













في هذه المقالة القصيرة سنستكشف تأكيدات القروض باستخدام مجموعة متنوعة من الأدوات والتقنيات. سنبدأ بتحليل البيانات الخاصة بالقروض ونطبق التعامل اللوگيستيكي لتنبؤ بنتائج القروض. ومن ثم سندمج بيرت للتعامل الطبيعي لللغة لتحسين دقة التنبؤ. لتفسير التنبؤات، سنستخدم إطاريات شبكية ولايمي (SHAP) ولايمي التوضيح (LIME) لنوفر من خلالها فينا منظورات عن أهمية المادة وسلوك النموذج. وأخيرًا سنستكشف قدرات التعامل الطبيعي اللغوي عبر لانجتشين (LangChain) لتAutomate التنبؤات الخاصة بالقروض بواسطة الذكاء المتحدث.
الملف الذي تم استخدامه في هذه المقالة متاح على GitHub.
المقدمة
في هذه المقالة سنستكشف تقنيات مختلفة لتأكيد القروض ، وسنستخدم نماذج مثل التعامل اللوگيستيكي وبيرت وسنطبق شبكيات ولايمي (SHAP) ولايمي التوضيح (LIME) لتفسير النتائج. سنبحث أيضًا عن قدرات استخدام لانجتشين (LangChain) لتAutomate التنبؤات الخاصة بالقروض بواسطة الذكاء المتحدث.
إنشاء حساب سينت ستور سكل
تم إظهار خطوات إنشاء حساب سينت ستور سكل مجاني في مقالة سابقة. سنستخدم القطاع مشترك مجانيوسنأخذ أسماء المحللة والقاعة التي تلك الأسماء الافتراضية.
قم بتحميل الملف المشاهدي
سنقوم بتحميل الملف المشاهدي من GitHub (تم ربط
من لوحة التنقل اليسرى في بوابة SingleStore Cloud، سنختار DEVELOP > استوديو البيانات.
في أعلى الصفحة الويب، سنختار دفتر جديد > استيراد من ملف. سنستخدم المعالج لتحديد موقع واستيراد الدفتر الذي قمنا بتنزيله من GitHub.
تشغيل الدفتر
بعد التحقق من أننا متصلون بمساحة العمل الخاصة بنا في SingleStore، سنقوم بتشغيل الخلايا واحدة تلو الأخرى.
سنبدأ بتثبيت المكتبات اللازمة واستيراد التبعيات، ثم تحميل بيانات القروض من ملف CSV يحتوي على ما يقرب من 600 صف. نظرًا لوجود بيانات ناقصة في بعض الصفوف، سنقوم بإسقاط تلك البيانات غير المكتملة للتحليل الأولي، مما يقلل من مجموعة البيانات إلى حوالي 500 صف.
بعد ذلك، سنقوم بإعداد البيانات بشكل أكبر وفصل المتغيرات المميزة والمتغيرات الهدف.
يمكن أن توفر التصورات رؤى رائعة حول البيانات، وسنبدأ بإنشاء خريطة حرارية تعرض الارتباط بين الميزات الرقمية فقط، كما هو موضح في الشكل 1.
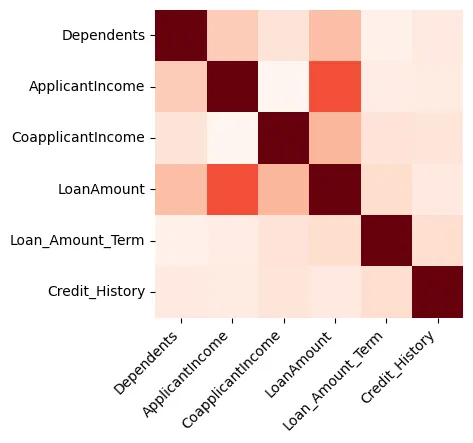
الشكل 1: الخريطة الحرارية
يمكننا أن نرى أن مبلغ القرض و دخل المقدم طلب القرض ذات صلة قوية.
إذا رسمنا مبلغ القرض مقابل دخل المقدم طلب القرض، يمكننا أن نرى أن معظم نقاط البيانات تقع في أسفل الجهة اليسرى السفلية من الرسم البياني المبعثر، كما هو موضح في الشكل 2.
