













Grandes organizações, onde o número de usuários acessando dados cruciais é bastante alto, enfrentam muitos desafios na gestão de acesso detalhado.
Uma variedade de serviços da AWS como IAM, Lake Formation e S3 ACL podem ajudar no controle de acesso detalhado. Mas existem cenários em que uma única entidade contendo os dados globais precisa ser acessada por múltiplos grupos de usuários em todo o sistema com acesso restrito. Além disso, organizações com presença global podem estar trabalhando em diferentes ambientes e com diferentes conjuntos de ferramentas, tornando o movimento e catalogação de dados muito tediosos.
Por exemplo, um usuário deseja acessar os dados de vendas de uma tabela para fins analíticos, mas ele deve ser restrito a acessar apenas os dados de vendas relacionados à região da Austrália. Nenhum outro dado deve ser visível para ele. Além disso, ele deseja acessar os dados de uma plataforma de nuvem diferente para múltiplas operações de DML, então ele precisa trazer os dados e transformá-los para o formato nativo da ferramenta para processamento, o que causa atrasos.
Para esse tipo de cenário, é necessário o controle de dados no nível do atributo e dados em vários ambientes para suportar os formatos de ferramentas nativas e acesso mais rápido.
Demos um passo à frente para enfrentar esses desafios e entregar uma solução de transformação na nuvem aproveitando o Lake Formation para governança de dados na tabela Apache Iceberg, que pode ser consultada e catalogada no próprio AWS S3 e acessada em várias plataformas e nuvens.
Usando a opção de filtro de dados no Lake Formation, podemos garantir segurança em nível de coluna, segurança em nível de linha e segurança em nível de célula.
O que é o Formato de Tabela Iceberg?
Iceberg é um formato de tabela de código aberto com os seguintes benefícios:
- O Iceberg oferece suporte total a comandos SQL flexíveis, possibilitando a atualização, mesclagem e exclusão de dados. O Iceberg pode ser usado para reescrever arquivos de dados para melhorar o desempenho de leitura e usar deltas de exclusão para acelerar as atualizações.
- O Iceberg oferece suporte completo à evolução de esquema. As atualizações de esquema em tabelas Iceberg alteram apenas os metadados, deixando os arquivos de dados em si inalterados. As alterações de evolução de esquema incluem adições, exclusões, renomeações, reordenações e promoções de tipo.
- Dados armazenados em um data lake ou em uma arquitetura de mesh de dados estão disponíveis para várias aplicações independentes simultaneamente em uma organização.
- Iceberg é projetado para uso com grandes conjuntos de dados analíticos. Ele oferece múltiplos recursos destinados a aumentar a velocidade e eficiência das consultas, incluindo planejamento de varredura rápida, poda de arquivos de metadados que não são necessários e a capacidade de filtrar arquivos de dados que não contêm dados correspondentes.
Visão Geral da Solução
A solução que propusemos é usar o serviço Lake Formation para criar filtros de dados nos quais podemos conceder permissões ao usuário para acesso. O coração da solução é usar o formato de tabela Iceberg, que é catalogado e então adicionado com condições de filtro para governar o acesso.

Fluxo de Dados
- DMS ou Glue é usado para buscar dados dos repositórios do sistema de origem e armazená-los em um bucket S3 designado.
- A arquitetura baseada em eventos aciona um evento à medida que o S3 realiza o push, chamando a respectiva função Lambda para iniciar o processo ETL.
- Os dados serão armazenados no formato de tabela Iceberg e serão catalogados.
- Os dados podem ser processados e transformados usando o Glue, aproveitando os modelos prontos do GenAI.
- Os dados processados serão armazenados no Redshift para consumo.
- Tabelas Iceberg catalogadas serão adicionadas com a coluna de tag (o valor da tag é mapeado para o grupo de usuários).
A imagem abaixo descreve um exemplo de filtro de dados e como ele se parece. Também podemos limitar o número de colunas usando os filtros de dados.
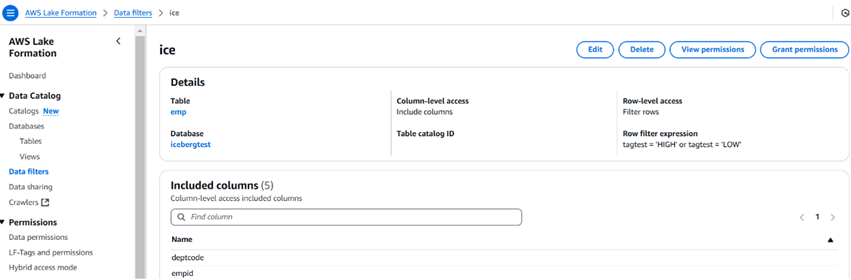
Uma vez que o filtro é criado, podemos então usar a opção de concessão de permissões para dar permissão a usuários, funções, grupos e contas. O usuário pode usar o Athena para consultar os dados.
As várias capacidades da nossa solução são:
- Capacidade de gerenciar efetivamente o controle granular de acesso aos dados.
- Reutilização dos filtros de dados para múltiplos grupos de usuários.
- Podemos alcançar segurança em nível de coluna, segurança em nível de linha e segurança em nível de célula.
- Uso eficaz dos recursos do formato de tabela Apache Iceberg para controle contínuo sobre os dados e seu acesso.
- Eficiência e eficácia na preparação de dados.
- Gerenciamento centralizado de acesso e governança usando a formação de lake.
- Menos intervenção manual na solução totalmente integrada.
- Entrega de dados de ponta a ponta usando solução agnóstica em nuvem e componentes serverless para oferecer escalabilidade e custo-efetividade.
Benefícios
- Eficiência operacional. O uso de componentes serverless reduz os custos operacionais e de manutenção envolvidos em seu gerenciamento.
- Otimização de esforço. Redução de até 20-30% no esforço ao usar modelos GenAI para gerar scripts de ETL padronizados e eficientes.
- Benefícios de governança e conformidade. O controle baseado em atributos na formação de lake ajuda a cumprir as regulamentações padrão e fornecer capacidades de auditoria e logging.
Uso industrial
A governança em nível de atributos usando a tabela Apache Iceberg pode ser implementada de forma muito simples no setor financeiro, como um banco ou empresa de seguros, onde os clientes precisam ter acesso restrito aos dados, garantindo a autenticidade e segurança dos dados. O setor de saúde pode utilizá-la para gerar e compartilhar o prontuário eletrônico do paciente de forma rápida, garantindo a sensibilidade dos dados, o que pode levar a um tratamento e medicação oportunos.
Conclusão
Portanto, a solução geral entregará governança em nível de atributos em escala com preparação de dados de maneira rápida usando o formato de tabela Apache Iceberg necessário para a maioria das organizações e implementando a solução aproveitando os serviços da Amazon Cloud, que oferece o benefício de vitórias rápidas, custo otimizado e escalabilidade ilimitada.
Source:
https://dzone.com/articles/attribute-level-governance-apache-iceberg-tables