













Het ophalen-verrijkte generatie (RAG) is de meest populaire aanpak om real-time gegevens of bijgewerkte gegevens van een gegevensbron te verkrijgen op basis van tekstinvoer door gebruikers. Hiermee worden al onze zoektoepassingen voorzien van toonaangevende neurale zoektechnologie.
In RAG-zoeksystemen wordt elke gebruikersaanvraag omgezet in een vectorrepresentatie door een inbeddingsmodel, en deze vectorvergelijking wordt uitgevoerd met verschillende algoritmen zoals cosinusgelijkenis, langste gemeenschappelijke deelreeks, enz., met bestaande vectorrepresentaties die zijn opgeslagen in onze vectorondersteunende database.
De bestaande vectoren die zijn opgeslagen in de vectordatabase worden ook gegenereerd of bijgewerkt asynchroon door een afzonderlijk achtergrondproces.
 Deze diagram biedt een conceptueel overzicht van vectorvergelijking
Deze diagram biedt een conceptueel overzicht van vectorvergelijking
Om RAG te gebruiken, hebben we minimaal een inbeddingsmodel en een vectoropslagdatabase nodig die door de toepassing wordt gebruikt. Bijdragen van de gemeenschap en open-source projecten voorzien ons van een geweldige set tools die ons helpen effectieve en efficiënte RAG-toepassingen op te bouwen.
In dit artikel zullen we het gebruik van een vector database en een embedding-generatiemodel implementeren in een Python-toepassing. Als je dit concept voor de eerste keer of voor de zoveelste keer leest, heb je alleen gereedschappen nodig om te werken en is er geen abonnement nodig voor enig gereedschap. Je kunt eenvoudig gereedschappen downloaden en aan de slag gaan.
Onze technologiestack bestaat uit de volgende open-source en gratis te gebruiken tools:
- Besturingssysteem – Ubuntu Linux
- Vector database – Apache Cassandra
- Embedding-model – nomic-embed-text
- Programmeertaal – Python
Belangrijkste voordelen van deze stack
- Open-source
- Geïsoleerde gegevens om te voldoen aan gegevensconformiteitsnormen
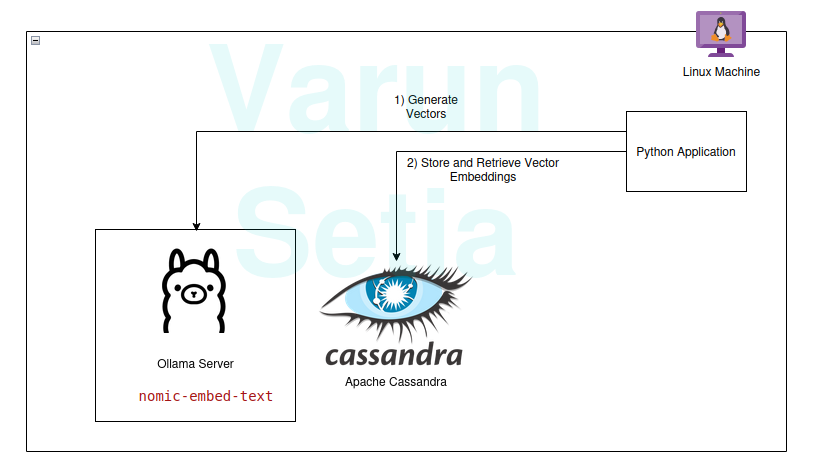
Implementatiewalkthrough
Je kunt implementeren en meevolgen als aan de vereisten is voldaan; anders lees je tot het einde om de concepten te begrijpen.
Vereisten
- Linux (In mijn geval is het Ubuntu 24.04.1 LTS)
- Java-instellingen (OpenJDK 17.0.2)
- Python (3.11.11)
- Ollama
Ollama Model-instellingen
Ollama is een open-source middleware server die fungeert als een abstractie tussen generatieve AI en applicaties door alle nodige tools te installeren om generatieve AI-modellen beschikbaar te maken voor gebruik als CLI en API op een machine. Het heeft de meeste openlijk beschikbare modellen zoals llama, phi, mistral, snowflake-arctic-embed, enz. Het is platformonafhankelijk en kan eenvoudig worden geconfigureerd in het besturingssysteem.
In Ollama zullen we het nomic-embed-text model ophalen om embeddings te genereren.
