













この短い記事では、さまざまなツールと技術を使ってローンの承認について探求します。まず、ローンのデータを分析し、ロジスティック回帰を適用してローンの結果を予測します。さらに、自然言語処理のためにBERTを統合し、予測の精度を向上させます。予測の解釈には、SHAPとLIMEの説明フレームワークを使用して、特徴の重要性とモデルの動作について洞察を提供します。最後に、会話型AIの力を活用して、LangChainを介してローンの予測を自動化する自然言語処理の可能性を探ります。
この記事で使用されるノートブックファイルは、GitHubで入手できます。
はじめに
この記事では、ロジスティック回帰やBERTなどのモデルを使用し、SHAPとLIMEを適用してモデルの解釈を行う、ローンの承認に関するさまざまな技術を探求します。また、会話型AIを使用してローンの予測を自動化するためのLangChainの可能性についても調査します。
SingleStore Cloudアカウントの作成
以前の記事では、無料のSingleStore Cloudアカウントの作成手順を紹介しました。ここでは、Free Shared Tierを使用し、WorkspaceとDatabaseのデフォルト名を使用します。
ノートブックのインポート
GitHubからノートブックをダウンロードします(前述のリンク先)。
SingleStore Cloud ポータルの左側ナビゲーションペインから、開発 > データスタジオを選択します。
ウェブページの右上にある新しいノートブック > ファイルからインポートを選択します。GitHubから下载したノートブックを探してインポートします。
ノートブックを実行する
SingleStore ワークスペースに接続していることを確認した後、单元格を順番に実行します。
最初に必要なライブラリをインストールし、依存関係をインポートし、ほぼ600行のloan dataをCSVファイルから読み取ります。一部の行には欠損したデータがありますので、最初の分析のために不完全な行を削除し、データセットを約500行に缩めます。
次に、データをさらに準備し、特徴量と目標変数を分離します。
視覚化はデータについて大変有益な洞察を提供することができます。まず、図1に示されるように数値のみの特徴量間の相関を示すヒートマップを作成します。
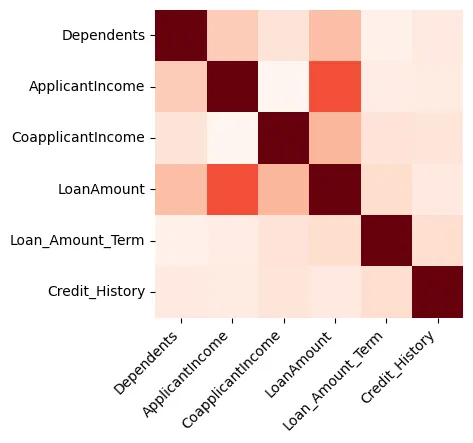
図1: ヒートマップ
私たちはローンアmountと申込者Incomeが強く関連していることを確認できます。
もしローンアmountを申込者Incomeに対してプロットした場合、図2に示されるように、スプレッドシートにおいてほとんどのデータ点は下左手边に集約しています。
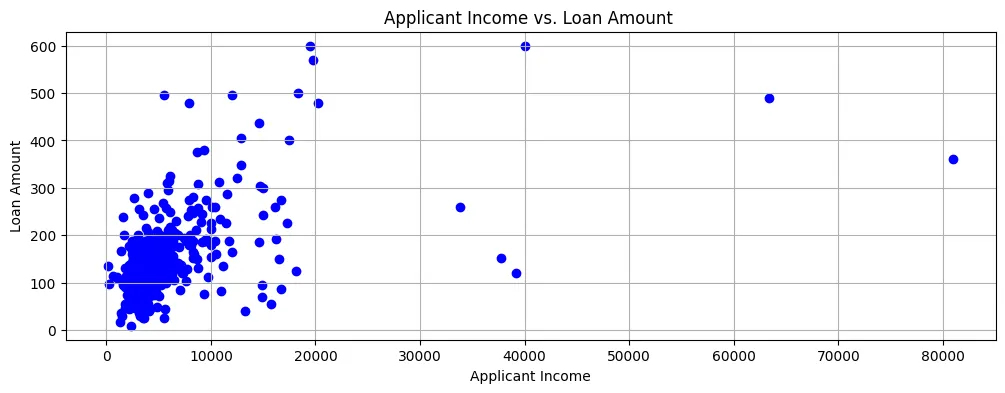
図2: スプレッドシート
したがって、所得は通常は相当に低く、ローンの申し込みもまた比較的小さい量だとわかります。
私たちはローン金额、申込者の所得、共同申込者の所得の対応プロットも作成できます。図3に示されています。
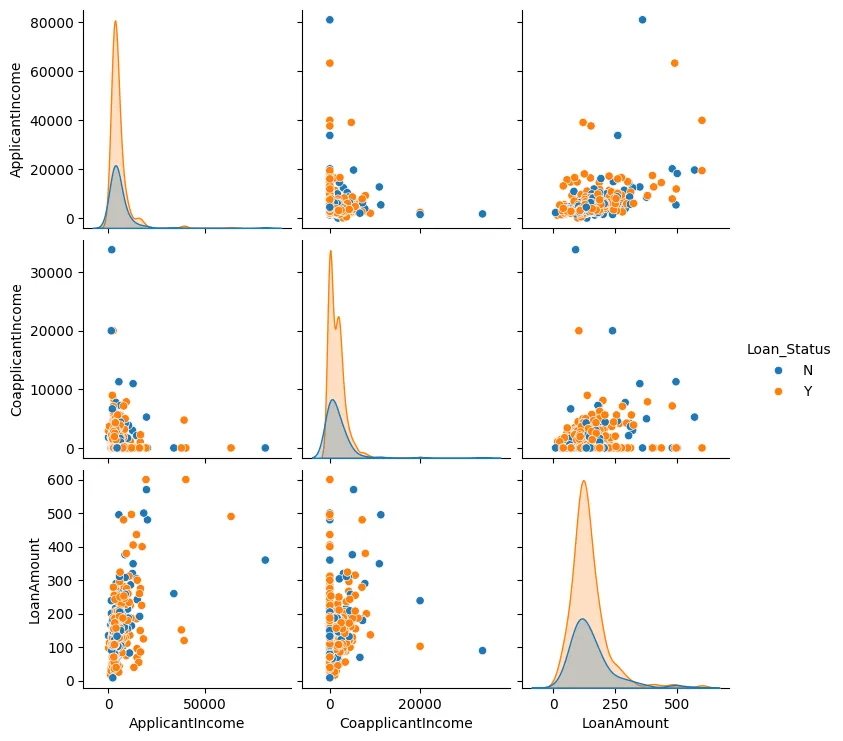
図3: 对応プロット
ほとんどの場合、データ点が集まっており、異常値が少ないことがわかります。
