













A geração aumentada por recuperação (RAG) é a abordagem mais popular para obter dados em tempo real ou dados atualizados de uma fonte de dados com base no texto inserido pelos usuários. Assim, capacitamos todas as nossas aplicações de busca com uma busca neural de última geração.
Nos sistemas de busca RAG, cada solicitação do usuário é convertida em uma representação vetorial por um modelo de incorporação, e essa comparação de vetores é realizada usando vários algoritmos, como similaridade cosseno, maior sub-sequência comum, etc., com representações vetoriais existentes armazenadas em nosso banco de dados que suporta vetores.
Os vetores existentes armazenados no banco de dados vetorial também são gerados ou atualizados de forma assíncrona por um processo de fundo separado.
 Este diagrama fornece uma visão conceitual da comparação de vetores
Este diagrama fornece uma visão conceitual da comparação de vetores
Para usar RAG, precisamos de pelo menos um modelo de incorporação e um banco de dados de armazenamento vetorial a ser utilizado pela aplicação. As contribuições da comunidade e de projetos de código aberto nos fornecem um conjunto incrível de ferramentas que nos ajudam a construir aplicações RAG eficazes e eficientes.
Neste artigo, implementaremos o uso de um banco de dados vetorial e um modelo de geração de embeddings em uma aplicação Python. Se você está lendo este conceito pela primeira vez ou pela enésima vez, você só precisa de ferramentas para trabalhar, e nenhuma assinatura é necessária para qualquer ferramenta. Você pode simplesmente baixar as ferramentas e começar.
Nossa pilha de tecnologia consiste nas seguintes ferramentas de código aberto e gratuitas:
- Sistema operacional – Ubuntu Linux
- Banco de dados vetorial – Apache Cassandra
- Modelo de embedding – nomic-embed-text
- Linguagem de programação – Python
Principais Benefícios desta Pilha
- Código aberto
- Dado isolado para atender aos padrões de conformidade de dados
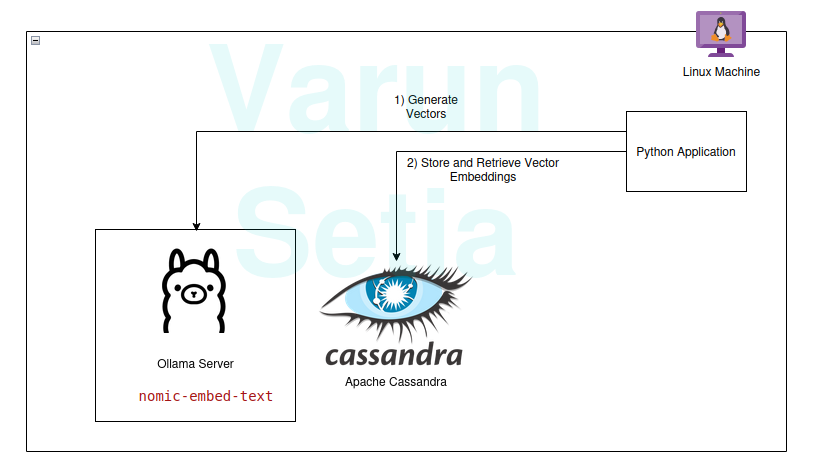
Passo a Passo da Implementação
Você pode implementar e acompanhar se os pré-requisitos forem cumpridos; caso contrário, leia até o final para entender os conceitos.
Pré-requisitos
- Linux (No meu caso, é Ubuntu 24.04.1 LTS)
- Configuração do Java (OpenJDK 17.0.2)
- Python (3.11.11)
- Ollama
Configuração do Modelo Ollama
Ollama é um servidor middleware de código aberto que atua como uma abstração entre a IA generativa e aplicações, instalando todas as ferramentas necessárias para tornar os modelos de IA generativa disponíveis para consumo como CLI e API em uma máquina. Ele possui a maioria dos modelos disponíveis publicamente, como llama, phi, mistral, snowflake-arctic-embed, etc. É multiplataforma e pode ser facilmente configurado em sistemas operacionais.
