













在這一短篇文章中,我們將探索使用各種工具和技術來批核貸款。我們將從分析貸款數據開始,並應用逻辑回歸來預測貸款結果。建立在此基礎上,我們將結合BERT進行自然語言處理以提高預測準確度。為了解讀預測結果,我們將使用SHAP和LIME解釋框架,提供特徵重要性與模型行為的洞見。最後,我們將探索自然語言處理的潛力,通過LangChain來自動化貸款預測,利用對話AI的力量。
本篇文章中所使用的笔记本文件可在GitHub上找到。
引言
在本文中,我們將探索各種貸款批核技術,使用如邏輯回归和BERT等模型,並應用SHAP和LIME進行模型解釋。我們還將調查使用LangChain自動化貸款預測的潛力。
創建SingleStore雲賬戶
在先前的文章中,已經展示了創建一個免費SingleStore雲賬戶的步驟。我們將使用免費共享層,並取 Workshop和數據庫的默認名稱。
導入笔记本
我們將從GitHub上下載笔记本(之前已提供鏈接)。
從 SingleStore Cloud 控制台左側導航窗格中,我們將選擇 開發 > 數據工作室。
在網頁的右上角,我們將選擇 新建筆記本 > 從文件導入。我們將使用向導來定位並導入從 GitHub 下載的筆記本。
運行筆記本
在確定我們已連接到 SingleStore 工作區後,我們將逐一運行每個单元格。
我們將從安装必要的庫和導入依賴開始,然後從一個包含近 600 行數據的 CSV 文件中上加載贷款數據。由於一些行含有缺失數據,我們將移除不完整的行以進行初步分析,將數據集減少至約 500 行。
接下來,我們將進一步準備數據並將特徵和目標變量分開。
視覺化可以提供對數據的深刻見解,我們將從創建一個熱圖開始,該熱圖顯示數字特徵之間的相關性,如圖 1 所示。
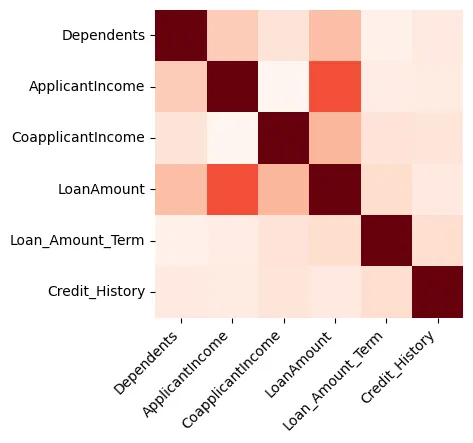
圖 1:熱圖
我們可以看到 贷款額度 和 申請人收入 之間有強烈的相關性。
如果我們將 贷款額度 對 申請人收入 進行繪圖,我們可以看到大多数數據點都在散點圖的左下角,如圖 2 所示。
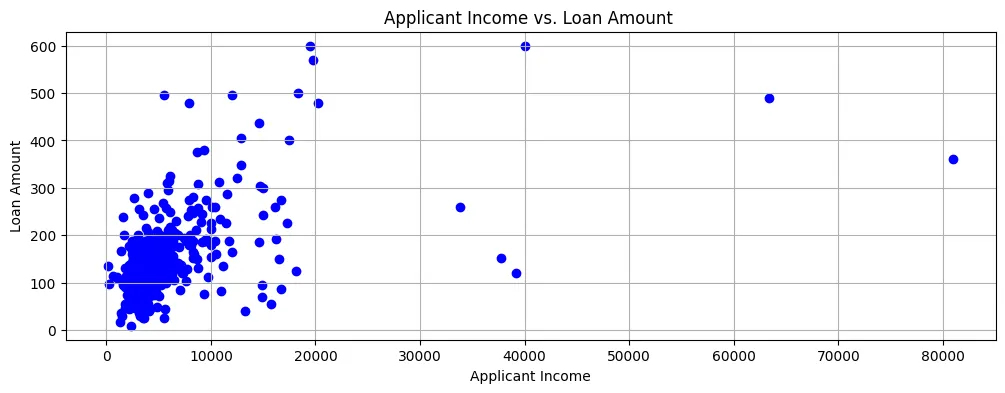
圖 2:散點圖
因此,收入普遍較低,而且貸款申請也通常是較小的額度。
我們也可以為貸款金額、申請人收入以及共同申請人收入創建對撞圖,如圖3所示。
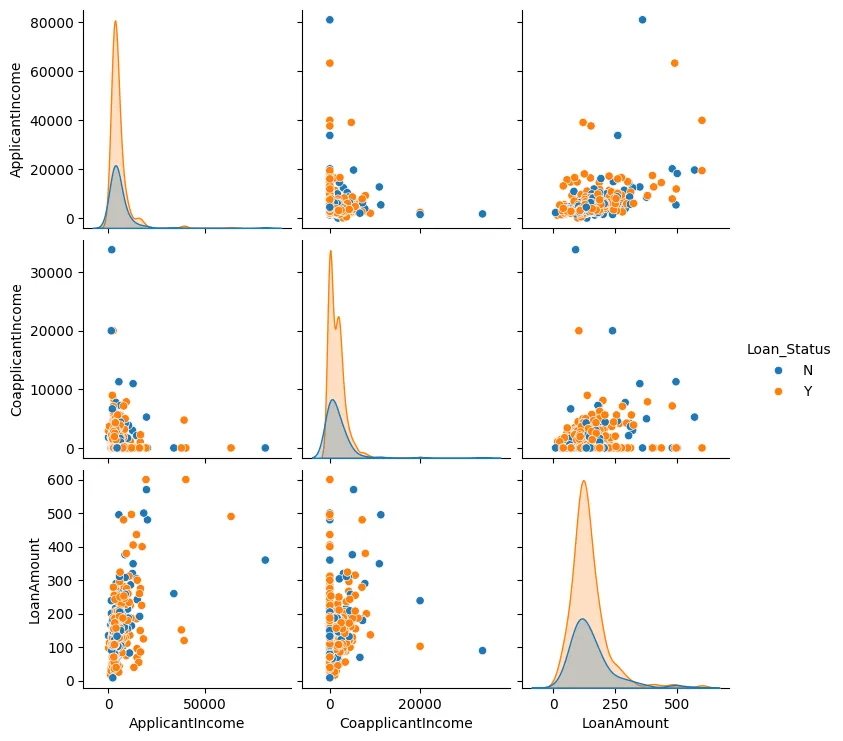
圖3:對撞圖
在大部分情況下,我們可以看到數據點傾向於聚集在一起,並且通常很少有異常值。
我們现将進行一些特徵工程。我們將識別出類別值,並將這些值轉換為數值,并在需要時使用一文不值編碼。
接下來,我們將使用邏輯回歸創建模型,因為只有兩個可能的結果:要么貸款申請被批准,要么被拒絕。