次に、特徴工程を行います。カテゴリーの値を识別し、これらを数値に変換し、必要であればOne-Hotエンコーディングを使用します。
次に、Logistic Regressionを使用してモデルを作成します。贷款申请が承認されるか否かには2つの可能な結果しかありません。
特徴重要性を可視化すると、図4で興味深い observationをすることができます。
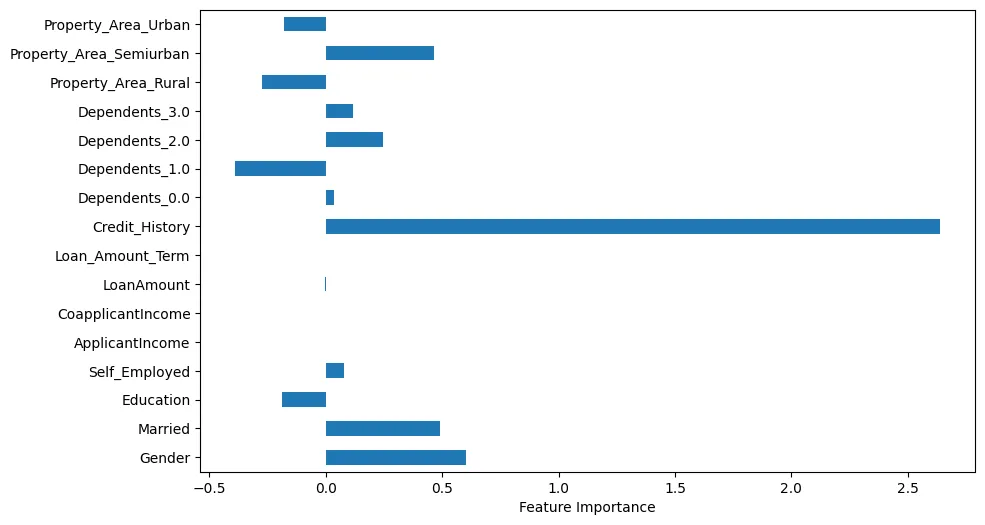
図4: 特徴重要性
たとえば、クレジット歴は明らかに非常に重要です。しかし、婚姻状況と性も重要です。
次に、1つのテストサンプルを使用して予測を行います。
テストサンプルを使用してトランスフォーマーからの二方向エンコーダ表現(BERT)を使用してローン申込概要を生成します。例えば、
BERT-Generated Loan Application Summary
applicant : mr blobby income : $ 7787. 0 credit history : 1. 0 loan amount : $ 240. 0 property area : urban area
Model Prediction ('Y' = Approved, 'N' = Denied): Y
Loan Approval Decision: Approved
BERT生成の概要を使用して、図5に示されるような単語雲を作成します。

申请人の名前、所得、クレジット歴が大きく、显著であることがわかります。
SHapley Additive exPlanations(SHAP)を使用して、私たちはテストサンプルのデータを分析する別の方法があります。図6では、重要な特徴を視覚的に見ることができます。

図6:SHAP
SHAP力プロットは、データを分析するもう一つの方法であり、図7に示されています。
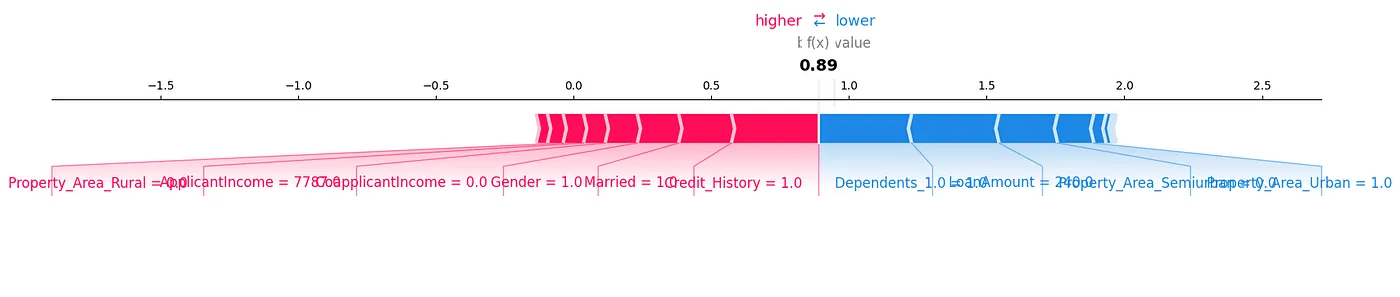
図7:力プロット
私たちは、各特徴がテストサンプルの特定の予測にどのように貢献するかを示すために、SHAP値を視覚的に表示することができます。
もう一つ非常に有用なライブラリはLocal Interpretable Model-Agnostic Explanations(LIME)です。この結果は、この記事に添付されたノートブックで生成できます。
次に、私たちはLogistic Regressionモデルのための混乱マトリクス(図8)を作成し、分類レポートを生成します。
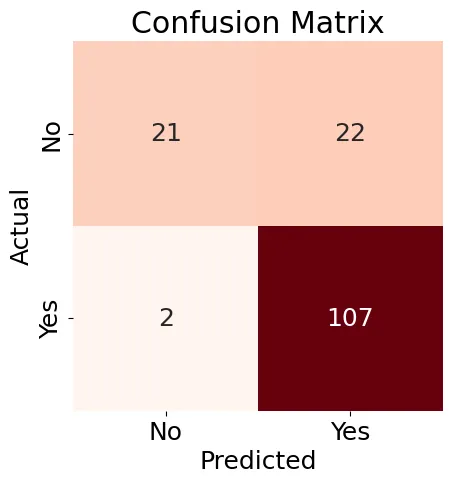
図8:混乱マトリクス
図8に示された結果は少し混ざり合っていますが、分類レポートにはいくつかの良い結果が含まれています:
Accuracy: 0.84
Precision: 0.83
Recall: 0.98
F1-score: 0.90
Classification Report:
precision recall f1-score support
N 0.91 0.49 0.64 43
Y 0.83 0.98 0.90 109
accuracy 0.84 152
macro avg 0.87 0.74 0.77 152