Voer in de opdrachtregel uit:
ollama pull nomic-embed-text
Dit model genereert embeddings van grootte 768 vectoren.
Apache Cassandra Setup en Scripts
Cassandra is een open-source NoSQL-database die is ontworpen om te werken met een hoge hoeveelheid werkbelastingen die hoge schaal vereisen volgens de behoeften van de industrie. Onlangs heeft het ondersteuning toegevoegd voor Vector-zoek in versie 5.0, wat ons RAG-geval zal vergemakkelijken.
Opmerking: Cassandra vereist een Linux-besturingssysteem om te werken; het kan ook worden geïnstalleerd als een docker-image.
Installatie
Download Apache Cassandra van https://cassandra.apache.org/_/download.html.
Configureer Cassandra in uw PATH.
Start de server door de volgende opdracht in de opdrachtregel uit te voeren:
cassandra
Tabel
Open een nieuwe Linux-terminal en schrijf cqlsh; dit zal de shell openen voor de Cassandra Query Language. Voer nu de onderstaande scripts uit om het embeddings keyspace, de document_vectors tabel en de nodige index edv_ann_index aan te maken om een vectorzoekopdracht uit te voeren.
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';
Let op: content_vector VECTOR <FLOAT, 768> is verantwoordelijk voor het opslaan van vectoren van lengte 768 die zijn gegenereerd door het model.
Mijlpaal 1: We zijn klaar met de database-instelling om vectoren op te slaan.
Python Code
Deze programmeertaal heeft zeker geen introductie nodig; het is eenvoudig te gebruiken en geliefd bij de industrie met sterke communityondersteuning.
Virtual Environment
Stel de virtuele omgeving in:
sudo apt install python3-virtualenv && python3 -m venv myvenv
Activeer de virtuele omgeving:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activate
Pakketten
Download het Datastax Cassandra-pakket:
pip install cassandra-driver
Download het requests-pakket:
pip install requests
Bestand
Maak een bestand genaamd app.py.
Schrijf nu de onderstaande code om voorbeelddocumenten in Cassandra in te voegen. Dit is altijd de eerste stap om gegevens in de database in te voegen; dit kan apart worden gedaan door een afzonderlijk proces asynchroon uit te voeren. Voor demodoeleinden heb ik een methode geschreven die eerst documenten in de database zal invoegen. Later kunnen we op deze methode commentaar geven zodra de invoeging van documenten succesvol is.
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
Voer nu dit bestand uit met de opdrachtregel in de virtuele omgeving:
python app.py
Zodra het bestand is uitgevoerd en documenten zijn ingevoegd, kan dit worden geverifieerd door een query uit te voeren op de Cassandra-database vanuit de cqlsh-console. Hiervoor opent u cqlsh en voert u het volgende uit:
SELECT content_chunk FROM embeddings.document_vectors;
Dit zal 10 ingevoegde documenten in de database retourneren, zoals te zien is in de onderstaande schermafbeelding.
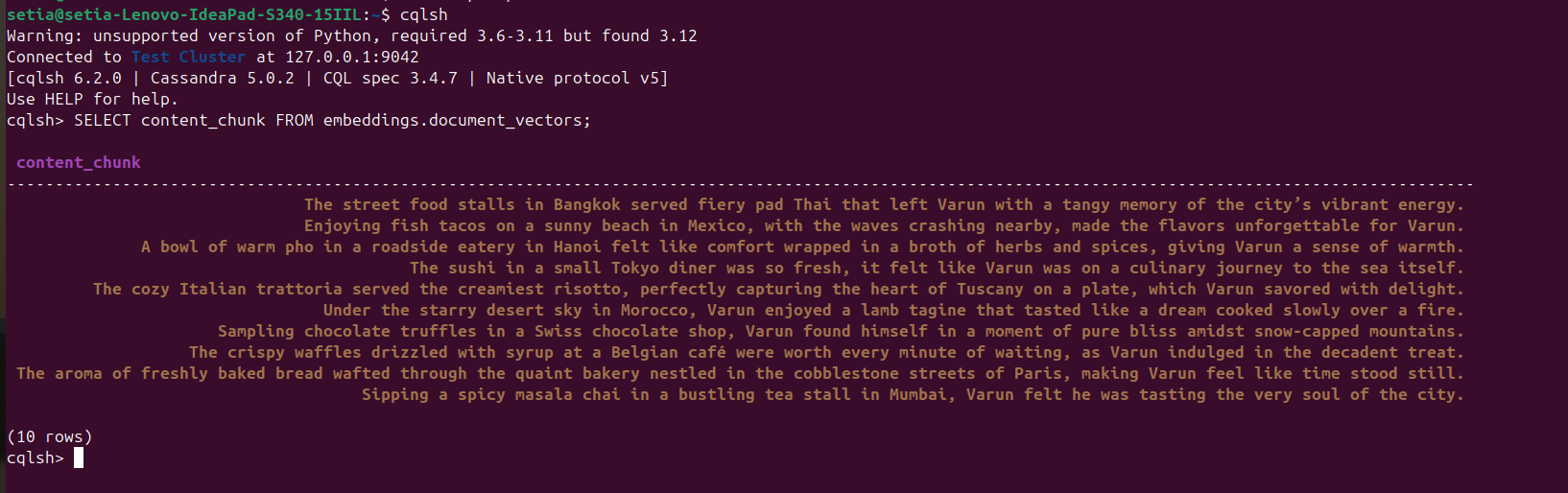
Mijlpaal 2: We zijn klaar met de gegevensinstelling in onze vector database.
