













In diesem kurzen Artikel werden wir verschiedene Methoden und Werkzeuge zur Kreditan Approbation untersuchen. Wir beginnen mit der Analyse von Kreditdaten und verwenden Logistische Regression, um Kreditausgaben vorherzusagen. Aufbauend auf diesem, integrieren wir BERT zur natürlichen Sprachverarbeitung, um die Prädiktionsgenauigkeit zu verbessern. Um die Prognosen zu interpretieren, verwenden wir die Erklärungsschemata SHAP und LIME, um Einblicke in die Bedeutung von Merkmalen und das Verhalten des Modells zu geben. Schließlich untersuchen wir die Möglichkeiten der natürlichen Sprachverarbeitung über LangChain, um Kreditvoraussagen automatisiert zu erledigen, und nutzen dabei die Kraft der konversationellen AI.
Der in diesem Artikel verwendete Notizbuchdatei ist auf GitHub verfügbar.
Einführung
In diesem Artikel werden wir verschiedene Techniken für Kreditan Approbation untersuchen, indem wir Modelle wie Logistische Regression und BERT verwenden und SHAP und LIME für die Modellinterpretation anwenden. Wir untersuchen auch die Möglichkeiten, LangChain für die Automatisierung von Kreditvoraussagen mit konversationeller AI zu verwenden.
Erstellen Sie ein SingleStore Cloud-Konto
Ein vorheriger Artikel zeigte die Schritte, um ein kostenfreies SingleStore Cloud-Konto zu erstellen. Wir werden den kostenlosen Geteilten Tieredienst verwenden und die Standardbezeichnungen für das Arbeitsumfeld und die Datenbank nehmen.
Importieren Sie den Notizbuch
Wir laden das Notizbuch von GitHub herunter (wie zuvor verlinkt).
Aus dem linken Navigationsbereich des SingleStore Cloud-Portals wählen wir DEVELOP > Data Studio.
Im oberen rechten Bereich der Webseite wählen wir Neue Notebook > Datei importieren. Wir verwenden den Assistenten, um auf GitHub heruntergeladene Notebooks zu finden und zu importieren.
Notebook ausführen
Nachdem wir überprüft haben, dass wir mit unserem SingleStore-Arbeitsbereich verbunden sind, führen wir die Zellen einzeln aus.
Wir beginnen mit dem Installieren der notwendigen Bibliotheken und der Importierung von Abhängigkeiten, gefolgt vom Laden der Kreditdaten aus einer CSV-Datei, die fast 600 Zeilen enthält. Da einige Zeilen keine Daten enthalten, entfernen wir die unvollständigen Einträge für die erste Analyse und reduzieren das Datensatz auf etwa 500 Zeilen.
Danach bereitet wir die Daten weiter vor und trennt die Merkmale und Zielvariablen.
Visualisierungen können großartige Einblicke in die Daten bieten, und wir beginnen mit der Erstellung einer Heatmap, die die Korrelation zwischen numerischen Merkmalen zeigt, wie in Abbildung 1 dargestellt.
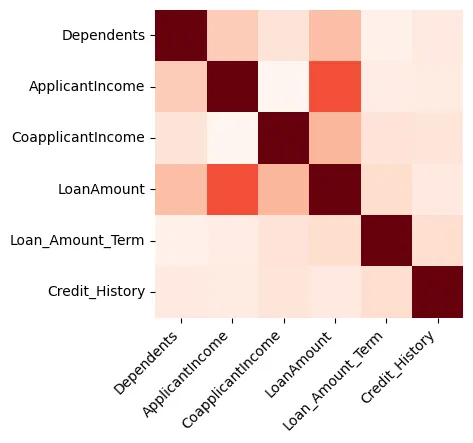
Abbildung 1: Heatmap
Wir können erkennen, dass die Kreditbetrag und die Bewerber-Einkommen stark miteinander verbunden sind.
Wenn wir den Kreditbetrag gegenüber dem Bewerber-Einkommen plotten, kann man sehen, dass die meisten Datenpunkte sich im unteren linken Bereich des Scatterplots befinden, wie in Abbildung 2 gezeigt.
