













Grote organisaties waar het aantal gebruikers dat toegang heeft tot cruciale gegevens vrij hoog is, worden geconfronteerd met veel uitdagingen bij het beheren van fijnmazige toegang.
Een verscheidenheid aan AWS-diensten zoals IAM, Lake Formation en S3 ACL kan helpen bij fijnmazige toegangscontrole. Maar er zijn scenario’s waarin een enkele entiteit met de globale gegevens door meerdere gebruikersgroepen binnen het systeem moet worden benaderd met beperkende toegang. Ook kunnen organisaties met een wereldwijde aanwezigheid in verschillende omgevingen en met verschillende toolsets werken, waardoor databeweging en catalogisering zeer tijdrovend worden.
Bijvoorbeeld, een gebruiker wil toegang krijgen tot de verkoopgegevens van een tabel voor analytische doeleinden, maar hij moet beperkt zijn tot het toegang krijgen van alleen de verkoopgegevens die verband houden met de regio Australië. Geen andere gegevens mogen voor hem zichtbaar zijn. Ook wil hij toegang krijgen tot de gegevens van een ander cloudplatform voor meerdere DML-bewerkingen, zodat hij gegevens moet halen en deze moet omzetten naar het native formaat van de tool voor verwerking, wat vertragingen veroorzaakt.
Voor dit soort scenario’s hebben we gegevenscontrole op attribuutniveau en gegevens over omgevingen nodig om de native toolsetformaten en snellere toegang te ondersteunen.
We hebben een stap voorwaarts gezet om deze uitdagingen aan te pakken en een cloudtransformatieoplossing te leveren met behulp van Lake Formation voor gegevensbeheer op een Apache Iceberg-tabel, die kan worden bevraagd en gecatalogiseerd in AWS S3 zelf en toegankelijk is over platforms en clouds.
Met de dataselectieoptie in Lake Formation kunnen we beveiliging op kolomniveau, rijniveau en celniveau garanderen.
Wat Is het Iceberg Table Format?
Iceberg is een open-source tabelindeling met de volgende voordelen:
- Iceberg ondersteunt volledig flexibele SQL-opdrachten, waardoor het mogelijk is om gegevens bij te werken, samen te voegen en te verwijderen. Iceberg kan worden gebruikt om gegevensbestanden opnieuw te schrijven om de leesprestaties te verbeteren en om verwijderingsdeltas te gebruiken om de snelheid van updates te versnellen.
- Iceberg ondersteunt volledige schemaevolutie. Schema-updates in Iceberg-tabellen veranderen alleen de metadata, zonder de gegevensbestanden zelf te beïnvloeden. Schemaevolutiewijzigingen omvatten toevoegingen, verwijderingen, hernoemingen, herordeningen en typepromoties.
- Gegevens die zijn opgeslagen in een datameer of gegevensmesh-architectuur zijn tegelijkertijd beschikbaar voor meerdere onafhankelijke applicaties binnen een organisatie.
- <ijsberg is ontworpen voor gebruik met enorme analytische gegevenssets. Het biedt meerdere functies die zijn ontworpen om de vraagsnelheid en efficiëntie te verhogen, waaronder snelle scanplanning, het snoeien van metadatabestanden die niet nodig zijn, en de mogelijkheid om gegevensbestanden te filteren die geen overeenkomende gegevens bevatten.
Oplossingsoverzicht
De oplossing die we hebben voorgesteld is om de Lake Formation-service te gebruiken om gegevensfilters te maken waarop we gebruikers toegang kunnen verlenen. Het hart van de oplossing is het gebruik van het Iceberg-tabelformaat, dat gecatalogiseerd is en vervolgens wordt toegevoegd met filtervoorwaarden om de toegang te regelen.

Gegevensstroom
- DMS of Glue wordt gebruikt om gegevens op te halen uit de bronopslagsystemen en deze op te slaan in een aangewezen S3-bucket.
- De gebeurtenisgestuurde architectuur activeert een gebeurtenis wanneer S3 wordt geduwd om de respectievelijke Lambda-functie aan te roepen om het ETL-proces te starten.
- Gegevens worden opgeslagen in Iceberg-tabelindeling en worden gecatalogiseerd.
