













當使用者存取關鍵資料的組織規模龐大時,必須面對許多管理細粒度存取的挑戰。
像 IAM、Lake Formation 和 S3 ACL 等多種 AWS 服務可以協助進行細粒度存取控制。但存在某些情況,需要存取包含全球資料的單一實體,且該實體需要被系統中多個使用者群組限制存取。此外,具有全球存在的組織可能在不同環境和使用不同工具集,因此資料移動和目錄編製變得非常繁瑣。
例如,某使用者希望從表格中存取銷售數據以進行分析,但他應僅限於存取與澳大利亞地區相關的銷售數據。不應向他顯示任何其他資料。此外,他希望從不同的雲平台存取資料進行多個 DML 操作,因此需要將資料帶入並轉換為工具的原生格式以進行處理,這將導致延遲。
對於這種情況,我們需要在屬性層級上控制資料,並支援跨環境的資料,以支援原生工具集格式並實現更快的存取。
我們向前邁出一步,解決這些挑戰,並提供了一個利用Lake Formation進行數據治理的雲轉型解決方案,該方案可在Apache Iceberg表中查詢和編目,並可在AWS S3本身和跨平台和雲端訪問。
通過Lake Formation中的數據篩選選項,我們可以確保列級安全性、行級安全性和單元格級安全性。
什麼是Iceberg表格格式?
Iceberg 是一種開源表格格式,具有以下好處:
- Iceberg完全支持靈活的SQL命令,可以進行數據更新、合併和刪除。 Iceberg可用於重寫數據文件以增強讀取性能,並使用刪除增量來加快更新的速度。
- Iceberg支持完整的模式演變。 Iceberg表格中的模式更新僅更改元數據,不影響數據文件本身。 模式演變更改包括添加、刪除、重命名、重新排序和類型提升。
- 存儲在數據湖或數據網格架構中的數據可同時供組織內的多個獨立應用程序使用。
- Iceberg旨在用於處理龐大的分析數據集。它提供了多項功能,旨在提高查詢速度和效率,包括快速掃描計劃、修剪不需要的元數據文件,以及過濾不包含匹配數據的數據文件。
解決方案概述
我們提出的解決方案是使用Lake Formation服務創建數據過濾器,並對用戶授予訪問權限。該解決方案的核心是使用Iceberg表格格式,對其進行目錄管理,然後添加過濾條件以管理訪問權限。

數據流
- DMS或Glue用於從源系統存儲庫中提取數據,並將其存儲在指定的S3存儲桶中。
- 基於事件的架構觸發事件,當S3推送時調用相應的Lambda函數來啟動ETL過程。
- 數據將以Iceberg表格格式存儲並進行目錄管理。
- 可以使用Glue處理和轉換數據,利用GenAI預製模型。
- 處理後的數據將存儲在Redshift中供消費。
- 已添加標籤列(標籤值映射到用戶組)的目錄Iceberg表格。
下面的圖像描述了一個樣本數據過濾器及其外觀。我們還可以使用數據過濾器限制列數。
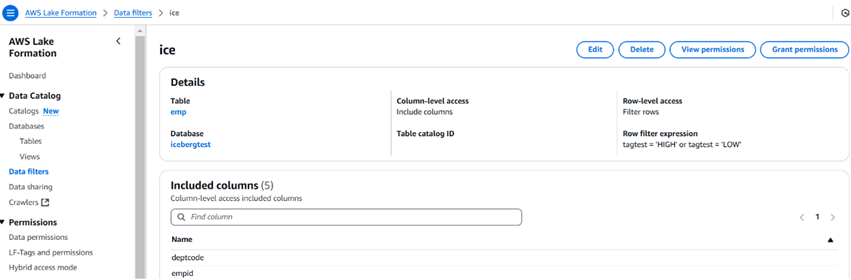
創建過濾器後,我們可以使用授予權限選項向用戶、角色、組和帳戶授予權限。用戶可以使用Athena查詢數據。
我們解決方案的各種功能包括:
- 有效管理對數據的細粒度控制訪問權限。
- 數據過濾器可重複使用於多個用戶組。
- 我們可以實現列級安全、行級安全和單元格級安全。
- 有效使用Apache Iceberg表格格式功能,無縫控制數據及其訪問。
- 數據準備的效率和效果。
- 使用湖形成的集中訪問管理和治理。
- 在完全集成的解決方案中手動干預較少。
- 使用雲不可知解決方案和無服務器組件實現端到端數據交付,以提供可擴展性和成本效益。
好處
- 運營效率</diy13。使用無服務器組件可降低管理所需的操作和維護開支。
- 努力優化</diy15。使用GenAI模型生成標準化和高效的ETL腳本可減少20-30%的努力。
- 治理和合規性好處</diy17。湖形成中的基於屬性的控制有助於遵守標準法規,並提供審計和記錄功能。
工業應用
使用Apache Iceberg表格实现属性级别的治理可以在金融领域(如银行或保险公司)中非常顺畅地实施,客户需要对数据进行受限访问,确保数据的真实性和安全性。医疗保健领域可以使用它快速生成和共享患者的电子健康记录,确保数据的敏感性,从而促进及时的治疗和用药。
结论
因此,整体解决方案将通过使用Apache Iceberg表格式以快速的方式进行数据准备,实现规模化的属性级别治理,这对大多数组织都是必要的,并利用亚马逊云服务来实施解决方案,这将带来快速成功、最优成本和无限的可扩展性。
Source:
https://dzone.com/articles/attribute-level-governance-apache-iceberg-tables