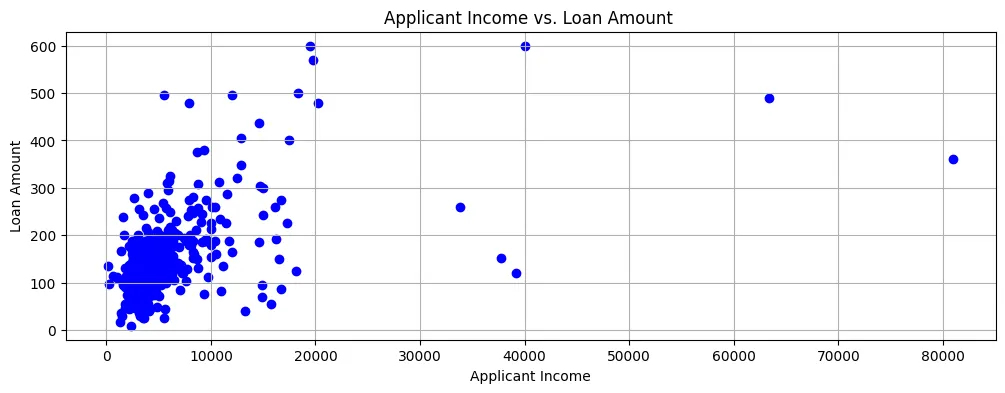
Abbildung 2: Scatter Plot
Also sind die Einkommen im Allgemeinen recht niedrig und die Kreditbewerbungen betrachten auch eher kleine Beträge.
Wir können auch einen Paar-Plot für die Kreditbetrag, die Einkommen des Antragstellers und das Mitgliedseinkommen erzeugen, wie in Abbildung 3 gezeigt.
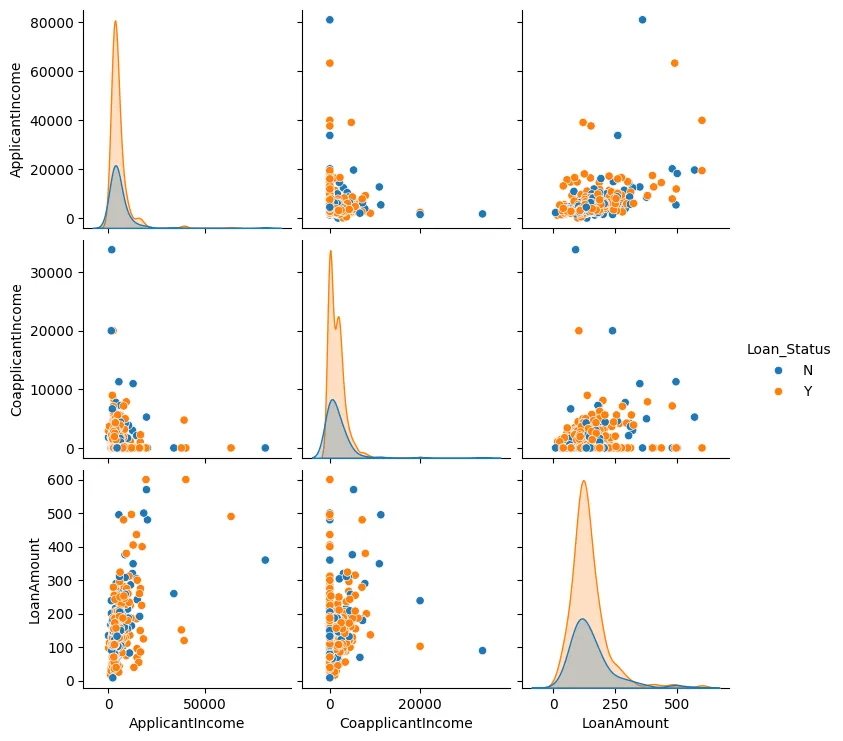
Abbildung 3: Paar-Plot
In den meisten Fällen kann man sehen, dass die Datenpunkte eher zusammenkommen und es normalerweise nur wenige Ausreißer gibt.
Wir werden nun einige Merkmalsengineering-Schritte durchführen. Wir werden die kategorischen Werte identifizieren und diese in numerische Werte umwandeln und verwenden auch One-Hot-Encoding dort, wo es erforderlich ist.
Als nächstes werden wir ein Modell mit Logistischer Regression erstellen, da es nur zwei mögliche Ausgänge gibt: Entweder wird ein Kreditantrag genehmigt oder abgelehnt.
Wenn wir die Merkmalimportanz visualisieren, können wir einige interessante Beobachtungen machen, wie in Abbildung 4 gezeigt.
