













Neste curto artigo, exploraremos as aprovações de empréstimos usando uma variedade de ferramentas e técnicas. Começaremos分析ando dados de empréstimos e aplicando Regressão Logística para prever resultados de empréstimos. A partir disso, integraremos BERT para Processamento de Linguagem Natural para melhorar a precisão de previsão. Para interpretar as previsões, usaremos os frameworks de explicação SHAP e LIME, fornecendo insights sobre a importância de features e o comportamento do modelo. Finalmente, exploraremos o potencial do Processamento de Linguagem Natural através de LangChain para automatizar previsões de empréstimos, usando o poder de IA conversacional.
O arquivo de notebook usado neste artigo está disponível no GitHub.
Introdução
Neste artigo, exploraremos diversas técnicas para aprovações de empréstimos, usando modelos como Regressão Logística e BERT, e aplicando SHAP e LIME para interpretação do modelo. Também investigaremos o potencial de usar LangChain para automatizar previsões de empréstimos com AI conversacional.
Criar uma Conta SingleStore Cloud
Um artigo anterior mostrou as etapas para criar uma conta SingleStore Cloud gratuita. Usaremos a Etapa Gratuita Compartilhada e assumiremos os nomes padrão para o Workspace e o Banco de Dados.
Importar o Notebook
Baixaremos o notebook do GitHub (ligado anteriormente).
No painel de navegação esquerdo do portal SingleStore Cloud, selecionaremos DEVELOP > Data Studio.
No topo direito da página web, selecionaremos Novo Notebook > Importar do Arquivo. Usaremos o assistente para localizar e importar o notebook que baixamos do GitHub.
Executar o Notebook
Após verificar que estamos conectados ao nosso espaço de trabalho SingleStore, executaremos as células uma por uma.
Começaremos instalando as bibliotecas necessárias e importando as dependências, seguindo carregando os dados de empréstimo de um arquivo CSV que contém quase 600 linhas. Como algumas linhas possuem dados faltantes, descartaremos as incompletas para a análise inicial, reduzindo o conjunto de dados para cerca de 500 linhas.
A seguir, prepararemos os dados ainda mais e separaremos as features e variáveis alvo.
As visualizações podem fornecer excelentes insights sobre os dados, e começaremos criando um heatmap que mostra a correlação entre as features numéricas, como mostrado na Figura 1.
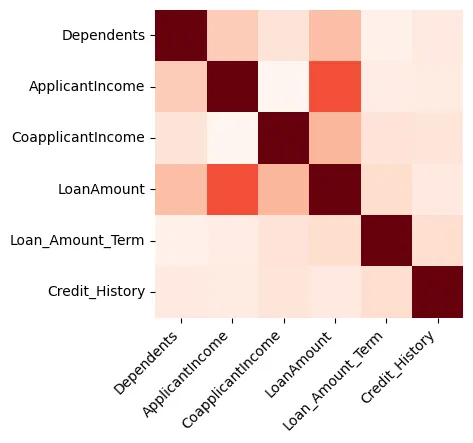
Figura 1: Heatmap
Podemos ver que o Valor do Empréstimo e o Renda do candidato estão fortemente relacionados.
Se plotarmos o Valor do Empréstimo contra o Renda do candidato, podemos ver que a maioria dos pontos de dados estão na parte inferior esquerda do gráfico de dispersão, como mostrado na Figura 2.
