













Большие организации, в которых количество пользователей, получающих доступ к важным данным, довольно высоко, сталкиваются с множеством проблем при управлении точным доступом.
Различные службы AWS, такие какIAM, Lake Formation и S3 ACL, могут помочь в управлении точным доступом. Однако существуют сценарии, когда одна сущность, содержащая глобальные данные, должна быть доступна нескольким группам пользователей по всей системе с ограниченным доступом. Кроме того, организации с глобальным присутствием могут работать в различных средах и с различными наборами инструментов, поэтому перемещение и каталогизация данных становятся очень трудоемкими.
Например, пользователь хочет получить доступ к данным о продажах из таблицы для аналитических целей, но ему должен быть запрещен доступ только к данным о продажах, связанным с регионом Австралии. Другие данные ему быть недоступны. Кроме того, он хочет получить доступ к данным из другой облачной платформы для выполнения нескольких операций DML, поэтому ему необходимо привести данные и преобразовать их в формат, поддерживаемый инструментом, для обработки, что вызывает задержки.
Для такого типа сценариев требуется контроль данных на уровне атрибутов и данных в различных средах для поддержки форматов инструментов и быстрого доступа.
Мы сделали шаг вперед, чтобы решить эти проблемы и предложить решение по трансформации облака с использованием Lake Formation для управления данными в таблице Apache Iceberg, которую можно запросить и каталогизировать в самом AWS S3 и получить доступ к ней на различных платформах и облаках.
Используя опцию фильтрации данных в Lake Formation, мы можем обеспечить безопасность на уровне столбцов, строк и ячеек.
Что такое формат таблицы Iceberg?
Iceberg — это формат таблиц с открытым исходным кодом со следующими преимуществами:
- Iceberg полностью поддерживает гибкие SQL-команды, что позволяет обновлять, объединять и удалять данные. Iceberg может использоваться для перезаписи файлов данных для улучшения производительности чтения и использования удаленных дельт для ускорения темпа обновлений.
- Iceberg поддерживает полную эволюцию схемы. Обновления схемы в таблицах Iceberg изменяют только метаданные, не затрагивая сами файлы данных. Изменения в эволюции схемы включают добавление, удаление, переименование, изменение порядка и повышение типа.
- Данные, хранящиеся в озере данных или архитектуре сетки данных, доступны для нескольких независимых приложений одновременно в организации.
- Iceberg предназначен для использования с огромными аналитическими наборами данных. Он предлагает несколько функций, спроектированных для увеличения скорости и эффективности запросов, включая быстрое планирование сканирования, обрезку метаданных файлов, которые не нужны, и возможность фильтровать файлы данных, не содержащие соответствующих данных.
Обзор решения
Решение, которое мы предложили, заключается в использовании сервиса Lake Formation для создания фильтров данных, на которые мы можем предоставить разрешения пользователю для доступа. Основу решения составляет использование формата таблиц Iceberg, которые каталогизируются, а затем дополняются условиями фильтра для управления доступом.

Поток данных
- DMS или Glue используются для извлечения данных из репозиториев исходной системы для их сохранения в назначенном ведре S3.
- Архитектура, основанная на событиях, запускает событие при передаче S3 для вызова соответствующей функции Lambda для запуска процесса ETL.
- Данные будут сохранены в формате таблиц Iceberg и будут каталогизированы.
- Данные могут быть обработаны и преобразованы с использованием Glue, используя готовые модели GenAI.
- Обработанные данные будут храниться в Redshift для потребления.
- Каталогизированные таблицы Iceberg будут дополнены столбцом тегов (значение тега сопоставляется с группой пользователей).
На изображении ниже показан пример фильтра данных и его внешний вид. Мы также можем ограничить количество столбцов с помощью фильтров данных.
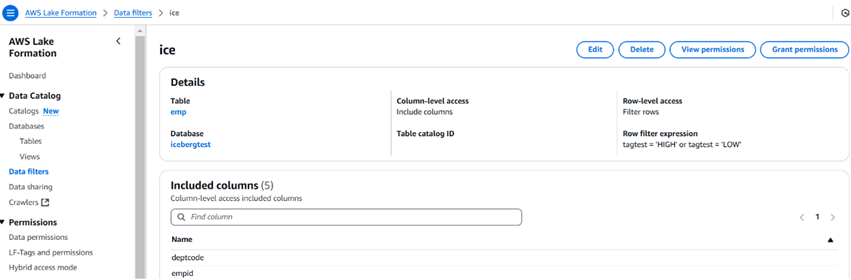
После создания фильтра мы можем использовать опцию предоставления разрешения для предоставления разрешения пользователям, ролям, группам и учетным записям. Пользователь может использовать Athena для запроса данных.
Различные возможности нашего решения:
- Возможность эффективно управлять детализированным контролем доступа к данным.
- Повторное использование фильтров данных для нескольких групп пользователей.
- Мы можем обеспечить безопасность на уровне столбца, строки и ячейки.
- Эффективное использование функций формата таблицы Apache Iceberg для беспрепятственного контроля над данными и их доступом.
- Эффективность и эффективность подготовки данных.
- Централизованное управление доступом и управление с использованием lake formation.
- Меньшее вмешательство вручную в полностью интегрированном решении.
- Поставка данных от начала до конца с использованием облачного агностического решения и серверных компонентов для обеспечения масштабируемости и экономичности.
Преимущества
- Операционная эффективность. Использование серверных компонентов сокращает операционные и технические накладные расходы, связанные с управлением им.
- Оптимизация усилий. Сокращение затрат на 20-30% при использовании моделей GenAI для генерации стандартизированных и эффективных скриптов ETL.
- Преимущества управления и соответствия. Управление на основе атрибутов в lake formation помогает соблюдать стандартные правила и обеспечивает возможности аудита и журналирования.
Промышленное использование
Управление на уровне атрибутов с использованием таблицы Apache Iceberg может быть легко реализовано в финансовом секторе, таком как банк или страховая компания, где клиентам необходимо иметь ограниченный доступ к данным, обеспечивая подлинность и безопасность данных. Сектор здравоохранения может использовать это для создания и обмена электронной медицинской картой пациента быстрым образом, обеспечивая конфиденциальность данных, что может привести к своевременному лечению и приему лекарств.
Заключение
Таким образом, общее решение обеспечит управление на уровне атрибутов в масштабе с подготовкой данных в быстром темпе, используя формат таблицы Apache Iceberg, необходимый для большинства организаций, и реализуя решение с использованием облачных служб Amazon, которое предлагает преимущества быстрых побед, оптимальной стоимости и неограниченной масштабируемости.
Source:
https://dzone.com/articles/attribute-level-governance-apache-iceberg-tables