- Gegevens kunnen worden verwerkt en getransformeerd met behulp van Glue, waarbij gebruik wordt gemaakt van de kant-en-klare GenAI-modellen.
- Verwerkte gegevens worden opgeslagen in Redshift voor consumptie.
- Gecatalogiseerde Iceberg-tabellen worden toegevoegd met de tagkolom (tagwaarde is gekoppeld aan de gebruikersgroep).
De onderstaande afbeelding beschrijft een voorbeeld van een gegevensfilter en hoe het eruitziet. We kunnen ook het aantal kolommen beperken met behulp van de gegevensfilters.
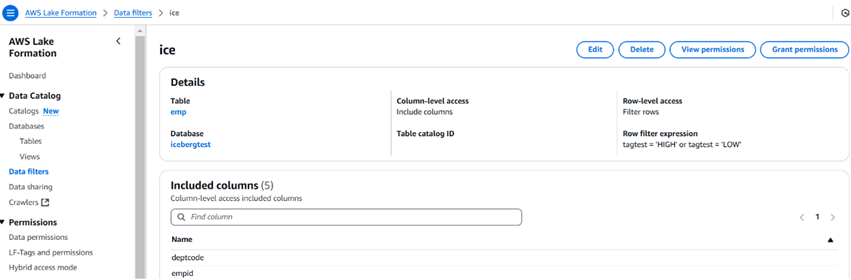
Zodra het filter is gemaakt, kunnen we vervolgens de optie machtiging verlenen gebruiken om machtigingen te geven aan gebruikers, rollen, groepen en accounts. De gebruiker kan Athena gebruiken om de gegevens te bevragen.
De verschillende mogelijkheden van onze oplossing zijn:
- Mogelijkheid om effectief het fijnmazige beheer van toegang tot de gegevens te beheren.
- Herbruikbaarheid van de gegevensfilters voor meerdere gebruikersgroepen.
- We kunnen beveiliging op kolomniveau, rij-niveau en cel-niveau bereiken.
- Effectief gebruik van de functies van het Apache Iceberg-tabelformaat voor naadloze controle over de gegevens en de toegang ertoe.
- Efficiëntie en effectiviteit bij gegevensvoorbereiding.
- Gecentraliseerd toegangsbeheer en governance met behulp van lake formation.
- Minder handmatige interventie in de volledig geïntegreerde oplossing.
- Datalevering van begin tot eind met behulp van een cloudagnostische oplossing en serverloze componenten om schaalbaarheid en kosteneffectiviteit te bieden.
Voordelen
- Operationele efficiëntie. Het gebruik van serverloze componenten vermindert de operationele en onderhoudsoverhead die ermee gepaard gaat.
- Inspanningsoptimalisatie. Tot 20-30% reductie in inspanning door het gebruik van GenAI-modellen voor het genereren van gestandaardiseerde en efficiënte ETL-scripts.
- Voordelen op het gebied van governance en compliance. Op attributen gebaseerde controle in lake formation helpt om te voldoen aan de standaard voorschriften en biedt audit- en loggingmogelijkheden.
Industrieel gebruik
Attribuutniveau governance met behulp van Apache Iceberg-tabel kan zeer naadloos worden geïmplementeerd in de financiële sector, zoals een bank of verzekeringsmaatschappij, waar klanten beperkte toegang moeten hebben tot de gegevens, waarbij de authenticiteit en veiligheid van de gegevens worden gewaarborgd. De gezondheidszorgsector kan het gebruiken om het elektronische medische dossier van de patiënt snel te genereren en te delen, waarbij de gevoeligheid van de gegevens wordt gewaarborgd, wat kan leiden tot tijdige behandeling en medicatie.
Conclusie
Dus, de algehele oplossing zal attribuutniveau governance op schaal leveren met gegevensvoorbereiding op een snelle manier met behulp van het Apache Iceberg-tabelformaat dat nodig is voor de meeste organisaties en de oplossing implementeren met behulp van Amazon Cloud-services, wat de voordelen biedt van snelle resultaten, optimale kosten en onbeperkte schaalbaarheid.
Source:
https://dzone.com/articles/attribute-level-governance-apache-iceberg-tables