













Große Organisationen, bei denen die Anzahl der Benutzer, die auf wichtige Daten zugreifen, ziemlich hoch ist, stehen vor vielen Herausforderungen bei der Verwaltung des feingranularen Zugriffs.
Eine Vielzahl von AWS-Diensten wie IAM, Lake Formation und S3 ACL kann bei der feingranularen Zugriffskontrolle helfen. Aber es gibt Szenarien, in denen eine einzelne Entität, die die globalen Daten enthält, von mehreren Benutzergruppen im System mit restriktivem Zugriff abgerufen werden muss. Außerdem könnten Organisationen mit globaler Präsenz in unterschiedlichen Umgebungen und mit unterschiedlichen Werkzeugen arbeiten, sodass die Datenbewegung und -katalogisierung sehr mühsam werden.
Zum Beispiel möchte ein Benutzer auf die Verkaufsdaten aus einer Tabelle für Analysezwecke zugreifen, aber er sollte auf die Verkaufsdaten, die nur die Region Australien betreffen, beschränkt sein. Keine anderen Daten sollten für ihn sichtbar sein. Zudem möchte er auf die Daten von einer anderen Cloud-Plattform für mehrere DML-Operationen zugreifen, weshalb er die Daten übertragen und in das native Format des Werkzeugs zur Verarbeitung umwandeln muss, was zu Verzögerungen führt.
Für dieses Szenario benötigen wir die Datenkontrolle auf Attributebene und Daten über Umgebungen hinweg, um die nativen Format der Werkzeugsets zu unterstützen und einen schnelleren Zugriff zu ermöglichen.
Wir haben einen Schritt unternommen, um diese Herausforderungen anzugehen und eine Cloud-Transformationslösung bereitzustellen, die Lake Formation zur Datenverwaltung auf Apache Iceberg-Tabellen nutzt. Diese können in AWS S3 abgefragt und katalogisiert werden und sind plattform- und cloudübergreifend zugänglich.
Mit der Datenfilteroption in Lake Formation können wir Sicherheit auf Spaltenebene, Zeilenebene und Zellenebene gewährleisten.
Was ist das Iceberg-Tabellenformat?
Iceberg ist ein Open-Source-Tabellenformat mit den folgenden Vorteilen:
- Iceberg unterstützt vollständig flexible SQL-Befehle, die es ermöglichen, Daten zu aktualisieren, zusammenzuführen und zu löschen. Iceberg kann verwendet werden, um Daten zu optimieren und Löschdeltas zu verwenden, um die Aktualisierung zu beschleunigen.
- Iceberg unterstützt vollständige Schemaevolution. Schemaupdates in Iceberg-Tabellen ändern nur die Metadaten, ohne die Daten selbst zu beeinflussen. Zu den Änderungen der Schemaevolution gehören Hinzufügungen, Löschungen, Umbenennungen, Neuanordnungen und Typumwandlungen.
- Daten, die in einem Data Lake oder einer Data Mesh-Architektur gespeichert sind, stehen gleichzeitig mehreren unabhängigen Anwendungen in einer Organisation zur Verfügung.
- Iceberg ist für den Einsatz mit riesigen analytischen Datensätzen konzipiert. Es bietet mehrere Funktionen, die darauf abzielen, die Abfragegeschwindigkeit und Effizienz zu erhöhen, darunter schnelle Scan-Planung, Beschneiden von Metadatendateien, die nicht benötigt werden, und die Möglichkeit, Datendateien zu filtern, die keine übereinstimmenden Daten enthalten.
Lösungsübersicht
Die von uns vorgeschlagene Lösung besteht darin, den Lake Formation-Dienst zu verwenden, um Datenfilter zu erstellen, auf die wir dem Benutzer Zugriffsberechtigungen erteilen können. Das Herzstück der Lösung ist die Verwendung des Iceberg-Tabellenformats, das katalogisiert und dann mit Filterbedingungen versehen wird, um den Zugriff zu regeln.

Datenfluss
- DMS oder Glue wird verwendet, um Daten aus den Quellsystem-Repositorys abzurufen und sie in einem bestimmten S3-Bucket zu speichern.
- Die ereignisbasierte Architektur löst ein Ereignis aus, wenn S3 Daten pushen, um die entsprechende Lambda-Funktion aufzurufen und den ETL-Prozess zu starten.
