













تواجه المؤسسات الكبيرة التي يكون فيها عدد المستخدمين الذين يصلون إلى البيانات الحاسمة مرتفعًا العديد من التحديات في إدارة الوصول الدقيق.
مجموعة متنوعة من خدمات AWS مثلIAM، Lake Formation، و S3 ACL يمكن أن تساعد في التحكم في الوصول الدقيق. ولكن هناك سيناريوهات حيث يتعين الوصول إلى كيان واحد يحتوي على البيانات العالمية من قبل مجموعات متعددة من المستخدمين عبر النظام بوصول مقيد. أيضًا، قد تكون المؤسسات ذات الوجود العالمي تعمل في بيئات مختلفة وبأدوات مختلفة، لذا يصبح نقل البيانات وتنظيمها مهمة شاقة.
على سبيل المثال، يرغب مستخدم في الوصول إلى بيانات المبيعات من جدول لأغراض التحليل، لكن يجب أن يكون مقيدًا بالوصول فقط إلى بيانات المبيعات المتعلقة بمنطقة أستراليا. لا ينبغي أن تكون أي بيانات أخرى مرئية له. أيضًا، يرغب في الوصول إلى البيانات من منصة سحابية مختلفة لإجراء عمليات DML متعددة، لذا يحتاج إلى جلب البيانات وتحويلها إلى تنسيق الأداة الأصلي لمعالجتها، مما يتسبب في تأخيرات.
لهذا النوع من السيناريو، نحتاج إلى التحكم في البيانات على مستوى السمة والبيانات عبر البيئات لدعم تنسيقات أدوات النظام الأصلية والوصول الأسرع.
لقد قمنا بخطوة إلى الأمام لمعالجة هذه التحديات وتقديم حلاً لتحويل السحابة باستخدام Lake Formation لضمان حكم البيانات على جدول Apache Iceberg، الذي يمكن الاستعلام عنه وفهرسته في AWS S3 نفسه ويمكن الوصول إليه عبر المنصات والسحب.
من خلال خيار تصفية البيانات في Lake Formation، يمكننا ضمان أمان مستوى العمود، وأمان مستوى الصف، وأمان مستوى الخلية.
ما هو تنسيق جدول Iceberg؟
Iceberg هو تنسيق جدول مفتوح المصدر بالفوائد التالية:
- يدعم Iceberg بشكل كامل أوامر SQL المرنة، مما يجعل من الممكن تحديث ودمج وحذف البيانات. يمكن استخدام Iceberg لإعادة كتابة ملفات البيانات لتحسين أداء القراءة واستخدام دلتا الحذف لتسريع وتيرة التحديثات.
- يدعم Iceberg تطور البيانات بالكامل. تغييرات البيانات البيئية في جداول Iceberg تؤثر فقط على البيانات الوصفية، مما يترك ملفات البيانات نفسها دون تأثير. تشمل تغييرات تطور البيئة إضافات وحذف وإعادة تسمية وإعادة ترتيب وترقيات النوع.
- البيانات المخزنة في بحيرة بيانات أو بنية بيانات شبكية متاحة لعدة تطبيقات مستقلة في جميع أنحاء المؤسسة في نفس الوقت.
- تم تصميم Iceberg للاستخدام مع مجموعات بيانات تحليلية ضخمة. يوفر ميزات متعددة مصممة لزيادة سرعة الاستعلام والكفاءة، بما في ذلك تخطيط المسح السريع، وتقليم ملفات البيانات الوصفية التي لا تلزم، والقدرة على تصفية ملفات البيانات التي لا تحتوي على بيانات مطابقة.
نظرة عامة على الحل
الحل الذي اقترحنا هو استخدام خدمة Lake Formation لإنشاء عوامل تصفية البيانات التي يمكننا منح صلاحيات الوصول إليها للمستخدم. جوهر الحل هو استخدام تنسيق جدول Iceberg، الذي يتم تصنيفه ثم إضافته بشروط تصفية للسيطرة على الوصول.

تدفق البيانات
- يتم استخدام DMS أو Glue لاستخراج البيانات من مستودعات النظام المصدر لتخزينها في دلو S3 معين.
- تقوم العمارة القائمة على الحدث بتشغيل حدث عندما يدفع S3 لاستدعاء الوظيفة المناسبة لبدء عملية ETL.