如果我们可视化特徵重要性,我們可以做一些有趣的觀察,如圖4所示。
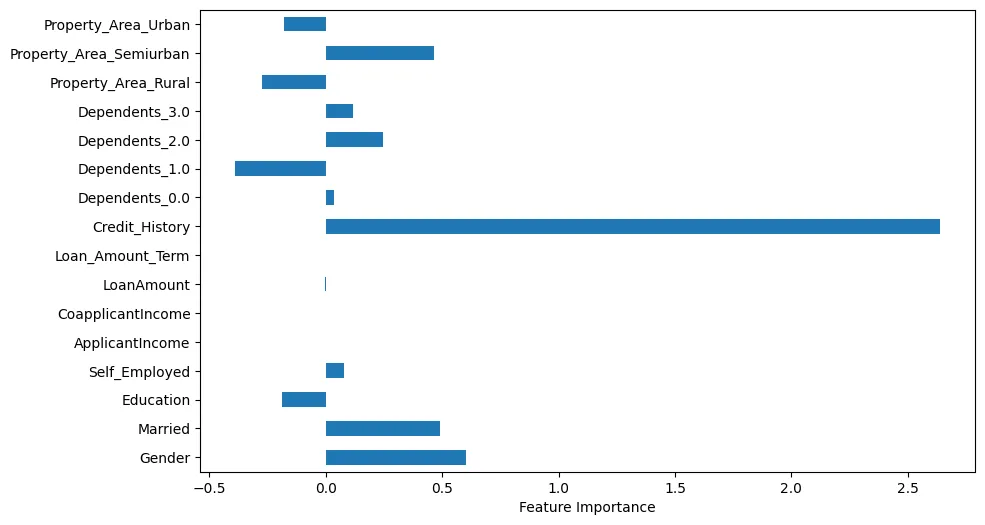
圖4:特徵重要性
例如,我們可以看到征信記錄显然非常重要。然而,婚姻狀況和性別也是重要的。
現在我們將使用一個測試樣本進行預測。
我們將使用双向编码器表示转换器(BERT)與測試樣本生成的貸款申請概要。示例输出:
BERT-Generated Loan Application Summary
applicant : mr blobby income : $ 7787. 0 credit history : 1. 0 loan amount : $ 240. 0 property area : urban area
Model Prediction ('Y' = Approved, 'N' = Denied): Y
Loan Approval Decision: Approved
使用BERT生成的概要,我們將創建一個詞雲,如圖5所示。

我們可以看到申請人的姓名、收入和征信記錄更大且更突出。
我們还可以通過使用SHapley Additive exPlanations(SHAP)來分析我們測試樣本的數據。在圖6中,我們可以直觀地看到重要的特徵。

圖6:SHAP
SHAP力矩圖是我們分析數據的另一種方式,如图7所示。
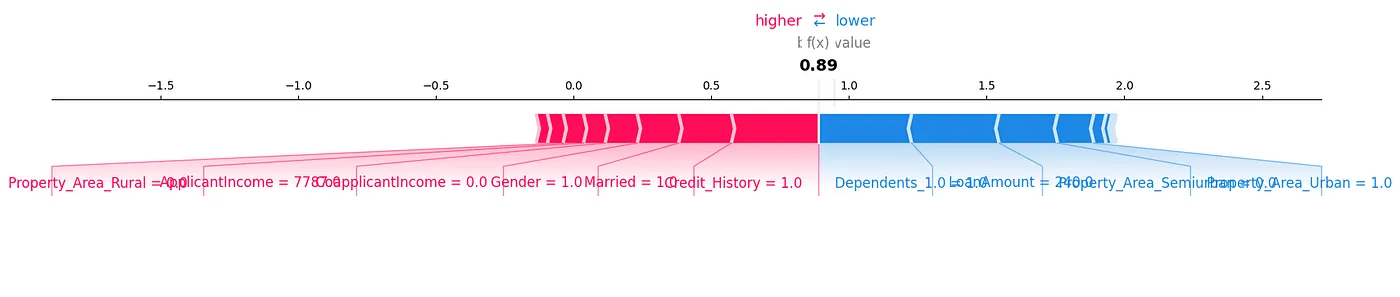
圖7:力矩圖
我們可以通過顯示SHAP值以視覺方式來查看每個特徵對我們測試樣本特定預測的貢獻。
另一個非常實用的庫是Local Interpretable Model-Agnostic Explanations(LIME)。這篇文章附带的笔记本可以生成這方面的結果。
接下來,我們将为我們的邏輯回歸模型創建一個混淆矩陣(圖8)並生成一個分類報告。
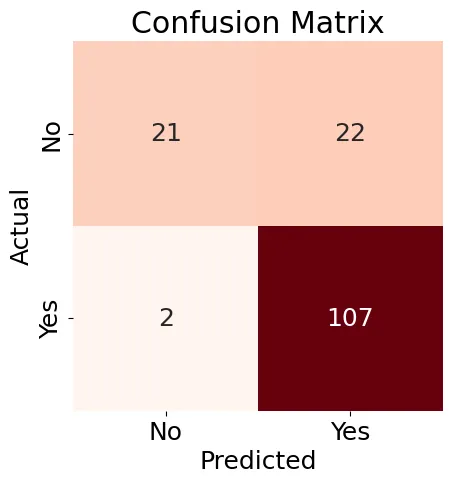
圖8:混淆矩陣
圖8所示的結果有些混亂,但分類報告 contain some good results:
Accuracy: 0.84
Precision: 0.83
Recall: 0.98
F1-score: 0.90
Classification Report:
precision recall f1-score support
N 0.91 0.49 0.64 43
Y 0.83 0.98 0.90 109
accuracy 0.84 152
macro avg 0.87 0.74 0.77 152
weighted avg 0.85 0.84 0.82 152
總的來說,我們可以看到使用现有的機器學習工具和技術给我们提供了很多可能的方式来分析数据并找到有趣的关係,特别是到一个测试样品的级别。