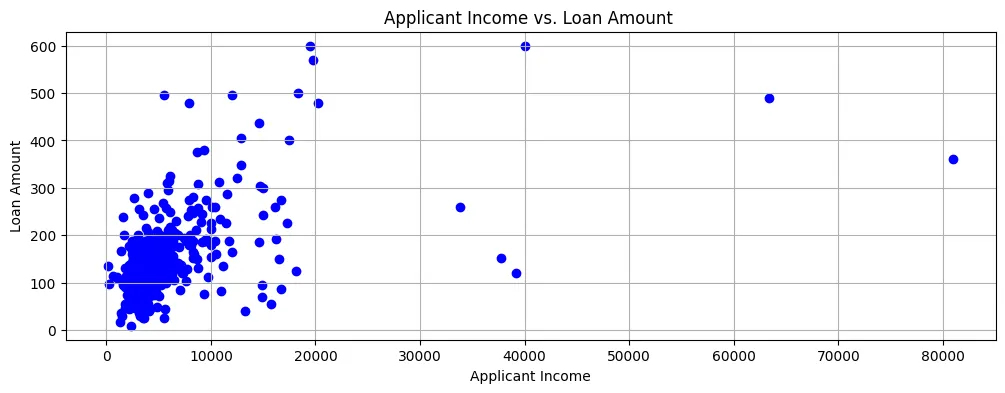
Figura 2: Gráfico de dispersão
Então, as rendas geralmente são muito baixas e as aplicações de empréstimo também são para quantias razoavelmente pequenas.
Também podemos criar um gráfico de pares para o Montante do Empréstimo, Renda do Solicitante, e Renda do Cônjuge, como mostrado na Figura 3.
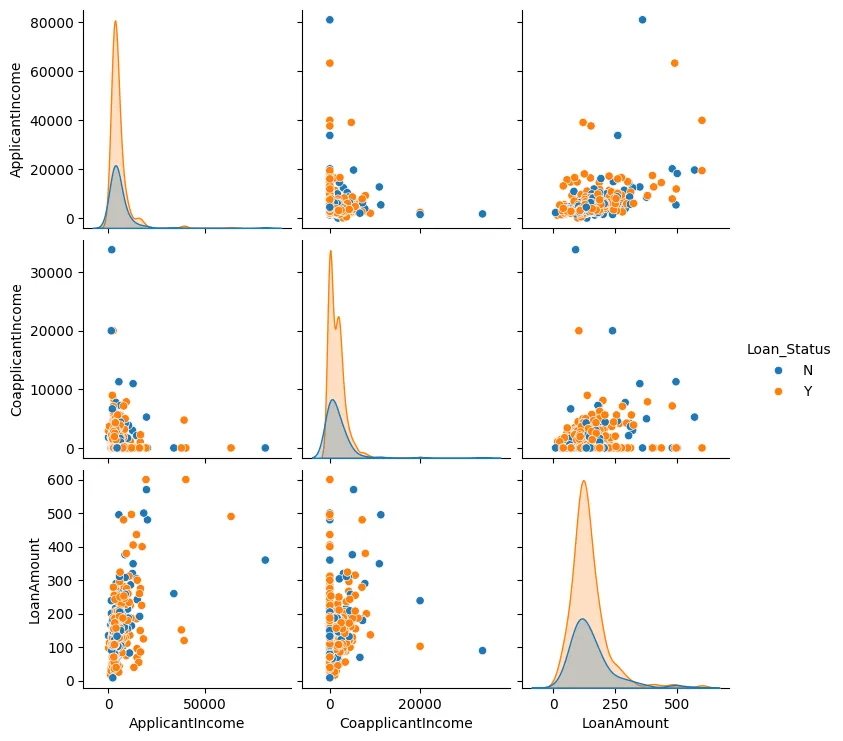
Figura 3: Gráfico de Pares
Na maioria dos casos, podemos ver que os pontos de dados tendem a agrupar juntos e há geralmente poucos valores anomalos.
Agora, faremos algum engenharia de recursos. Identificaremos os valores categoricos e convertê-los em valores numéricos, e também usaremos codificação one-hot onde necessário.
A seguir, criaremos um modelo usando Regressão Logística pois há apenas duas saídas possíveis: ou a aplicação de empréstimo é aprovada ou negada.
Se visualizarmos a importância dos recursos, podemos fazer algumas observações interessantes, como mostrado na Figura 4.