- سيتم تخزين البيانات في تنسيق جدول Iceberg وسيتم تصنيفها.
- يمكن معالجة البيانات وتحويلها باستخدام Glue، باستغلال نماذج GenAI الجاهزة.
- سيتم تخزين البيانات المعالجة في Redshift للاستهلاك.
- سيتم إضافة جداول Iceberg المصنفة بعمود العلامة (قيمة العلامة مرتبطة بمجموعة المستخدم).
الصورة أدناه تصف عينة من عوامل تصفية البيانات وكيفية العرض. يمكننا أيضًا تقييد عدد الأعمدة باستخدام عوامل تصفية البيانات.
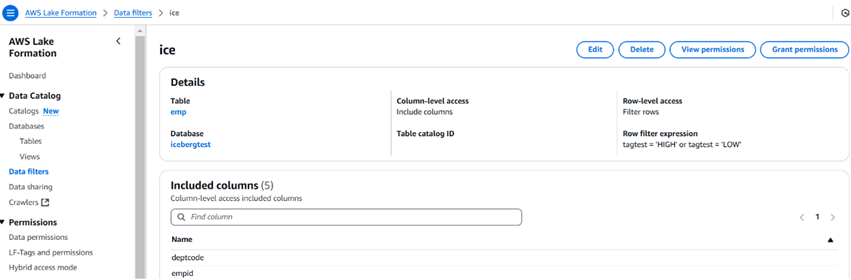
بمجرد إنشاء العوامل التصفية، يمكننا ثم استخدام خيار منح الإذن لمنح إذن للمستخدمين، والأدوار، والمجموعات، والحسابات. يمكن للمستخدم استخدام Athena للاستعلام عن البيانات.
تتضمن القدرات المختلفة لحلنا:
- القدرة على إدارة التحكم الدقيق في الوصول إلى البيانات بشكل فعال.
- إمكانية إعادة استخدام فلاتر البيانات لمجموعات المستخدمين المتعددة.
- يمكننا تحقيق أمان على مستوى الأعمدة، وأمان على مستوى الصفوف، وأمان على مستوى الخلايا.
- الاستخدام الفعال لميزات تنسيق جدول Apache Iceberg لتحقيق تحكم سلس على البيانات والوصول إليها.
- الكفاءة والفعالية في إعداد البيانات.
- إدارة وصول مركزية وحوكمة باستخدام تشكيل البحيرات.
- تدخل يدوي أقل في الحل المتكامل بالكامل.
- تسليم بيانات من البداية إلى النهاية باستخدام حل غير مرتبط بالسحابة ومكونات بدون خادم لتوفير القابلية للتوسع وفعالية التكلفة.
الفوائد
- الكفاءة التشغيلية. استخدام المكونات بدون خادم يقلل من الأعباء التشغيلية والصيانة المرتبطة بإدارتها.
- تحسين الجهد. تقليل بنسبة 20-30% في الجهد من خلال استخدام نماذج GenAI لإنشاء سكربتات ETL موحدة وفعالة.
- فوائد الحوكمة والامتثال. يساعد التحكم القائم على السمات في تشكيل البحيرات على الامتثال للمعايير التنظيمية وتوفير قدرات التدقيق والتسجيل.
الاستخدام الصناعي
يمكن تنفيذ حوكمة مستوى السمة باستخدام جدول Apache Iceberg بسهولة شديدة في القطاع المالي، مثل البنك أو شركة التأمين، حيث يحتاج العملاء إلى وصول مقيد إلى البيانات، مما يضمن صحة وأمان البيانات. يمكن لقطاع الرعاية الصحية استخدامه لإنشاء ومشاركة سجل الصحة الإلكتروني للمريض بطريقة سريعة، مما يضمن حساسية البيانات، مما قد يؤدي إلى العلاج والدواء في الوقت المناسب.
الاستنتاج
لذا، ستوفر الحلول الشاملة حوكمة مستوى السمة بمقياس كبير مع إعداد البيانات بطريقة سريعة باستخدام تنسيق جدول Apache Iceberg الذي يحتاجه معظم المنظمات وتنفيذ الحل باستخدام خدمات أمازون السحابية، والتي توفر فوائد الانتصارات السريعة، والتكلفة الأمثل، وقابلية التوسع غير المحدودة.
Source:
https://dzone.com/articles/attribute-level-governance-apache-iceberg-tables