













이 简単한 記事에서는 diverses ツールや技法を使用して、ローン承認を探ることにします。私たちは、ローン 데이터를 분석하고、ログistisches 回帰を適用して、ローンの結果を予測することから始めます。これを基に、BERTを統合し、自然言語処理を強化して予測精度を向上させます。予測の解釈には、SHAPとLIMEの説明框架を使用し、特徴の重要性とモデルの行動について洞察を提供します。最後に、LangChainを使用して、会話型AIの力を活用してローン予測を自動化する可能性を探ることにします。
この記事で使用されたノートブックファイルは、GitHub 上にあります。
はじめに
この記事で、ローン承認の様々な技法を探索し、Logistic RegressionやBERTなどのモデルを使用し、SHAPとLIMEを適用してモデルの解釈を行います。また、LangChainを使用して、会話型AIとしての力を活用してローン予測を自動化する可能性を探ることもします。
SingleStore Cloud アカウントを作成する
前の記事では、無料のSingleStore Cloudアカウント作成の手順を説明しました。私たちは、無料共有層を使用し、ワークスペースとデータベースにデフォルトの名前を付けます。
ノートブックをインポートする
GitHubからノートブックを下载します(先ほどリンクされました)。
SingleStore Cloud 포털의 왼쪽 ナビゲーション 패널에서 DEVELOP > Data Studio를 선택한다.
웹 페이지의 상단 오른쪽에서 New Notebook > Import From File를 선택한다. GitHub에서 다운로드 받은 노트북을 위한 嚮導를 사용하여 위치하고 가져오는 것을 시도한다.
노트북 실행
SingleStore 작업 공간과 연결되었는지 확인한 후, 셀을 逐个 실행한다.
필요한 라이브러리를 설치하고 依存성을 導入하고 시작하고, 이를 따라 보면 CSV 파일로부터 600行近く의 대출 데이터를 로드하고 있다. 일부 행에 데이터가 없어 첫 번째 분석에서 이를 drop하고 dataset을 约 500行으로 줄여준다.
다음에 데이터를 further 준비하고 특징과 목표 변수를 분리한다.
시각화는 数据分析에서 큰 洞見을 제공할 수 있으며, 이를 시작하기 위해 숫자 전용 특징 사이의 相関性을 보여주는 heatmap을 생성하는 것을 시도한다, 그 예제는 그림 1과 같다.
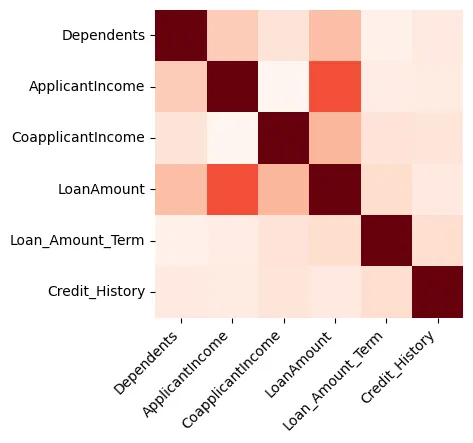
Figure 1: Heatmap
我们可以看到대출 금액과 신청자 수입가 강하게 관련이 있다.
如果我们绘制대출 금액과 신청자 수입對比图, 그 그림 2과 같이 대부분의 데이터 포인트가 散布图의 왼下角에 있다는 것을 볼 수 있다.