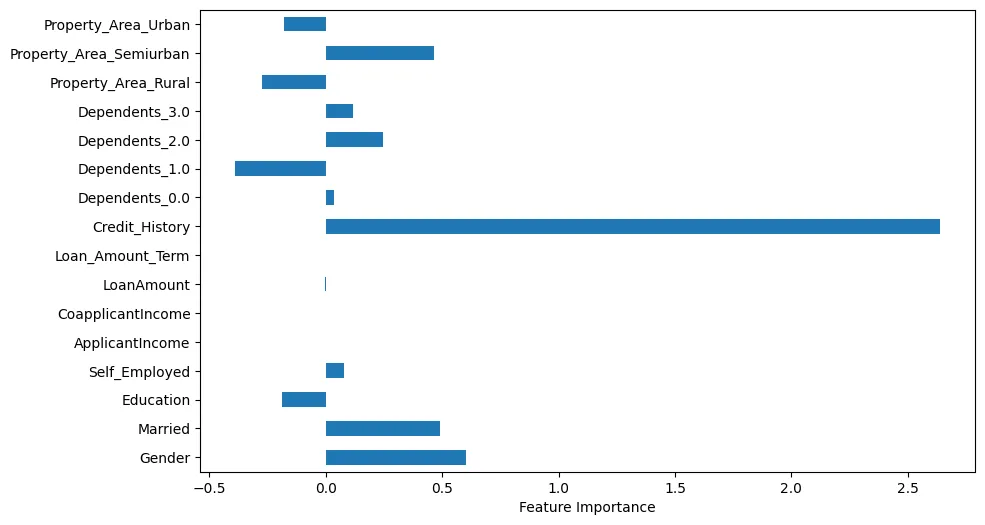
Figura 4: Importância dos Recursos
Por exemplo, podemos ver que Histórico de Crédito é obviamente muito importante. No entanto, Estado Civil e Gênero também são importantes.
Agora, faríamos previsões usando um amostra de teste.
Geraríamos um resumo de inscrição de empréstimo usando Bidirectional Encoder Representations from Transformers (BERT) com a amostra de teste. Exemplo de saída:
BERT-Generated Loan Application Summary
applicant : mr blobby income : $ 7787. 0 credit history : 1. 0 loan amount : $ 240. 0 property area : urban area
Model Prediction ('Y' = Approved, 'N' = Denied): Y
Loan Approval Decision: Approved
Usando o resumo gerado por BERT, criaremos um núcleo de palavras como mostrado na Figura 5.

Podemos ver que o nome do solicitante, a renda e o histórico de crédito são maiores e mais proeminentes.
Outra forma de analisarmos os dados de nossa amostra de teste é usando SHapley Additive exPlanations (SHAP). Na Figure 6, podemos visualmente ver as features que são importantes.

Figure 6: SHAP
Um gráfico de força SHAP é outra forma que nós poderíamos analisar os dados, como mostrado na Figure 7.
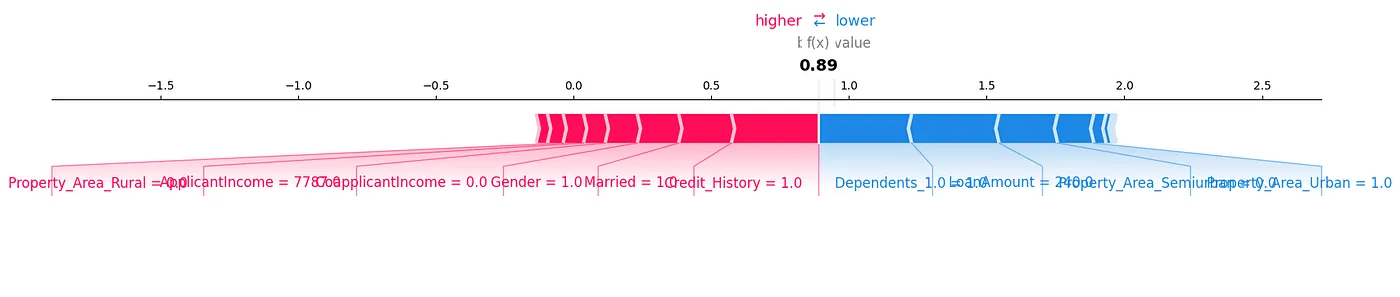
Figure 7: Force Plot
Podemos ver como cada feature contribui para uma previsão particular para nossa amostra de teste, mostrando os valores SHAP de uma maneira visual.