Nu zullen we code schrijven om documenten op te vragen op basis van cosinusgelijkenis. Cosinusgelijkenis is het inwendig product van twee vectorwaarden. De formule is A.B / |A||B|. Deze cosinusgelijkenis wordt intern ondersteund door Apache Cassandra, waardoor we alles in de database kunnen berekenen en grote gegevens efficiënt kunnen verwerken.
De onderstaande code is zelfverklarend; het haalt de top drie resultaten op basis van cosinusgelijkenis op met behulp van ORDER BY <kolomnaam> ANN OF <tekst_vector> en retourneert ook cosinusgelijkeniswaarden. Om deze code uit te voeren, moeten we ervoor zorgen dat er indexering wordt toegepast op deze vector kolom.
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')
Vergeet niet om de invoegcode te commentariëren:
#insert_sample_data_in_cassandra()
Voer nu de Python-code uit door python app.py te gebruiken.
We zullen de onderstaande uitvoer krijgen:
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204
U kunt de cosinusgelijkenis zien van “De straatvoedselstalletjes in Bangkok serveerden vurige pad Thai die Varun achterlieten met een pittige herinnering aan de levendige energie van de stad.” is 0.8205469250679016, wat de dichtstbijzijnde overeenkomst is.
Laatste mijlpaal: We hebben de RAG-zoekopdracht geïmplementeerd.
Enterprise-toepassingen
Apache Cassandra
Voor bedrijven kunnen we Apache Cassandra 5.0 gebruiken van populaire cloud leveranciers zoals Microsoft Azure, AWS, GCP, enz.
Ollama
Deze middleware vereist een VM die compatibel is met een Nvidia-aangedreven GPU voor het uitvoeren van high-performance modellen, maar we hebben geen high-end VM’s nodig voor modellen die worden gebruikt voor het genereren van vectoren. Afhankelijk van de verkeerseisen kunnen meerdere VM’s worden gebruikt, of een generatieve AI-service zoals Open AI, Anthropy, enz., waarvan de Totale Kosten van Eigendom lager zijn voor schaalbehoeften of Data Governance behoeften.
Linux VM
Apache Cassandra en Ollama kunnen worden gecombineerd en gehost in een enkele Linux VM als de use case geen hoog gebruik vereist om de Totale Kosten van Eigendom te verlagen of om te voldoen aan Data Governance behoeften.
Conclusie
We kunnen eenvoudig RAG-toepassingen bouwen door gebruik te maken van Linux OS, Apache Cassandra, embedding modellen (nomic-embed-text) die via Ollama worden gebruikt, en Python met goede prestaties zonder dat er extra cloudabonnementen of -services nodig zijn, in het comfort van onze machines/servers.
Het is echter aan te raden om een VM te hosten op server(s) of te kiezen voor een cloudabonnement voor schaalvergroting als een bedrijfsapplicatie die voldoet aan schaalbare architecturen. In deze Apache is Cassandra een belangrijke component voor het zware werk van onze vectoropslag en vectorvergelijking, en de Ollama-server voor het genereren van vectorembeddings.
Dat is het! Bedankt voor het lezen tot het einde.
Source:
https://dzone.com/articles/build-rag-apps-apache-cassandra-python-ollama