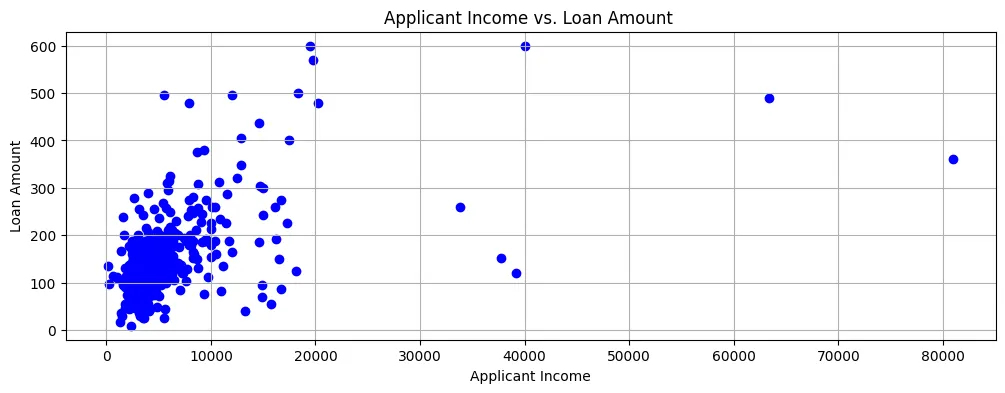
Figure 2: Scatter Plot
所以, 수입은 대부분이 상당히 낮고 대출 신청은 또한 상당히 작은 금액의 것입니다.
我们也可以为贷款金额,申请人收入和共同申请人收入创建一个成对图,如图3所示。
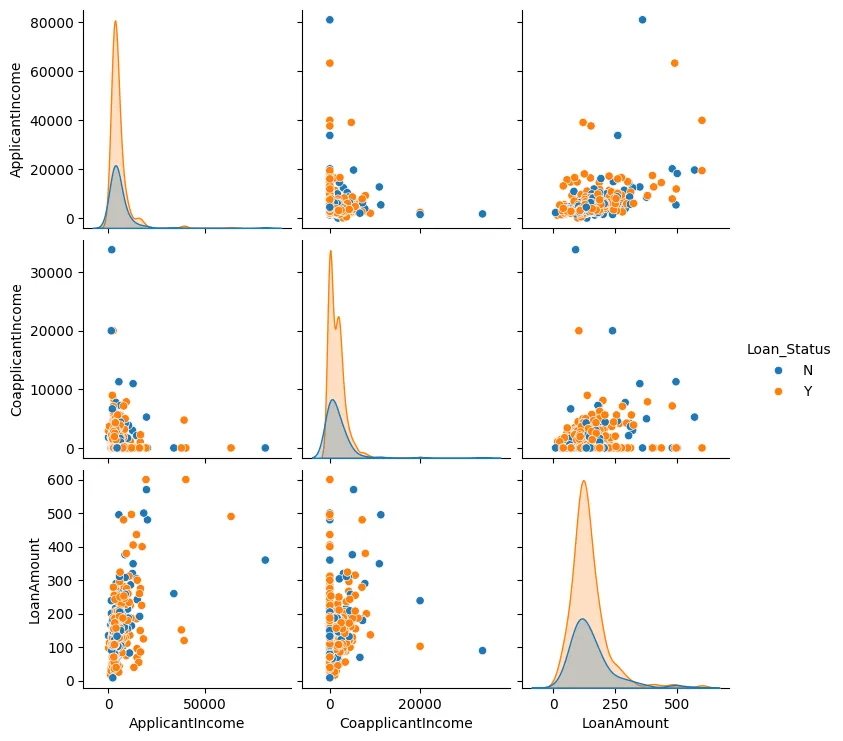
图3:成对图
在大多数情况下,我们可以看到数据点倾向于聚集在一起,通常只有少数异常值。
接下来,我们将进行一些特征工程。我们将识别出分类值并将这些值转换为数值,并在需要时使用独热编码。
然后,我们将使用逻辑回归创建一个模型,因为只有两种可能的结果:要么贷款申请被批准,要么被拒绝。
如果我们可视化特征重要性,我们可以做出一些有趣的观察,如图4所示。
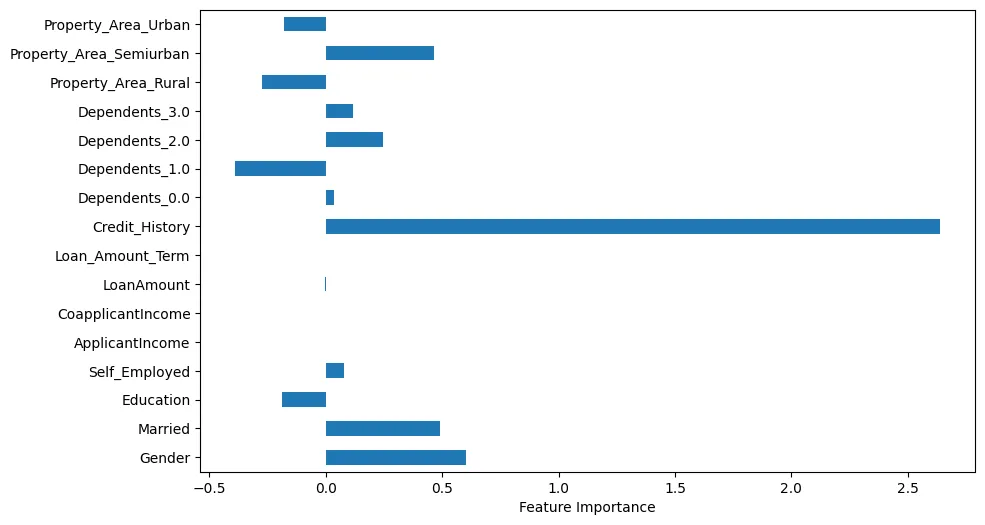
图4:特征重要性
例如,我们可以看到信用历史显然非常重要。然而,婚姻状况和性别也是重要的。
现在我们将使用一个测试样本来进行预测。
我们将使用双向编码器表示转换器(BERT)来生成测试样品的贷款申请摘要。示例输出:
BERT-Generated Loan Application Summary
applicant : mr blobby income : $ 7787. 0 credit history : 1. 0 loan amount : $ 240. 0 property area : urban area