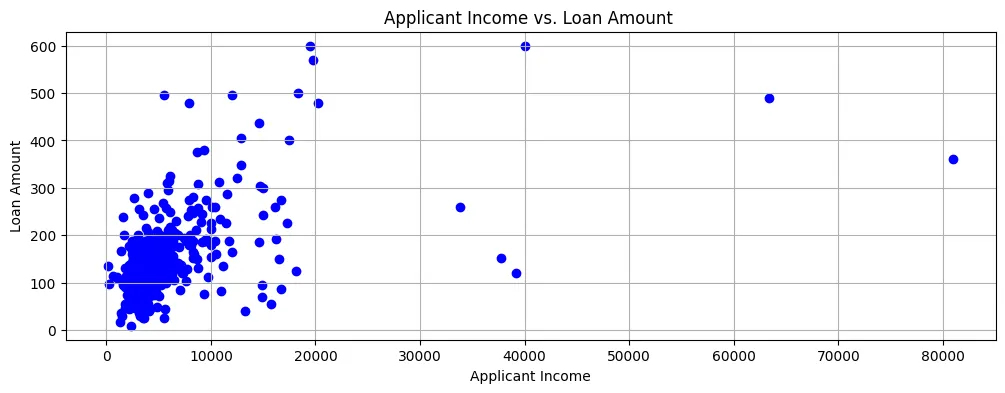
الشكل 2: الرسم البياني المبعثر
لذا، فإن الدخول عمومًا منخفض جدًا وتطبيقات القروض أيضًا لمبالغ صغيرة نسبيا.
يمكننا أيضًا إنشاء رسم بياني متعدد الأبعاد لـ مبلغ القرض، دخل المقدم، و دخل المتقدم المشترك، كما هو موضح في الشكل 3.
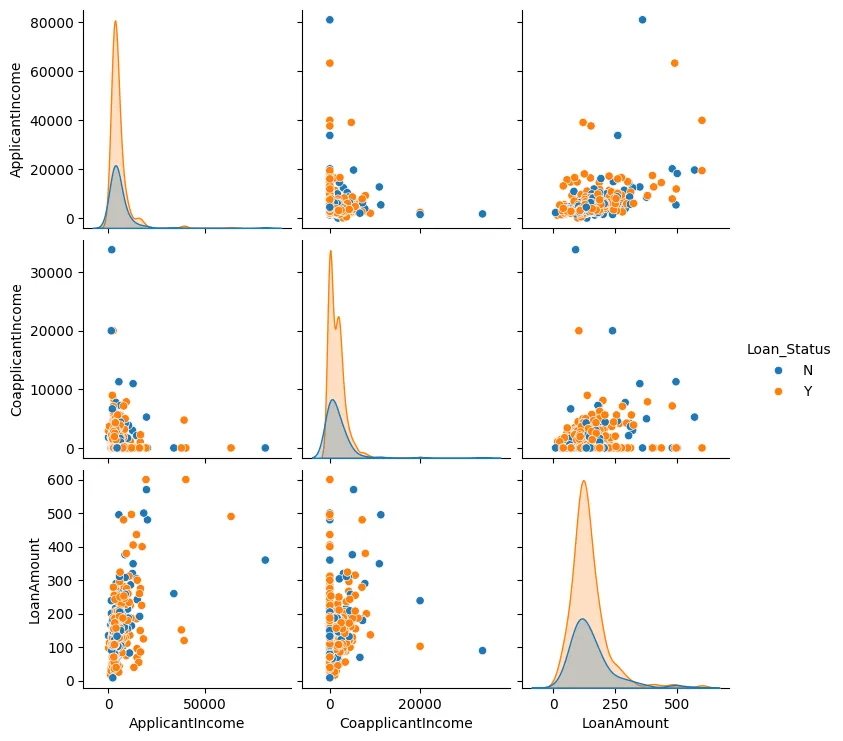
الشكل 3: رسم بياني متعدد الأبعاد
في معظم الحالات، يمكننا أن نرى أن نقاط البيانات تميل إلى التجمع معًا وعادة ما تكون هناك نقاط بيانات متطرفة قليلة.
سنقوم الآن بإجراء بعض الهندسة الميزات. سنحدد القيم القطعية ونحولها إلى قيم رقمية ونستخدم الترميز الثنائي الساخن حيثما يلزم.
بعد ذلك، سنقوم بإنشاء نموذج باستخدام التحويل اللوجستي حيث أن هناك نتيجتان محتملتان فقط: إما الموافقة على طلب القرض أو رفضه.
إذا قمنا بتصور أهمية الميزات، يمكننا أن نجد بعض الملاحظات المثيرة للاهتمام، كما هو موضح في الشكل 4.