No Ollama, vamos puxar o nomic-embed-text modelo para gerar embeddings.
Execute no terminal:
ollama pull nomic-embed-text
Este modelo gera embeddings de tamanho 768 vetores.
Configuração e Scripts do Apache Cassandra
O Cassandra é um banco de dados NoSQL de código aberto projetado para lidar com uma alta quantidade de cargas de trabalho que requerem alta escalabilidade conforme as necessidades da indústria. Recentemente, ele adicionou suporte para busca vetorial na versão 5.0, que facilitará nosso caso de uso de RAG.
Nota: O Cassandra requer o sistema operacional Linux para funcionar; ele também pode ser instalado como uma imagem docker.
Instalação
Baixe o Apache Cassandra em https://cassandra.apache.org/_/download.html.
Configure o Cassandra no seu PATH.
Inicie o servidor executando o seguinte comando no terminal:
cassandra
Tabela
Abra um novo terminal Linux e escreva cqlsh; isso abrirá o shell para a Linguagem de Consulta Cassandra. Agora, execute os scripts abaixo para criar o keyspace embeddings, a tabela document_vectors e o índice necessário edv_ann_index para realizar uma pesquisa de vetor.
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';
Nota: content_vector VECTOR <FLOAT, 768> é responsável por armazenar vetores de comprimento 768 gerados pelo modelo.
Marco 1: Estamos prontos com a configuração do banco de dados para armazenar vetores.
Código Python
Esta linguagem de programação certamente não precisa de introdução; é fácil de usar e amada pela indústria com forte suporte da comunidade.
Ambiente Virtual
Configure o ambiente virtual:
sudo apt install python3-virtualenv && python3 -m venv myvenv
Ative o ambiente virtual:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activate
Pacotes
Baixe o pacote Datastax Cassandra:
pip install cassandra-driver
Baixe o pacote requests:
pip install requests
Arquivo
Crie um arquivo chamado app.py.
Agora, escreva o código abaixo para inserir documentos de exemplo no Cassandra. Este é sempre o primeiro passo para inserir dados no banco de dados; pode ser feito por um processo separado de forma assíncrona. Para fins de demonstração, escrevi um método que irá inserir os documentos primeiro no banco de dados. Mais tarde, podemos comentar este método uma vez que a inserção dos documentos for bem-sucedida.
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
Agora, execute este arquivo usando o comando na linha de comando no ambiente virtual:
python app.py
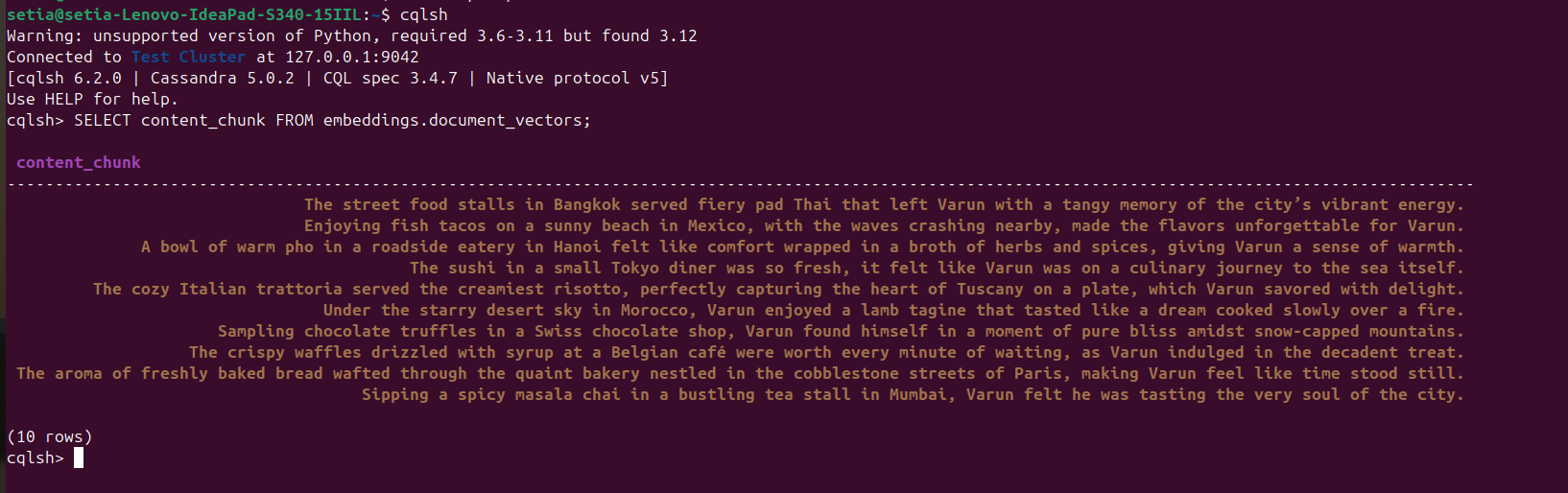
Depois que o arquivo for executado e os documentos forem inseridos, isso pode ser verificado consultando o banco de dados Cassandra a partir do console cqlsh. Para isso, abra cqlsh e execute:
SELECT content_chunk FROM embeddings.document_vectors;
Isso retornará 10 documentos inseridos no banco de dados, como visto na captura de tela abaixo.