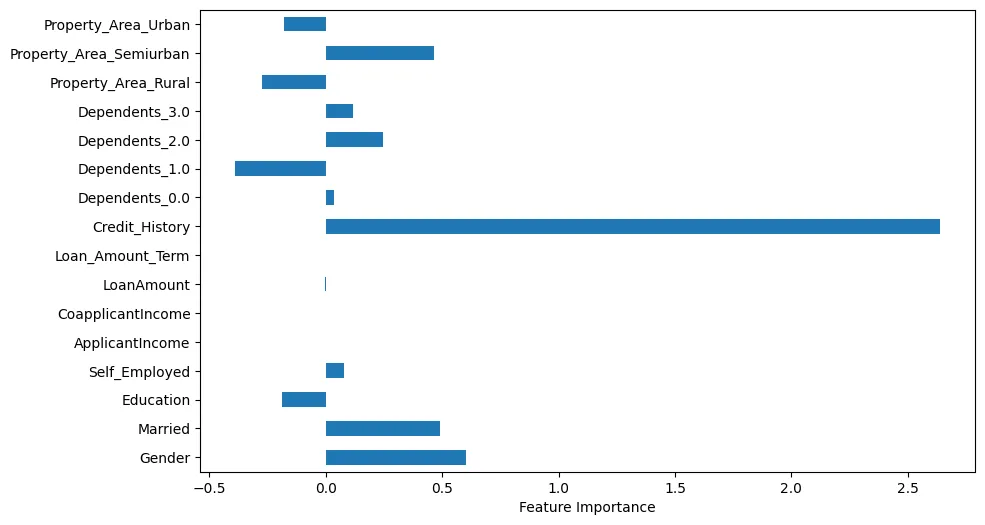
Abbildung 4: Merkmalimportanz
Zum Beispiel kann man sehen, dass die Kredithistorie offenbar sehr wichtig ist. Allerdings sind auch die Familienstand und die Geschlechtsangleichung wichtig.
Wir werden nun mit einem Testfall Voraussagen treffen.
Wir generieren einen Kreditantragszusammenfassung mit Bidirectional Encoder Representations from Transformers (BERT) mit dem Testfall. Beispielhafte Ausgabe:
BERT-Generated Loan Application Summary
applicant : mr blobby income : $ 7787. 0 credit history : 1. 0 loan amount : $ 240. 0 property area : urban area
Model Prediction ('Y' = Approved, 'N' = Denied): Y
Loan Approval Decision: Approved
Mit der durch BERT generierten Zusammenfassung erstellen wir einen Wortwolken-Diagramm wie in Abbildung 5 gezeigt.

Wir können sehen, dass der Name des Antragstellers, das Einkommen und die Kreditgeschichte größer und prominenter dargestellt sind.
Eine weitere Methode, um die Daten für unseren Testbeispiel analysiert werden kann, besteht darin, SHapley Additive exPlanations (SHAP) zu verwenden. In Abbildung 6 können wir visuell die wichtigen Merkmale erkennen.

Abbildung 6: SHAP
Ein SHAP-Kraftdiagramm ist eine weitere Methode, mit der wir die Daten analysieren könnten, wie in Abbildung 7 gezeigt.
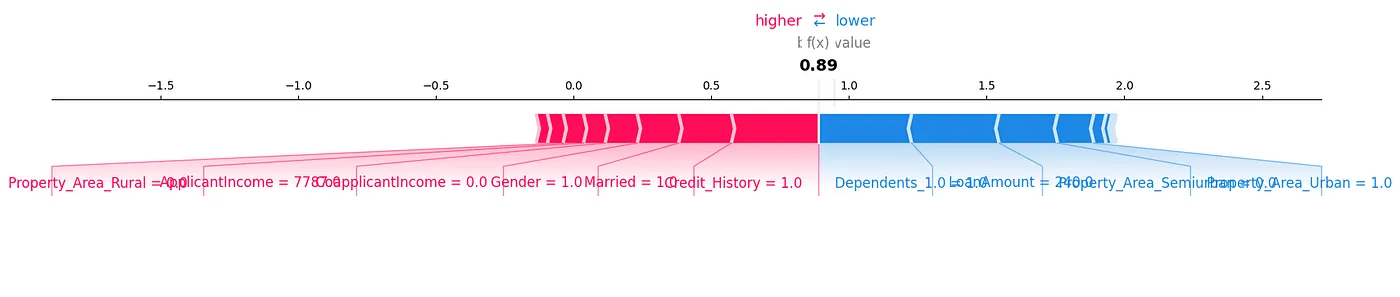
Abbildung 7: Kraftdiagramm
Wir können erkennen, wie jeder Merkmal zu einer bestimmten Voraussage für unseren Testbeispiel beiträgt, indem wir die SHAP-Werte in visueller Form anzeigen.
