













In questo breve articolo, esploriamo le approvazioni di prestiti utilizzando una varietà di strumenti e tecniche. Inizieremo analizzando i dati del prestito e applicando la Regressione Logistica per predire i risultati del prestito. Costruendo su questo, integraremo BERT per il Processamento del Linguaggio Naturale per migliorare l’accuratezza delle previsioni. Per interpretare le previsioni, userò i framework di spiegazione SHAP e LIME, fornendo insights sull’importanza delle caratteristiche e sul comportamento del modello. Infine, esploriamo il potenziale del Processamento del Linguaggio Naturale attraverso LangChain per automatizzare le previsioni di prestito, usando il potere dell’IA conversazionale.
Il file della scheda utilizzato in questo articolo è disponibile su GitHub.
Introduzione
In questo articolo, esploriamo varie tecniche per le approvazioni di prestiti, utilizzando modelli come la Regressione Logistica e BERT, e applicando SHAP e LIME per l’interpretazione del modello. Inoltre, investigheremo il potenziale dell’utilizzo di LangChain per automatizzare le previsioni di prestito con l’IA conversazionale.
Creare un Account SingleStore Cloud
Un articolo precedente ha mostrato i passaggi per creare un account SingleStore Cloud gratuito. Utilizzeremo la Fascia Condivisa Gratuita e prenderemo i nomi predefiniti per il Workspace e il Database.
Importare la Scheda
Scarperemo la scheda da GitHub (collegato precedentemente).
Dal pannello di navigazione sinistro del portale SingleStore Cloud, selezioniamo DEVELOP > Data Studio.
In alto a destra della pagina web, selezioniamo New Notebook > Import From File. Usiamo il wizard per trovare e importare il notebook che abbiamo scaricato da GitHub.
Esegui il Notebook
Dopo aver verificato che siamo connessi al nostro spazio di lavoro SingleStore, eseguiamo le celle una per una.
Inizieremo installando le librerie necessarie e importando le dipendenze, poi caricheremo i dati del prestito da un file CSV contenente quasi 600 righe. Poiché alcune righe hanno dati mancanti, cancelliamo quelle incomplete per l’analisi iniziale, riducendo il set di dati a circa 500 righe.
Successivamente, prepariamo ulteriormente i dati e separiamo le features e le variabili obiettivo.
Le visualizzazioni possono fornire grandi insights sui dati, e comincieremo creando una heatmap che mostra la correlazione tra le features numeriche, come mostrato in Figure 1.
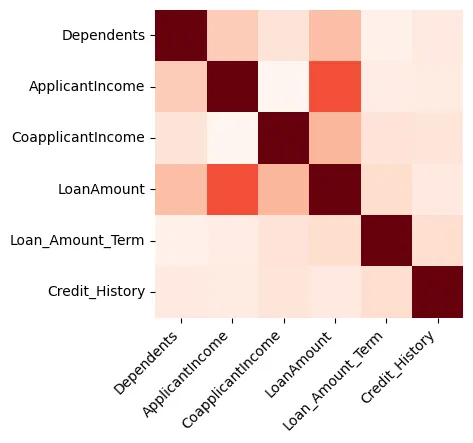
Figure 1: Heatmap
Possiamo vedere che Loan Amount e Applicant Income sono fortemente correlati.
Se mappiamo Loan Amount contro Applicant Income, vediamo che la maggior parte dei dati punti si trovano nell’angolo in basso a sinistra dello scatter plot, come mostrato in Figure 2.
