













对于访问关键数据用户数量较多的大型组织来说,在管理细粒度访问权限方面会面临许多挑战。
像IAM、Lake Formation和S3 ACL等各种AWS服务可以帮助进行细粒度访问控制。但存在这样的情况,即一个包含全局数据的单个实体需要被系统中不同用户组访问,且访问受到限制。此外,全球存在的组织可能在不同环境中工作,并使用不同的工具集,因此数据移动和编目变得非常繁琐。
例如,用户想要为分析目的访问某张表中的销售数据,但他应该仅限于访问与澳大利亚地区相关的销售数据。其他数据对他不可见。此外,他想要从不同的云平台访问数据进行多个DML操作,因此需要将数据带入并将其转换为工具的本机格式以进行处理,这会导致延迟。
针对这种情况,我们需要在属性级别上对数据进行控制,并跨环境支持本机工具集格式以实现更快访问。
我们采取了一步措施来解决这些挑战,并提供了一种利用Lake Formation进行数据治理的云转型解决方案,这种解决方案可以在 AWS S3 中查询和编录 Apache Iceberg 表,并可以跨平台和云访问。
通过 Lake Formation 中的数据过滤选项,我们可以确保列级安全、行级安全和单元格级安全。
Iceberg 表格式是什么?
Iceberg 是一种开源表格格式,具有以下优点:
- Iceberg 完全支持灵活的 SQL 命令,可以更新、合并和删除数据。Iceberg 可用于重写数据文件以提高读取性能,并使用删除增量来加快更新速度。
- Iceberg 支持完整的模式演化。Iceberg 表中的模式更新仅更改元数据,不影响数据文件本身。模式演化变化包括添加、删除、重命名、重新排序和类型提升。
- 存储在数据湖或数据网格架构中的数据可以同时供组织中的多个独立应用程序访问。
- Iceberg 专为处理大型分析数据集而设计。它提供了多种功能,旨在提高查询速度和效率,包括快速扫描计划、修剪不需要的元数据文件,并过滤掉不包含匹配数据的数据文件。
解决方案概述
我们提出的解决方案是使用Lake Formation服务创建数据过滤器,对其进行权限授予给用户以进行访问。解决方案的核心是使用Iceberg表格格式,将其编目化,然后添加过滤条件以管理访问权限。

数据流
- 使用DMS或Glue从源系统存储库中提取数据,将其存储在指定的S3存储桶中。
- 基于事件的架构在S3推送数据时触发事件,调用相应的Lambda函数启动ETL过程。
- 数据将以Iceberg表格格式存储并进行编目化。
- 可以使用Glue处理和转换数据,利用GenAI现成的模型。
- 处理过的数据将存储在Redshift中供使用。
- 编目化的Iceberg表格将添加标签列(标签值映射到用户组)。
下面的图片描述了一个示例数据过滤器及其外观。我们还可以使用数据过滤器限制列的数量。
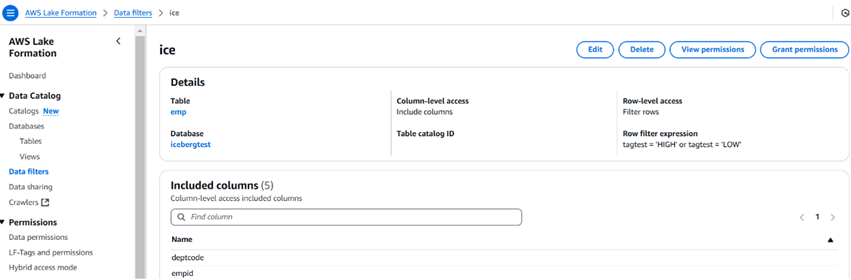
创建过滤器后,我们可以使用授予权限选项向用户、角色、组和账户授予权限。用户可以使用Athena查询数据。
我们解决方案的各种能力包括:
- 有效管理对数据的细粒度访问控制。
- 数据过滤器可重复使用于多个用户组。
- 我们可以实现列级安全、行级安全和单元格级安全。
- 有效利用Apache Iceberg表格格式功能,实现对数据及其访问的无缝控制。
- 数据准备的高效性和有效性。
- 使用lake formation进行集中访问管理和治理。
- 在完全集成的解决方案中减少手动干预。
- 使用云不可知解决方案和无服务器组件实现端到端数据交付,提供可伸缩性和成本效益。
好处
- 运营效率。使用无服务器组件降低了管理所涉及的运营和维护开销。
- 工作优化。使用GenAI模型生成标准化和高效的ETL脚本,减少了20-30%的工作量。
- 治理和合规性好处。在lake formation中的基于属性的控制有助于遵守标准法规,并提供审计和日志记录功能。
工业应用。
使用Apache Iceberg表格进行属性级治理可以在金融领域(如银行或保险公司)中得到非常无缝的实施,其中客户需要对数据进行限制访问,确保数据的真实性和安全性。医疗保健领域可以使用它快速生成和共享患者的电子健康记录,确保数据的敏感性,有助于及时治疗和用药。
结论
因此,整体解决方案将以规模化提供属性级治理,通过使用Apache Iceberg表格格式以快速的方式进行数据准备,满足大多数组织的需求,并利用亚马逊云服务实施解决方案,从而获得快速见效、最佳成本和无限可扩展性的好处。
Source:
https://dzone.com/articles/attribute-level-governance-apache-iceberg-tables