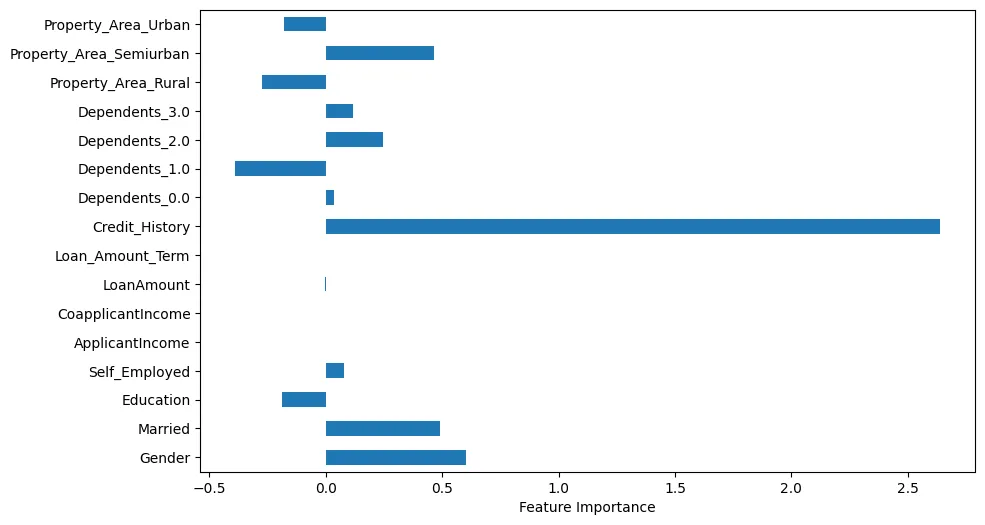
الشكل 4: أهمية الميزات
على سبيل المثال، يمكننا أن نرى أن سجل الائتمان مهم بوضوح. ومع ذلك، الحالة الزوجية و الجنس مهمة أيضًا.
سنقوم الآن بعمل توقعات باستخدام عينة اختبار واحدة.
سننشئ ملخصًا لطلب القرض باستخدام تمثيلات التشفير الثنائي الثنائي ثنائي الاتجاه من المحولات (BERT) باستخدام العينة الاختبارية. مثال للإخراج:
BERT-Generated Loan Application Summary
applicant : mr blobby income : $ 7787. 0 credit history : 1. 0 loan amount : $ 240. 0 property area : urban area
Model Prediction ('Y' = Approved, 'N' = Denied): Y
Loan Approval Decision: Approved
باستخدام الملخص الذي تم إنشاؤه بواسطة BERT، سنقوم بإنشاء سحابة كلمات كما هو موضح في الشكل 5.

يمكننا أن نرى أن اسم المقدم، والدخل، وسجل الائتمان أكبر وأكثر بروزًا.
طريقة أخرى يمكننا من خلالها تحليل البيانات لعينة الاختبار لدينا هي باستخدام تفسيرات شابلي الإضافية (SHAP). في الشكل 6 يمكننا أن نرى بصريًا الميزات التي تعتبر مهمة.

الشكل 6: SHAP
مخطط القوة لـ SHAP هو طريقة أخرى يمكننا تحليل البيانات بها، كما هو موضح في الشكل 7.
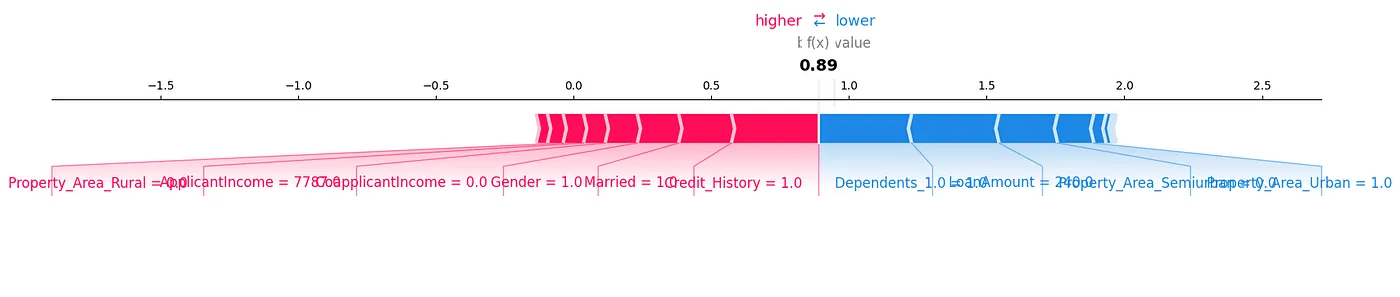
الشكل 7: مخطط القوة
يمكننا أن نرى كيف تساهم كل ميزة في تنبؤ معين لعينة الاختبار لدينا من خلال عرض قيم SHAP بطريقة مرئية.