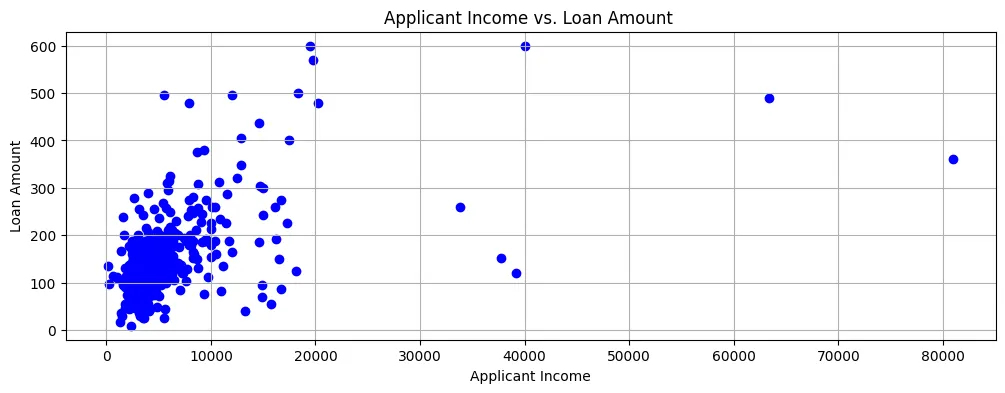
Figure 2: Scatter Plot
Quindi, le entrate sono generalmente piuttosto basse e le richieste di prestito sono anche per importi relativamente piccoli.
Possiamo anche creare un grafico di coppie per l’importo del prestito, l’entrata dell’applicante e l’entrata del co-applicante, come mostrato in Figura 3.
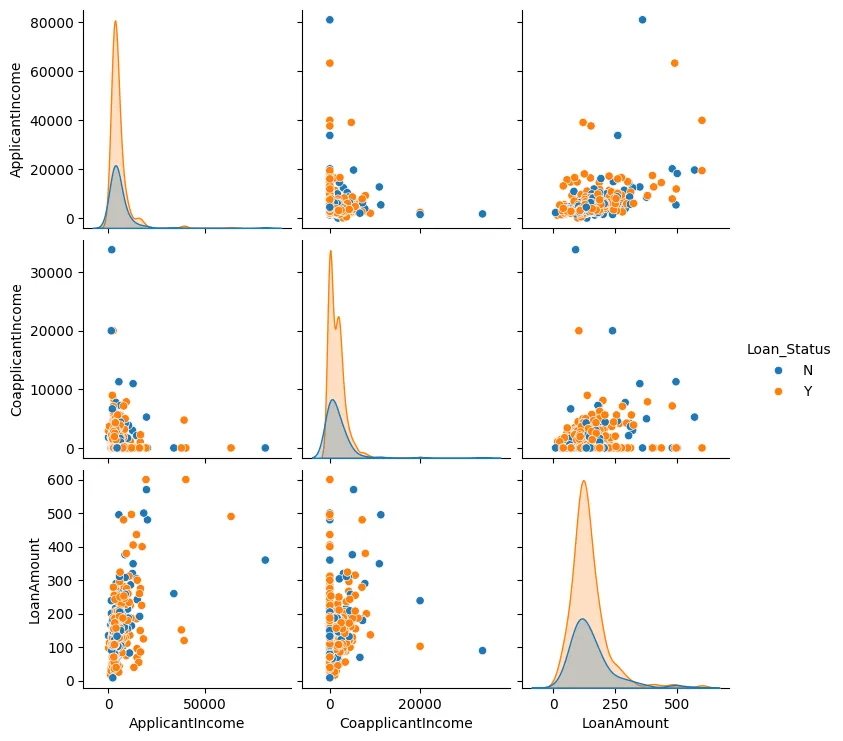
Figura 3: Grafico di coppie
In gran parte dei casi, vediamo che i punti dati tendono a clustering insieme e ci sono generalmente pochi outlier.
Ora eseguiremo una qualche engineering del feature. Identifichiamo i valori categorici e convertiamo questi in valori numerici, utilizzando anche l’encoding one-hot dove necessario.
Successivamente, crearemo un modello utilizzando l’Regressione Logistica poiché ci sono solo due risultati possibili: il prestito viene approvato o respinto.
Se visualizziamo l’importanza dei feature, possiamo fare alcune osservazioni interessanti, come mostrato in Figura 4.