接下來,讓我們使用LangChain和一個LLM,看看我們是否能也应该做出贷款预测。
一旦我們設置和配置了LangChain,我們將用兩個例子來测试它,但限制数据的数量,以便我们不超过令牌和费率限制。以下是第一个例子:
query1 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Male
ApplicantIncome: 7787.0
Credit_History: 1
LoanAmount: 240.0
Property_Area_Urban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result1 = run_agent_query(query1, agent_executor, error_string)
print(result1)
在這個案例中,申請在原始數據集中的时候被批准了。
這裡是第二個例子:
query2 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Female
ApplicantIncome: 5000.0
Credit_History: 0
LoanAmount: 103.0
Property_Area_Semiurban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result2 = run_agent_query(query2, agent_executor, error_string)
print(result2)
在這個情況下,原本的數據集中的申請被拒絕了。
執行這些查詢時,我們可能會得到不一致的結果。這可能是由於限制了可用數據的數量。我們也可以在LangChain中使用詳細模式來查看建立貸款批准模型的步驟,但在此初始層面上關於建立該模型的詳細步驟 information is insufficient.
與 conversational AI 合作需要更多的工作,因為許多國家都有公平貸款規則,我們需要關於 AI 为何批准或拒絕特定貸款申請的詳細解釋。
總結
今天,許多強大的工具和技術增強了機器學習(ML)以深入挖掘數據和貸款預測模型。AI,通過大語言模型(LLMs)和現代框架,為增強或甚至取代傳統 ML 方法的潛在價值提供了很大可能性。然而,對於對 AI 的建議更有信心,並符合許多國家法律和公平貸款要求,了解 AI 的推理和決策過程至關重要。
Source:
https://dzone.com/articles/building-predictive-analytics-for-loan-approvals