- Daten werden im Iceberg-Tabellenformat gespeichert und katalogisiert.
- Daten können mit Glue verarbeitet und transformiert werden, wobei die vorgefertigten GenAI-Modelle genutzt werden.
- Verarbeitete Daten werden in Redshift gespeichert, um sie zu verbrauchen.
- Katalogisierte Iceberg-Tabellen werden um die Tag-Spalte erweitert (der Tag-Wert ist auf die Benutzergruppe abgebildet).
Das untenstehende Bild zeigt einen Beispiel-Datenfilter und wie er aussieht. Wir können auch die Anzahl der Spalten mithilfe der Datenfilter begrenzen.
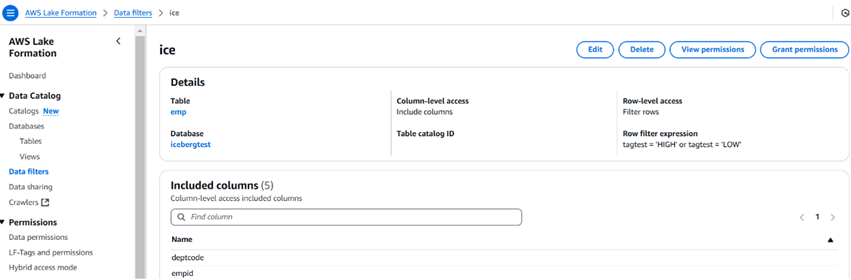
Nachdem der Filter erstellt wurde, können wir dann die Option zur Berechtigungsvergabe verwenden, um Benutzern, Rollen, Gruppen und Konten Berechtigungen zu erteilen. Der Benutzer kann Athena verwenden, um auf die Daten zuzugreifen.
Die verschiedenen Funktionen unserer Lösung sind:
- Die Fähigkeit, die feingranulare Steuerung des Zugriffs auf die Daten effektiv zu verwalten.
- Wiederverwendbarkeit der Datenfilter für mehrere Benutzergruppen.
- Wir können Sicherheit auf Spaltenebene, Zeilenebene und Zellenebene erreichen.
- Effektive Nutzung der Funktionen des Apache Iceberg-Tabellenformats für nahtlose Kontrolle über die Daten und deren Zugriff.
- Effizienz und Effektivität bei der Datenvorbereitung.
- Zentralisierte Zugriffsverwaltung und Governance unter Verwendung von Lake Formation.
- Weniger manuelle Eingriffe in der vollständig integrierten Lösung.
- End-to-End-Datenbereitstellung mit einer cloudagnostischen Lösung und serverlosen Komponenten zur Bereitstellung von Skalierbarkeit und Kosteneffizienz.
Vorteile
- Operative Effizienz. Der Einsatz von serverlosen Komponenten reduziert den betrieblichen und administrativen Aufwand, der mit der Verwaltung verbunden ist.
- Optimierung des Aufwands. Bis zu 20-30%ige Reduzierung des Aufwands durch die Verwendung von GenAI-Modellen zur Generierung standardisierter und effizienter ETL-Skripte.
- Governance- und Compliance-Vorteile. Die attributbasierte Steuerung in Lake Formation hilft, die gängigen Vorschriften einzuhalten und Audit- und Protokollierungsfunktionen bereitzustellen.
Industrielle Nutzung
Die Governance auf Attributebene mit Verwendung der Apache Iceberg-Tabelle kann nahtlos im Finanzsektor implementiert werden, wie beispielsweise bei einer Bank oder einer Versicherung, wo Kunden eingeschränkten Zugriff auf die Daten haben müssen, um die Authentizität und Sicherheit der Daten zu gewährleisten. Der Gesundheitssektor kann es nutzen, um die elektronische Patientenakte schnell zu generieren und zu teilen, um die Sensibilität der Daten zu gewährleisten, was zu rechtzeitiger Behandlung und Medikation führen kann.
Fazit
Die Gesamtlösung wird also die Governance auf Attributebene im großen Stil mit schneller Datenvorbereitung mithilfe des für die meisten Organisationen erforderlichen Apache Iceberg-Tabellenformats liefern und die Lösung unter Verwendung der Amazon Cloud-Services implementieren, was den Vorteil schneller Erfolge, optimaler Kosten und unbegrenzter Skalierbarkeit bietet.
Source:
https://dzone.com/articles/attribute-level-governance-apache-iceberg-tables