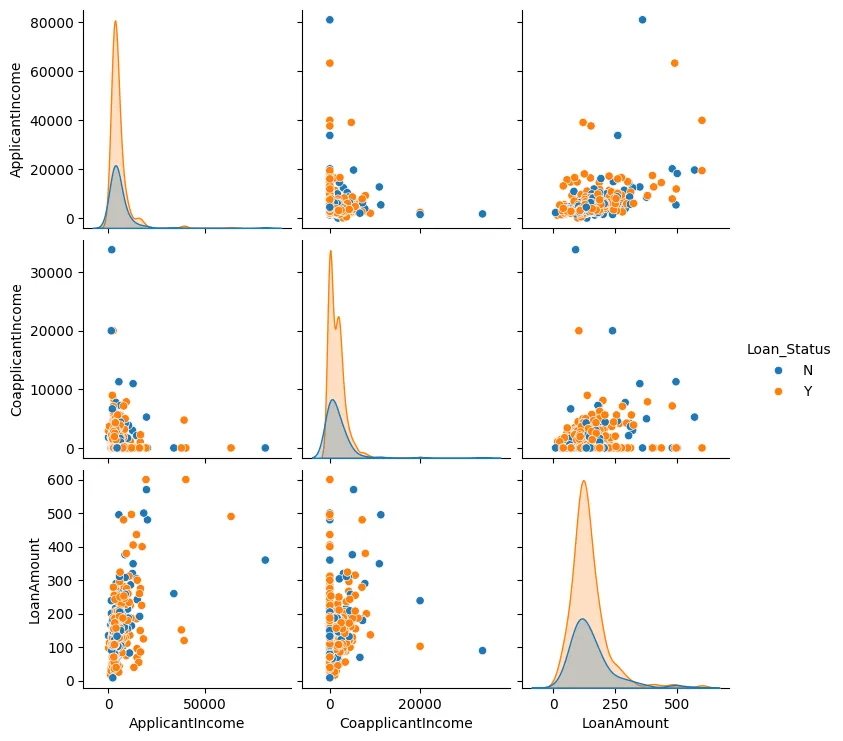
Рисунок 3: Гистограмма
В большинстве случаев мы можем observer, что точки данных тенденционно сгруппированы вместе и встречаются обычно немногочисленные исключения.
Теперь мы выполним некоторую работу по созданию признаков. Мы определим категорические значения и преобразуем их в числовые значения, а также используем one-hot encoding, где требуется.
Далее мы создадим модель с логистической регрессией, так как существуют только два возможных исхода: либо заявка на кредит одобрена, либо отклонена.
Если мы visualize важность features, мы можем сделать несколько интересных наблюдений, как показано на рисунке 4.
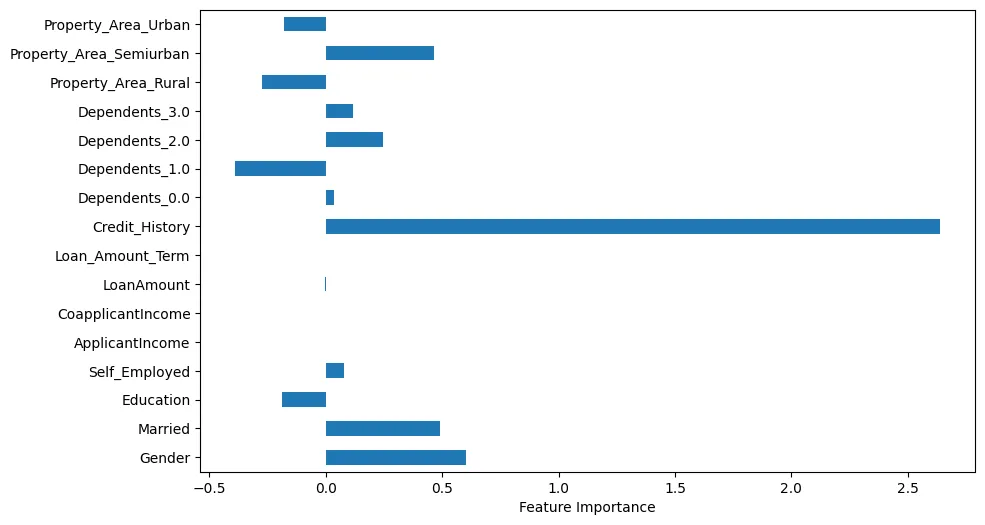
Рисунок 4: Важность Features
Например, мы можем see, что история кредита является очевидно очень важным. However, статус брака и пол также важны.
Теперь мы будем делать предсказания с использованием одного тестового образца.
Мы будем генерировать резюме заявки на кредит с использованием bidirectional Encoder Representations from Transformers (BERT) с тестовым образцом. Пример выходных данных:
BERT-Generated Loan Application Summary
applicant : mr blobby income : $ 7787. 0 credit history : 1. 0 loan amount : $ 240. 0 property area : urban area
Model Prediction ('Y' = Approved, 'N' = Denied): Y
Loan Approval Decision: Approved
Используя генерированное BERT резюме, мы создадим словарное облако, как показано на рисунке 5.

Мы можем see, что имя заявителя, доход и история кредита являются большими и выделенными.
Другим способом анализа данных для нашего тестового образца является использование SHapley Additive exPlanations (SHAP). На рисунке 6 мы можем визуально увидеть важные featuress.