Marco 2: Concluímos a configuração de dados em nosso banco de dados de vetores.
Agora, vamos escrever código para consultar documentos com base na similaridade de cosseno. A similaridade de cosseno é o produto escalar de dois valores de vetor. Sua fórmula é A.B / |A||B|. Essa similaridade de cosseno é suportada internamente pelo Apache Cassandra, nos ajudando a calcular tudo no banco de dados e lidar eficientemente com grandes volumes de dados.
O código abaixo é autoexplicativo; ele busca os três principais resultados com base na similaridade de cosseno usando ORDER BY <nome da coluna> ANN OF <text_vector> e também retorna os valores de similaridade de cosseno. Para executar este código, precisamos garantir que a indexação seja aplicada a esta coluna de vetor.
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')
Lembre-se de comentar o código de inserção:
#insert_sample_data_in_cassandra()
Agora, execute o código Python usando python app.py.
Obteremos a saída abaixo:
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204
Você pode ver que a similaridade de cosseno de “As barracas de comida de rua em Bangkok serviam um pad Thai ardente que deixou Varun com uma memória picante da energia vibrante da cidade.” é 0,8205469250679016, que é a correspondência mais próxima.
Marco Final: Implementamos a pesquisa RAG.
Aplicações Empresariais
Apache Cassandra
Para empresas, podemos usar Apache Cassandra 5.0 de provedores de nuvem populares como Microsoft Azure, AWS, GCP, etc.
Ollama
Este middleware requer uma VM compatível com GPU da Nvidia para executar modelos de alto desempenho, mas não precisamos de VMs de alto nível para modelos usados para gerar vetores. Dependendo das necessidades de tráfego, várias VMs podem ser usadas, ou qualquer serviço de IA generativa como Open AI, Anthropy, etc., dependendo de qual Custo Total de Propriedade é menor para as necessidades de escalabilidade ou de Governança de Dados.
VM Linux
Apache Cassandra e Ollama podem ser combinados e hospedados em uma única VM Linux se o caso de uso não exigir alto uso para reduzir o Custo Total de Propriedade ou para atender às necessidades de Governança de Dados.
Conclusão
Podemos facilmente construir aplicações RAG usando o sistema operacional Linux, Apache Cassandra, modelos embutidos (nomic-embed-text) utilizados via Ollama, e Python com bom desempenho sem precisar de nenhuma assinatura ou serviços adicionais de nuvem no conforto de nossas máquinas/servidores.
No entanto, é recomendável hospedar uma VM em servidor(es) ou optar por uma assinatura em nuvem para escalabilidade como uma aplicação empresarial compatível com arquiteturas escaláveis. Neste Apache, o Cassandra é um componente chave para realizar o trabalho pesado do nosso armazenamento de vetores e comparação de vetores, e o servidor Ollama para gerar embeddings de vetores.
É isso! Obrigado por ler até o final.
Source:
https://dzone.com/articles/build-rag-apps-apache-cassandra-python-ollama