Model Prediction ('Y' = Approved, 'N' = Denied): Y
Loan Approval Decision: Approved
使用BERT生成的摘要,我们将创建一个如图5所示的词云。

我们可以看到申请人的姓名、收入和信用历史较大且更为突出。
또 다른 방법으로 우리는 SHapley Additive exPlanations(SHAP)를 사용하여 시험 샘플의 数据分析을 하실 수 있습니다. 그 figure 6에서는 중요한 특징을 시각적으로 보실 수 있습니다.

Figure 6: SHAP
SHAP 포orce 플롯은 数据分析하는 다른 방법입니다. Figure 7에서 볼 수 있습니다.
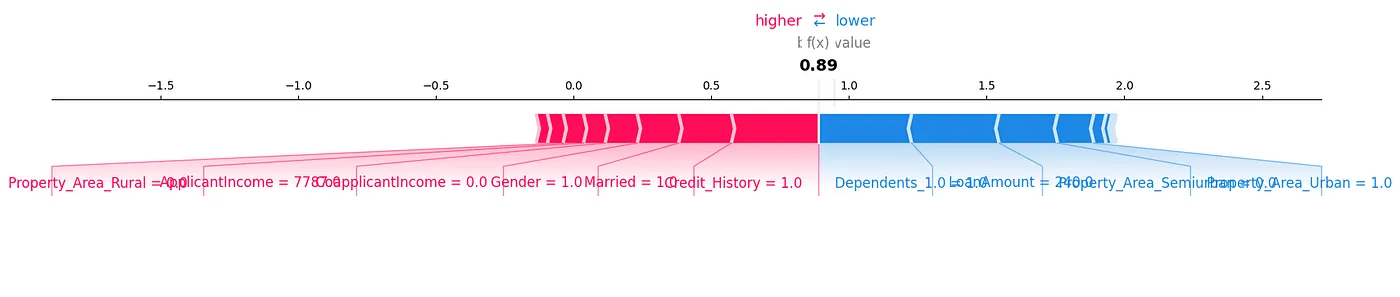
Figure 7: Force Plot
우리는 시험 샘플의 특정 예측에 어느 정도 기여하는지 보기 위해 SHAP 값을 시각적으로 보일 수 있습니다.
또 다른 유용한 라이브러리는 Local Interpretable Model-Agnostic Explanations(LIME)입니다. 이 라이브러리의 결과는 이 문서와 함께 노트북에서 생성할 수 있습니다.