مكتبة أخرى مفيدة للغاية هي تفسيرات النموذج الموضعية غير المرتبطة (LIME). يمكن توليد النتائج لهذا في دفتر الملاحظات المرافق لهذه المقالة.
بعد ذلك، سنقوم بإنشاء مصفوفة الالتباس (الشكل 8) لنموذج الانحدار اللوجستي لدينا وإنتاج تقرير التصنيف.
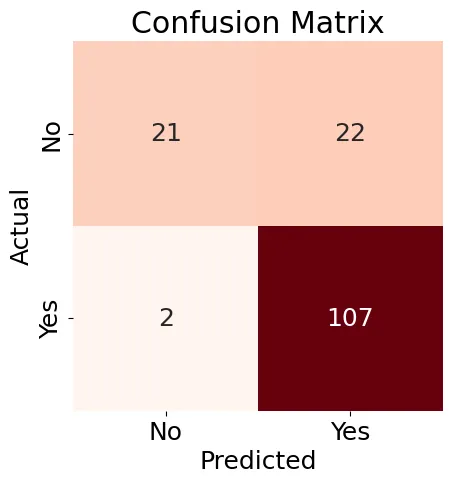
الشكل 8: مصفوفة الالتباس
النتائج المعروضة في الشكل 8 مختلطة قليلاً، لكن تقرير التصنيف يحتوي على بعض النتائج الجيدة:
Accuracy: 0.84
Precision: 0.83
Recall: 0.98
F1-score: 0.90
Classification Report:
precision recall f1-score support
N 0.91 0.49 0.64 43
Y 0.83 0.98 0.90 109
accuracy 0.84 152
macro avg 0.87 0.74 0.77 152
weighted avg 0.85 0.84 0.82 152
بشكل عام، يمكننا أن نرى أن استخدام أدوات وتقنيات التعلم الآلي الحالية يمنحنا العديد من الطرق الممكنة لتحليل البيانات واكتشاف العلاقات المثيرة، وخصوصاً على مستوى عينة الاختبار الفردية.
بعد ذلك، دعونا نستخدم LangChain و LLM ونرى ما إذا كنا نستطيع أيضًا إجراء تنبؤات القروض.
بمجرد إعداد وتكوين LangChain، سنختبره مع مثالين، لكن سنقيد الوصول إلى كمية البيانات حتى لا نتجاوز حدود الرموز وحدود المعدل. هنا هو المثال الأول:
query1 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Male
ApplicantIncome: 7787.0
Credit_History: 1
LoanAmount: 240.0
Property_Area_Urban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result1 = run_agent_query(query1, agent_executor, error_string)
print(result1)
في هذه الحالة، تم الموافقة على التطبيق في مجموعة البيانات الأصلية.
هذا مثال الثاني:
query2 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Female
ApplicantIncome: 5000.0
Credit_History: 0
LoanAmount: 103.0
Property_Area_Semiurban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result2 = run_agent_query(query2, agent_executor, error_string)
print(result2)
في هذه الحالة ، تم رفض التطبيق في الجمود الأصلية.
تنفيذ هذه الأسئلة قد يوجد نتائج غير متزامنة. قد يكون ذلك بسبب قيد الكمية المحددة للبيانات التي يمكن استخدامها. يمكننا أيضًا استخدام وضع تفصيلي في LangChain لرؤية الخطوات التي يتم استخدامها لبناء نموذج التصويت على الموافقة بالقروض، لكن هنا في المرحلة الأولي لا يوجد معلومات كافية عن الخطوات التفصيلية التي تتطلب إنشائها.
يحتاج العمل المتزايد مع التعامل الذي يتم مع الألغاز التعاملي، لأن معظم البلدان تحمل قوانين القروض العادلة ويتوجب علينا تفسير تفصيلي حول سبب توافق الإيجاز أو رفض التطبيق الخاص بالقرض.
الخلاصة
اليوم ، وتعد كل مجموعة قوية من الأدوات والتقنيات تُعزز علم الماشينة (التعلم الآلي) للبحث في البيانات ونماذج التنبؤ بالقروض بشكل أعمق. الذكاء ، من خلال نماذج اللغة الكبيرة (نماذج الكلمات الكبيرة) والأبناء الحديثة ، يقدم قدرة هامة لتحسين أو حتى تحليل أو إستبدال أساليب التعلم الآلي التقليدية. ومع ذلك ، للثقة أكبر في توصيات الإيجاز وللموافقة بالقوانين الشرعية والقروض العادلة في العديد من البلدان ، من المهم جدًا فهم سبب تفكير الذكاء وعملية قراءة القروض.
Source:
https://dzone.com/articles/building-predictive-analytics-for-loan-approvals