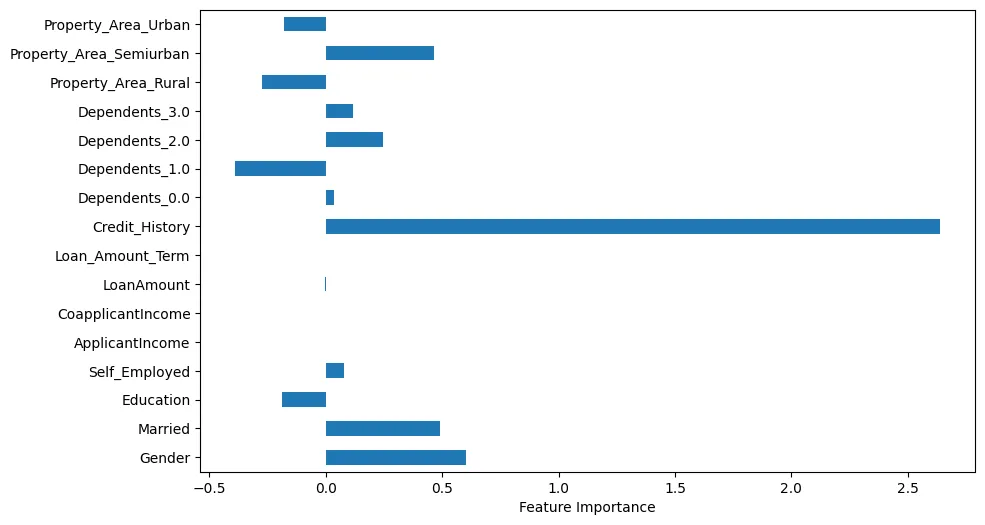
Figura 4: Importanza feature
Ad esempio, vediamo che lastoria creditizia è ovviamente molto importante. Tuttavia, lasituazione matrimoniale e ilsesso sono anche importanti.
Ora faremo delle previsioni utilizzando un singolo esempio di test.
Generiamo un riepilogo dell’applicazione del prestito utilizzandoBidirectional Encoder Representations from Transformers (BERT) con l’esempio di test. Esempio di output:
BERT-Generated Loan Application Summary
applicant : mr blobby income : $ 7787. 0 credit history : 1. 0 loan amount : $ 240. 0 property area : urban area
Model Prediction ('Y' = Approved, 'N' = Denied): Y
Loan Approval Decision: Approved
Utilizzando il riepilogo generato da BERT, creiamo una parola cloud come mostrato in Figura 5.

Vediamo che il nome dell’applicante, l’entrata e la storia creditizia sono più grandi e più prominenti.
Un’altra modalità per cui possiamo analizzare i dati del nostro campione di test è l’utilizzo di SHapley Additive exPlanations (SHAP). In Figura 6 possiamo osservare visivamente le caratteristiche importanti.

Figura 6: SHAP
Un grafico di forza SHAP è un’altra modalità per cui potremmo analizzare i dati, come mostrato in Figura 7.
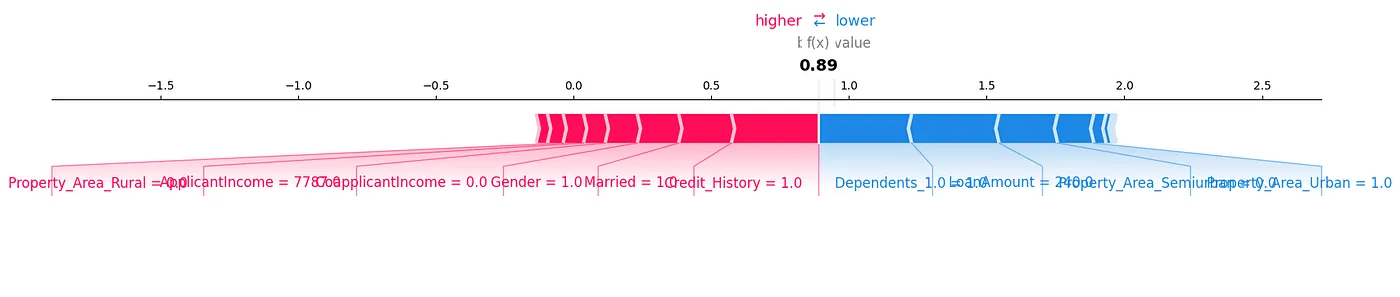
Figura 7: Grafico di Forza
Possiamo vedere come ogni feature contribuisce a una predizione particolare per il nostro campione di test mostrando i valori SHAP in un modo visivo.