次に、우리의 로지스틱 회귀 모델에 대한 헝ㅡ보 매트릭스(Figure 8)를 생성하고 분류 보고서를 생성하겠습니다.
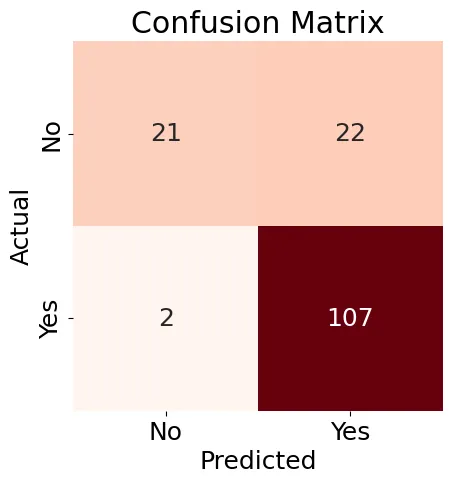
Figure 8: Confusion Matrix
Figure 8에 보여지는 결과는 조금 혼란스러울 수 있지만, 분류 보고서는 좋은 결과를 포함하고 있습니다.
Accuracy: 0.84
Precision: 0.83
Recall: 0.98
F1-score: 0.90
Classification Report:
precision recall f1-score support
N 0.91 0.49 0.64 43
Y 0.83 0.98 0.90 109
accuracy 0.84 152
macro avg 0.87 0.74 0.77 152
weighted avg 0.85 0.84 0.82 152
전체적으로는 现存的 기계 leaning 도구와 기술을 사용하면 数据分析하고 특정 시험 샘플 层次에서 기사적인 관계를 발견하는 여러 가능성을 얻을 수 있음을 볼 수 있습니다.
次に、LangChain과 LLM을 사용하여 대출 예측을 해봅시다.
LangChain을 세팅하고 구성한 다음, 두 예시를 시험하지만, 데이터 량을 제한하여 토큰과 률 한도를 초과하지 않도록 하겠습니다. 첫 번째 예시는 다음과 같습니다.
query1 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Male
ApplicantIncome: 7787.0
Credit_History: 1
LoanAmount: 240.0
Property_Area_Urban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result1 = run_agent_query(query1, agent_executor, error_string)
print(result1)
이 사례에서는 원래의 dataset에서 대출 지원이 승인되었습니다.
이 두 번째 예제에 대해서는
query2 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Female
ApplicantIncome: 5000.0
Credit_History: 0
LoanAmount: 103.0
Property_Area_Semiurban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result2 = run_agent_query(query2, agent_executor, error_string)
print(result2)
이 원래의 데이터셋에서 사용하지 못한 것처럼 보입니다.
이러한 쿼리를 실행하면 불일치하는 result를 얻을 수 있습니다. 이것이 数据分析에서 사용할 수 있는 데이터의 양이 제한되는 것이 原因일 수 있습니다. LangChain에서는 动词ose 모드를 사용하여 대출 승인 모델을 만들기 위한 과정을 보실 수 있지만, 이 초기 수준에서는 이 모델을 만들기 위한 상세한 과정을 알 수 없습니다.
대화형 AI와 더 많은 작업이 필요합니다. 많은 국가들은 공정한 대출 규칙을 가지고 있으며, AI가 특정 대출 신청을 승인하거나 거부하는 이유에 대해 상세한 explaination을 얻는 것이 중요합니다.
요약
오늘날, 강력한 도구和技术을 사용하여 Machine Learning (ML)을 강화하여 데이터에 깊은 洞见을 얻고 대출 예측 모델을 생성할 수 있습니다. AI는 대형 언어 모델 (LLM)과 현대 框架을 통해 传统的 ML 접근 방법을 보다 강력하게 대체할 수 있는 큰 潜力을 제공합니다. 그러나 많은 국가에서 法律과 공정한 대출 요구 사항을 만족하기 위해서 AI의 建议을 더 신뢰할 수 있게하고 이 AI의 이유와 결정 과정을 이해하는 것이 중요합니다.
Source:
https://dzone.com/articles/building-predictive-analytics-for-loan-approvals