













Le grandi organizzazioni in cui il numero di utenti che accedono a dati cruciali è piuttosto elevato devono affrontare molte sfide nella gestione dell’accesso dettagliato.
Una varietà di servizi AWS comeIAM, Lake Formation e S3 ACL possono aiutare nel controllo dell’accesso dettagliato. Tuttavia, ci sono scenari in cui un’unica entità che contiene i dati globali deve essere accessibile da più gruppi di utenti in tutto il sistema con accesso limitato. Inoltre, le organizzazioni con una presenza globale potrebbero lavorare in ambienti diversi e con diversi set di strumenti, quindi lo spostamento dei dati e la catalogazione diventano molto noiosi.
Per esempio, un utente desidera accedere ai dati sulle vendite da una tabella a fini analitici, ma dovrebbe essere limitato ad accedere solo ai dati sulle vendite relativi alla regione dell’Australia. Nessun altro dato dovrebbe essere visibile per lui. Inoltre, desidera accedere ai dati da una piattaforma cloud diversa per operazioni DML multiple, quindi deve portare i dati e trasformarli nel formato nativo dello strumento per il processing, il che causa ritardi.
Per questo tipo di scenario, è necessario il controllo dei dati a livello di attributo e dei dati tra ambienti per supportare i formati degli strumenti nativi e l’accesso più rapido.
Abbiamo compiuto un passo avanti per affrontare queste sfide e offrire una soluzione di trasformazione cloud sfruttando Lake Formation per la governance dei dati su tavola Apache Iceberg, che può essere interrogata e catalogata direttamente in AWS S3 e può essere accessibile su diverse piattaforme e cloud.
Utilizzando l’opzione di filtro dati in Lake Formation, possiamo garantire la sicurezza a livello di colonna, riga e cella.
Cos’è il formato tabella Iceberg?
Iceberg è un formato tabella open-source con i seguenti vantaggi:
- Iceberg supporta pienamente comandi SQL flessibili, rendendo possibile l’aggiornamento, il merge e l’eliminazione dei dati. Iceberg può essere utilizzato per riscrivere i file di dati per migliorare le prestazioni di lettura e utilizzare delta di eliminazione per accelerare il ritmo degli aggiornamenti.
- Iceberg supporta l’evoluzione completa dello schema. Gli aggiornamenti dello schema nelle tabelle Iceberg modificano solo i metadati, lasciando i file di dati stessi inalterati. Le modifiche dell’evoluzione dello schema includono aggiunte, eliminazioni, rinominazioni, riordinamenti e promozioni di tipo.
- I dati memorizzati in un data lake o in un’architettura data mesh sono disponibili contemporaneamente a più applicazioni indipendenti all’interno di un’organizzazione.
- Iceberg è progettato per l’uso con enormi set di dati analitici. Offre molteplici funzionalità progettate per aumentare la velocità e l’efficienza delle query, inclusi la pianificazione rapida delle scansioni, la potatura dei file di metadati non necessari e la possibilità di filtrare i file di dati che non contengono dati corrispondenti.
Panoramica della Soluzione
La soluzione che abbiamo proposto consiste nell’utilizzare il servizio Lake Formation per creare filtri sui dati ai quali possiamo concedere permessi di accesso all’utente. Il cuore della soluzione è utilizzare il formato di tabella Iceberg, che è catalogato e poi arricchito con condizioni di filtro per governare l’accesso.

Flusso dei Dati
- DMS o Glue viene utilizzato per recuperare i dati dai repository del sistema sorgente per memorizzarli in un bucket S3 designato.
- L’architettura basata su eventi attiva un evento quando S3 invia una richiesta per chiamare la rispettiva funzione Lambda per avviare il processo ETL.
- I dati saranno memorizzati nel formato di tabella Iceberg e saranno catalogati.
- I dati possono essere elaborati e trasformati utilizzando Glue, sfruttando i modelli preconfezionati di GenAI.
- I dati elaborati saranno memorizzati in Redshift per il consumo.
- Le tabelle Iceberg catalogate saranno arricchite con la colonna tag (il valore del tag è mappato al gruppo utente).
L’immagine sottostante descrive un esempio di filtro dei dati e come appare. Possiamo anche limitare il numero di colonne utilizzando i filtri sui dati.
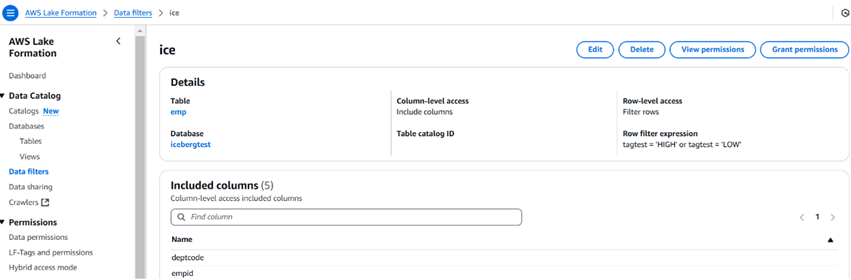
Una volta creato il filtro, possiamo quindi utilizzare l’opzione di concessione di permessi per dare accesso a utenti, ruoli, gruppi e account. L’utente può utilizzare Athena per interrogare i dati.
Le varie capacità della nostra soluzione sono:
- Capacità di gestire efficacemente il controllo dettagliato dell’accesso ai dati.
- Riusabilità dei filtri dei dati per più gruppi di utenti.
- Possiamo ottenere sicurezza a livello di colonna, a livello di riga e a livello di cella.
- Utilizzo efficace delle funzionalità del formato tabella Apache Iceberg per un controllo senza soluzione di continuità sui dati e il loro accesso.
- Efficienza ed efficacia nella preparazione dei dati.
- Gestione centralizzata dell’accesso e della governance utilizzando lake formation.
- Minor intervento manuale nella soluzione completamente integrata.
- Consegna dati end-to-end utilizzando una soluzione cloud agnostica e componenti serverless per garantire scalabilità ed economicità.
Vantaggi
- Efficienza operativa. L’utilizzo di componenti serverless riduce i costi operativi e di manutenzione associati alla gestione.
- Ottimizzazione dello sforzo. Riduzione fino al 20-30% dello sforzo utilizzando modelli GenAI per generare script ETL standardizzati ed efficienti.
- Vantaggi di governance e conformità. Il controllo basato sugli attributi in lake formation aiuta a conformarsi alle normative standard e fornisce funzionalità di audit e logging.
Utilizzo industriale
Il governo a livello di attributi tramite l’utilizzo della tabella Apache Iceberg può essere implementato in modo molto semplice nel settore finanziario, come una banca o un’azienda assicurativa, in cui i clienti devono avere accesso limitato ai dati, garantendo l’autenticità e la sicurezza dei dati. Il settore sanitario può utilizzarlo per generare e condividere rapidamente la cartella clinica elettronica del paziente, garantendo la sensibilità dei dati, il che può portare a trattamenti e cure tempestivi.
Conclusion
Pertanto, la soluzione complessiva offrirà un governo a livello di attributi su larga scala con la preparazione dei dati in modo rapido utilizzando il formato tabella Apache Iceberg necessario per la maggior parte delle organizzazioni e implementando la soluzione sfruttando i servizi cloud di Amazon, che offrono il vantaggio di vittorie rapide, costi ottimali e scalabilità illimitata.
Source:
https://dzone.com/articles/attribute-level-governance-apache-iceberg-tables