Рисунок 6: SHAP
Другим способом анализа данных может быть SHAP-Force-Plot, показанный на рисунке 7.
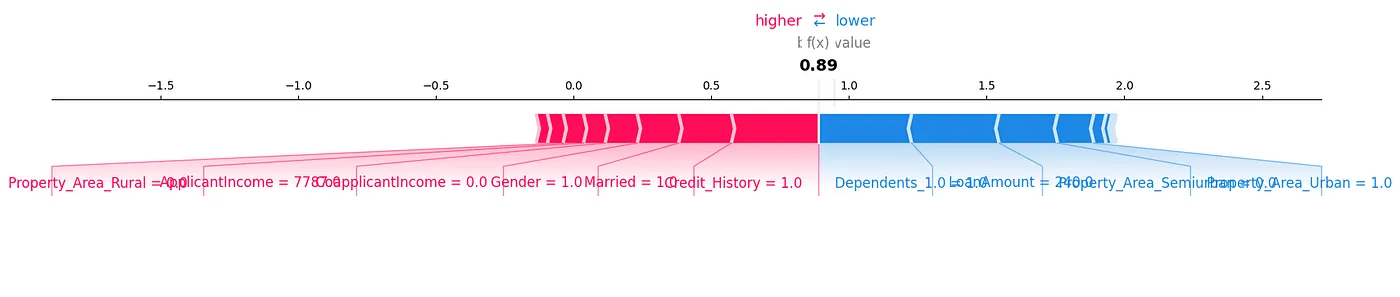
Рисунок 7: Force Plot
Мы можем увидеть, как каждая feature вносит вклад в особую предсказание для нашего тестового образца, показав значения SHAP в визуальном порядке.
Другая очень полезная библиотека – Local Interpretable Model-Agnostic Explanations (LIME). Результаты для нее могут быть сгенерированы в сопутствующей ноутбук статьи.
Далее мы создадим Конфузионную Матрицу (Рисунок 8) для модели Logistic Regression и генерируем отчет по классификации.
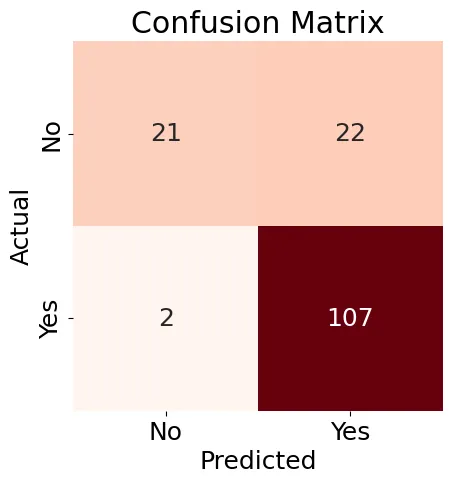
Рисунок 8: Конфузионная Матрица
Результаты, показанные на рисунке 8, несколько смешанные, но отчет по классификации содержит некоторые хорошие результаты:
Accuracy: 0.84
Precision: 0.83
Recall: 0.98
F1-score: 0.90
Classification Report:
precision recall f1-score support
N 0.91 0.49 0.64 43
Y 0.83 0.98 0.90 109
accuracy 0.84 152
macro avg 0.87 0.74 0.77 152
weighted avg 0.85 0.84 0.82 152
В целом, мы можем увидеть, что использование существующих инструментов и техник Machine Learning gives us many possible ways to analyze the data and find interesting relationships, particularly down to the level of an individual test sample.
Далее посмотрим, можем ли мы с помощью LangChain и LLM сделать предсказания по кредитам.
После установки и настройки LangChain мы протестируем его с двумя примерами, но ограничим доступ к объему данных, чтобы не превысить лимиты токенов и скорости. Вот первый пример:
query1 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Male
ApplicantIncome: 7787.0
Credit_History: 1
LoanAmount: 240.0
Property_Area_Urban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result1 = run_agent_query(query1, agent_executor, error_string)
print(result1)
В этом случае заявка была одобрена в исходных данных.
Вторичный пример:
query2 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Female
ApplicantIncome: 5000.0
Credit_History: 0
LoanAmount: 103.0
Property_Area_Semiurban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result2 = run_agent_query(query2, agent_executor, error_string)
print(result2)
В данном случае заявка была отклонена в исходных данных.
Различные запросы могут привести к непоследовательным результатам. Это может быть связано с ограничением количества данных, которое может быть использовано. Также можно использовать режим подробности в LangChain, чтобы увидеть шаги, участвующие в создании модели одобрения кредита, но на этой раннем уровне недостаточно информации о детальных шагах, которые были произведены для создания этой модели.
Социальные системы с гибкой настройкой поведения потребуют дополнительных усилий, так как во многих странах действуют законы о справедливом кредитовании, и нам потребуется подробное объяснение причин, по которым AI одобрил или отклонил определенную заявку на кредит.
Резюме
Сегодня многие мощные инструменты и техники улучшают машинное обучение (МО) для более глубокого взгляда на данные и модели предсказания кредитов. AI, через крупные языковые модели (ЛЛМ) и современные структуры, предлагает большой потенциал для улучшения или даже замены традиционных методов машинного обучения. Однако для обеспечения большего доверия к рекомендациям AI и соблюдения законодательства о справедливом кредитовании в многих странах важно понимать логику рассуждений и процесс принятия решений AI.
Source:
https://dzone.com/articles/building-predictive-analytics-for-loan-approvals