Eine sehr nützliche Bibliothek ist Local Interpretable Model-Agnostic Explanations (LIME). Die Ergebnisse für diese können im begleitenden Notizbuch zu diesem Artikel erzeugt werden.
Nächstes wird wir eine Verwirrungsmatrix (Abbildung 8) für unser Logistische Regressionsmodell erstellen und einen Klassifikationsbericht generieren.
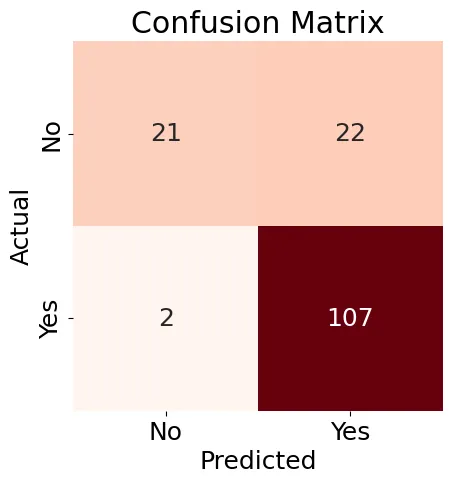
Abbildung 8: Verwirrungsmatrix
Die in Abbildung 8 gezeigten Ergebnisse sind ein wenig gemischt, aber der Klassifikationsbericht enthält einige gute Ergebnisse:
Accuracy: 0.84
Precision: 0.83
Recall: 0.98
F1-score: 0.90
Classification Report:
precision recall f1-score support
N 0.91 0.49 0.64 43
Y 0.83 0.98 0.90 109
accuracy 0.84 152
macro avg 0.87 0.74 0.77 152
weighted avg 0.85 0.84 0.82 152
Insgesamt können wir sehen, dass das Verwenden von existierenden Maschinenlern工具 und Techniken uns viele Möglichkeiten gibt, um die Daten zu analysieren und interessante Beziehungen zu finden, insbesondere auf der Ebene eines individuellen Testbeispiels.
Nächstes werden wir LangChain und eine LLM verwenden, um zu prüfen, ob wir auch Krediteinschätzungen treffen können.
Nachdem wir LangChain eingerichtet und konfiguriert haben, werden wir es mit zwei Beispielen testen, aber den Zugriff auf die Datenmenge begrenzen, sodass wir die Token- und Rate-Limits nicht überschreitern. Hier ist das erste Beispiel:
query1 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Male
ApplicantIncome: 7787.0
Credit_History: 1
LoanAmount: 240.0
Property_Area_Urban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result1 = run_agent_query(query1, agent_executor, error_string)
print(result1)
In diesem Fall wurde die Anwendung im Originaldatensatz genehmigt.
Das ist das zweite Beispiel:
query2 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Female
ApplicantIncome: 5000.0
Credit_History: 0
LoanAmount: 103.0
Property_Area_Semiurban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result2 = run_agent_query(query2, agent_executor, error_string)
print(result2)
In diesem Fall wurde die Anwendung im ursprünglichen Datensatz abgelehnt.
Wenn wir diese Abfragen ausführen, könnten wir inkonsistente Ergebnisse erhalten. Dies könnte aufgrund der Einschränkung der Menge an Daten, die verwendet werden kann, sein. Wir können auch den detaillierten Modus in LangChain verwenden, um zu sehen, welche Schritte zur Erstellung eines Kreditanpassungsmodells verwendet werden, aber es gibt an dieser initialen Ebene nicht genügend Informationen über die detaillierten Schritte, um dieses Modell zu erstellen.
Es ist mit converationalem AI noch mehr Arbeit notwendig, da viele Länder faire Kreditregeln haben und wir eine detaillierte Erklärung brauchen, warum das AI ein Kreditantrag approved oder abgelehnt.
Zusammenfassung
Heute bieten viele leistungsstarke Werkzeuge und Techniken Maschine Learning (ML) für tiefere Einblicke in Daten und Kreditvorhersagemodelle an. AI, über Große Sprachmodelle (LLMs) und moderne Frameworks, bietet großes Potenzial, um ML-Ansätze zu ergänzen oder sogar zu ersetzen. Allerdings ist es für eine größere Vertrautheit mit den Empfehlungen von AI und zur Erfüllung der rechtlichen und fairen Kreditvorschriften in vielen Ländern wichtig, die Rechnungslegung und den Entscheidungsprozess von AI zu verstehen.
Source:
https://dzone.com/articles/building-predictive-analytics-for-loan-approvals