Un’altra libreria molto utile è Local Interpretable Model-Agnostic Explanations (LIME). I risultati per questo possono essere generati nel notebook allegato a questo articolo.
Successivamente, creeriamo una Matrice di Confusione (Figura 8) per il nostro modello di Regressione Logistica e genereremo un rapporto di classificazione.
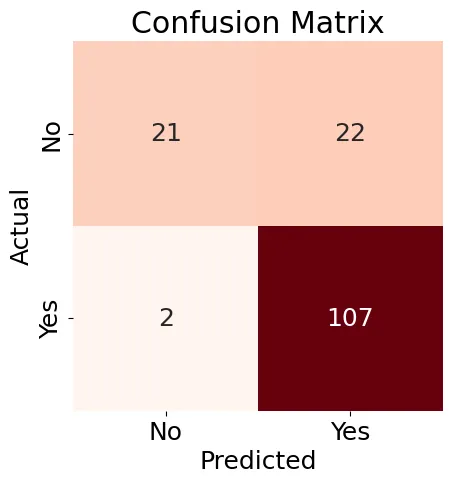
Figura 8: Matrice di Confusione
I risultati mostrati in Figura 8 sono un po’ misti, ma il rapporto di classificazione contiene alcuni risultati buoni:
Accuracy: 0.84
Precision: 0.83
Recall: 0.98
F1-score: 0.90
Classification Report:
precision recall f1-score support
N 0.91 0.49 0.64 43
Y 0.83 0.98 0.90 109
accuracy 0.84 152
macro avg 0.87 0.74 0.77 152
weighted avg 0.85 0.84 0.82 152
In generale, possiamo vedere che l’uso di strumenti e tecniche esistenti di Machine Learning ci dà molti modi diversi per cui analizzare i dati e trovare relazioni interessanti, specialmente a livello di singoli campioni di test.
Successivamente, proviamo a usare LangChain e un LLM e vediamo se possiamo anche fare previsioni di prestiti.
Appena avremo impostato e configurato LangChain, lo testeremo con due esempi, ma limiteriamo l’accesso alla quantità di dati in modo da non superare i limiti di token e di tasso. Ecco l’esempio prima:
query1 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Male
ApplicantIncome: 7787.0
Credit_History: 1
LoanAmount: 240.0
Property_Area_Urban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result1 = run_agent_query(query1, agent_executor, error_string)
print(result1)
In questo caso, la domanda di credito è stata approvata nel dataset originale.
Ecco il secondo esempio:
query2 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Female
ApplicantIncome: 5000.0
Credit_History: 0
LoanAmount: 103.0
Property_Area_Semiurban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result2 = run_agent_query(query2, agent_executor, error_string)
print(result2)
In questo caso, l’applicazione è stata respinta nel dataset originale.
Eseguendo queste query, potremmo ottenere risultati incongruenti. Ciò può essere dovuto alla limitazione della quantità di dati che può essere utilizzata. possiamo anche usare la modalità estesa in LangChain per vedere le fasi che vengono utilizzate per costruire un modello di approvazione del prestito, ma a questo livello iniziale manca informazione dettagliata sulle fasi precise per creare quel modello.
È necessario fare ulteriore lavoro con l’IA conversazionale, poiché molti paesi hanno regole sulla lealtà nell’approvazione del prestito e ci servirebbe una spiegazione dettagliata sull’ ragioni per cui l’IA ha approvato o respinto una particolare applicazione di prestito.
Riepilogo
Oggi, molti potenti strumenti e tecniche migliorano il Machine Learning (ML) per avere insight più profondi nei dati e nei modelli di previsione del prestito. L’IA, attraverso i grandi modelli di linguaggio (LLMs) e i moderni framework, offre il grande potenziale di ampliare o persino sostituire approcchi tradizionali ML. Tuttavia, per avere maggiore fiducia nelle raccomandazioni dell’IA e per conformarsi alle norme legali e sulla lealtà nell’approvazione del prestito in molti paesi, è cruciale capire il ragionamento e il processo decisionale dell’IA.
Source:
https://dzone.com/articles/building-predictive-analytics-for-loan-approvals