weighted avg 0.85 0.84 0.82 152
全体的に、既存の機械学習ツールと技術を使用することで、私たちはデータを分析し、特に個別のテストサンプルのレベルで興味深い関係を見つけることができる多くの可能な方法を持っています。
次に、LangChainとLLMを使用して、ローン予測を行うことを试みましょう。
LangChainを設定し、構成した後、2つの例をテストしますが、データの量を制限して、トークンとレートの上限を超えないようにする。以下は第1の例です:
query1 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Male
ApplicantIncome: 7787.0
Credit_History: 1
LoanAmount: 240.0
Property_Area_Urban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result1 = run_agent_query(query1, agent_executor, error_string)
print(result1)
この場合、原典 datasetではアプリケーションが承認されていました。
これは第2の例です。
query2 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Female
ApplicantIncome: 5000.0
Credit_History: 0
LoanAmount: 103.0
Property_Area_Semiurban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result2 = run_agent_query(query2, agent_executor, error_string)
print(result2)
この場合、アプリケーションは元のデータセットで拒否されました。
これらのクエリを実行すると、不一致な結果が得られるかもしれません。これは利用できるデータの量を制限するために起きる可能性があります。LangChainでは冗長模式を使用して、貸し批准モデルを構築する際の手順を確認できますが、この初期レベルではそのモデルを作成する詳細な手順についての情報が十分ではありません。
会話型AIにより多くの作业が必要です、多くの国では公正な貸し出し規則があり、AIが特定の貸し出し申请を承認または拒否した理由について詳細な説明が必要です。
要約
今日、多くの強力なツールと技術が、データに deep insight を提供するための機械学習(ML)を強化し、ローン予測モデルにより優れた結果を得ることができます。大規模な言語モデル(LLM)と現代的なフレームワークを通じて、AIは従来のMLアプローチを補強または完全に代替する大きな可能性を提供しています。しかし、AIの推奨に対する自信を持ち、多くの国の法律および公正な貸し出し要求に従うためには、AIの理由づけと決定プロセスを理解することが非常に重要です。
Source:
https://dzone.com/articles/building-predictive-analytics-for-loan-approvals