Outra biblioteca muito útil é a Local Interpretable Model-Agnostic Explanations (LIME). Os resultados para isso podem ser gerados no notebook anexo a este artigo.
Em seguida, nós criaremos uma Matriz de Confusão (Figure 8) para o nosso modelo de Regressão Logística e geraremos um relatório de classificação.
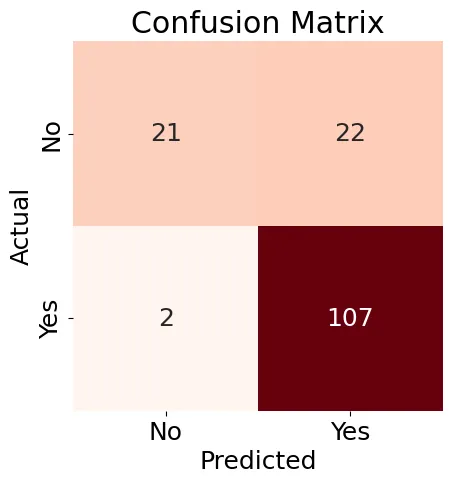
Figure 8: Confusion Matrix
Os resultados mostrados na Figure 8 são um pouco misturados, mas o relatório de classificação contém alguns bons resultados:
Accuracy: 0.84
Precision: 0.83
Recall: 0.98
F1-score: 0.90
Classification Report:
precision recall f1-score support
N 0.91 0.49 0.64 43
Y 0.83 0.98 0.90 109
accuracy 0.84 152
macro avg 0.87 0.74 0.77 152
weighted avg 0.85 0.84 0.82 152
Globalmente, nós podemos ver que usar ferramentas e técnicas de Machine Learning existentes dá-nos muitas formas possíveis de analisar os dados e encontrar relações interessantes, particularmente ao nível de uma amostra de teste individual.
Em seguida, vamos usar o LangChain e um LLM e ver se podemos fazer também previsões de empréstimos.
Assim que tivermos configurado e configurado o LangChain, testaremos-lo com dois exemplos, mas restringiremos o acesso à quantidade de dados para que não ultrapasssem os limites de tokens e taxas. Aqui está o primeiro exemplo:
query1 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Male
ApplicantIncome: 7787.0
Credit_History: 1
LoanAmount: 240.0
Property_Area_Urban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result1 = run_agent_query(query1, agent_executor, error_string)
print(result1)
Neste caso, a aplicação foi aprovada na base de dados original.
Aqui está o segundo exemplo:
query2 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Female
ApplicantIncome: 5000.0
Credit_History: 0
LoanAmount: 103.0
Property_Area_Semiurban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result2 = run_agent_query(query2, agent_executor, error_string)
print(result2)
Neste caso, a aplicação foi negada no conjunto de dados original.
Executando estas consultas, podemos obter resultados inconsistentes. Isto pode ser devido a restrições na quantidade de dados que pode ser usada. Também podemos usar o modo detalhado em LangChain para ver as etapas sendo usadas para construir um modelo de aprovação de empréstimo, mas há informação insuficiente neste nível inicial sobre as etapas detalhadas para criar esse modelo.
Mais trabalho é necessário com IA conversacional, já que muitos países têm regras de emprestimo justo e precisamos de uma explicação detalhada sobre por que a AI aprovou ou negou uma determinada aplicação de empréstimo.
Resumo
Atualmente, muitas ferramentas e técnicas poderosas melhoram o Aprendizado de Máquina (AM) para obter insights mais profundos em dados e modelos de previsão de empréstimos. A IA, através de Modelos de Linguagem Grande (LLMs) e frameworks modernos, oferece grande potencial para ampliar ou até mesmo substituir abordagens tradicionais de AM. No entanto, para maior confiança nas recomendações da IA e para cumprir com as exigências legais e de emprestimo justo de muitos países, é crucial entender o processo de raciocínio e de tomada de decisão da AI.
Source:
https://dzone.com/articles/building-predictive-analytics-for-loan-approvals