













소개
머신 러닝은 인공 지능(AI)의 하위 분야입니다. 머신 러닝의 일반적인 목표는 데이터의 구조를 이해하고 그 데이터를 사람들이 이해하고 활용할 수 있는 모델에 맞추는 것입니다.
머신 러닝은 컴퓨터 과학의 하위 분야이지만 전통적인 계산 접근 방식과는 다릅니다. 전통적인 컴퓨팅에서 알고리즘은 컴퓨터가 계산하거나 문제를 해결하는 데 사용되는 명시적으로 프로그래밍된 명령어 세트입니다. 그러나 머신 러닝 알고리즘은 대신 데이터 입력에 대해 컴퓨터를 훈련시키고 통계 분석을 사용하여 특정 범위 내의 값 출력을 가능하게 합니다. 따라서 머신 러닝은 컴퓨터가 샘플 데이터에서 모델을 구축하여 데이터 입력을 기반으로 한 의사 결정 프로세스를 자동화하는 데 도움이 됩니다.
오늘날 어떤 기술 사용자도 머신 러닝의 혜택을 받고 있습니다. 얼굴 인식 기술을 사용하면 소셜 미디어 플랫폼이 사용자가 친구의 사진에 태그를 달고 공유하는 데 도움을 줍니다. 광학 문자 인식(OCR) 기술은 텍스트 이미지를 이동 가능한 형태로 변환합니다. 머신 러닝을 통해 작동하는 추천 엔진은 사용자 선호도를 기반으로 다음에 무슨 영화나 텔레비전 프로그램을 시청할지 제안합니다. 머신 러닝을 활용하여 내비게이션하는 자율 주행 자동차가 곧 소비자에게 제공될 수도 있습니다.
기계 학습은 지속적으로 발전하는 분야입니다. 따라서 기계 학습 방법론을 사용하거나 기계 학습 프로세스의 영향을 분석할 때 고려해야 할 사항이 있습니다.
이 튜토리얼에서는 지도 및 비지도 학습의 일반적인 기계 학습 방법과 k-최근접 이웃 알고리즘, 결정 트리 학습, 그리고 심층 학습을 포함한 기계 학습의 일반적인 알고리즘 접근 방식을 살펴보겠습니다. 기계 학습에서 가장 많이 사용되는 프로그래밍 언어와 각각의 긍정적 및 부정적 특성을 제공합니다. 또한 기계 학습 알고리즘으로 유지되는 편견에 대해 논의하고 알고리즘을 구축할 때 이러한 편견을 방지하기 위해 고려해야 할 사항을 고려하겠습니다.
기계 학습 방법
기계 학습에서 작업은 일반적으로 넓은 범주로 분류됩니다. 이러한 범주는 학습이 어떻게 이루어지는지 또는 학습에 대한 피드백이 개발된 시스템에 어떻게 주어지는지에 따라 기반됩니다.
가장 널리 사용되는 두 가지 기계 학습 방법은 지도 학습(supervised learning)으로서 인간이 레이블을 지정한 예제 입력 및 출력 데이터를 기반으로 알고리즘을 훈련시키며, 비지도 학습(unsupervised learning)으로서 레이블이 지정되지 않은 데이터를 알고리즘에 제공하여 입력 데이터 내의 구조를 찾도록 합니다. 이러한 방법을 자세히 살펴보겠습니다.
지도 학습
지도 학습에서 컴퓨터는 레이블이 지정된 예제 입력을 제공받습니다. 이 방법의 목적은 알고리즘이 실제 출력을 ‘가르쳐진’ 출력과 비교하여 오류를 찾고 모델을 수정하여 ‘학습’할 수 있도록 하는 것입니다. 따라서 지도 학습은 패턴을 사용하여 추가적인 레이블이 지정되지 않은 데이터에서 레이블 값을 예측합니다.
예를 들어, 지도 학습을 사용하여 알고리즘이 상어 이미지를 ‘물고기’로 레이블링하고 해양 이미지를 ‘물’로 레이블링된 데이터를 제공할 수 있습니다. 이러한 데이터로 훈련된 지도 학습 알고리즘은 나중에 레이블이 지정되지 않은 상어 이미지를 ‘물고기’로, 레이블이 지정되지 않은 해양 이미지를 ‘물’로 식별할 수 있어야 합니다.
A common use case of supervised learning is to use historical data to predict statistically likely future events. It may use historical stock market information to anticipate upcoming fluctuations, or be employed to filter out spam emails. In supervised learning, tagged photos of dogs can be used as input data to classify untagged photos of dogs.
비지도 학습
비지도 학습에서는 데이터에 레이블이 지정되어 있지 않으므로 학습 알고리즘이 입력 데이터 간의 공통점을 찾아야 합니다. 레이블이 지정되지 않은 데이터가 레이블이 지정된 데이터보다 풍부하기 때문에 비지도 학습을 용이하게 하는 머신러닝 방법은 특히 가치가 있습니다.
비지도 학습의 목표는 데이터 세트 내의 숨겨진 패턴을 발견하는 것일 수 있지만, 특징 학습의 목표로도 사용될 수 있으며, 이는 계산 기계가 원시 데이터를 분류하기 위해 필요한 표현을 자동으로 발견할 수 있게 합니다.
비지도 학습은 일반적으로 거래 데이터에 사용됩니다. 고객과 그들의 구매에 대한 큰 데이터 세트를 가질 수 있지만, 인간으로서는 고객 프로필과 그들의 구매 유형에서 어떤 유사한 속성을 도출할 수 없을 것입니다. 이 데이터가 비지도 학습 알고리즘에 공급되면 특정 연령대의 여성이 무향 비누를 구입하는 것으로 판명될 수 있으며, 따라서 임신과 아기 제품과 관련된 마케팅 캠페인을 이 대상에게 타겟팅하여 그들의 구매 수를 증가시킬 수 있습니다.
“정확한” 답변을 알려주지 않고도 비지도 학습 방법은 잠재적으로 의미 있는 방식으로 복잡하고 보다 넓고 상관없는 데이터를 조직화하기 위해 복잡한 데이터를 살펴볼 수 있습니다. 비지도 학습은 보통 사기 신용카드 거래를 포함한 이상 탐지 및 다음에 무엇을 구매할지 권장하는 추천 시스템과 같은 용도로 사용됩니다. 비지도 학습에서는 개의 태그가 없는 사진을 입력 데이터로 사용하여 알고리즘이 유사성을 찾고 개 사진을 함께 분류할 수 있습니다.
접근 방법
기계 학습 분야는 계산 통계와 밀접한 관련이 있으므로 통계에 대한 배경 지식을 갖는 것은 기계 학습 알고리즘을 이해하고 활용하는 데 유용합니다.
통계를 공부하지 않은 사람들에게는 먼저 상관 관계와 회귀를 정의하는 것이 도움이 될 수 있습니다. 이것들은 양적 변수 간의 관계를 조사하는 데 자주 사용되는 기술입니다. 상관 관계는 종속 변수나 독립 변수로 지정되지 않은 두 변수 간의 관련을 측정하는 것입니다. 회귀는 기본적으로 하나의 종속 변수와 하나의 독립 변수 간의 관계를 조사하는 데 사용됩니다. 회귀 통계를 사용하면 독립 변수가 알려진 경우 종속 변수를 예측할 수 있으므로 회귀는 예측 기능을 가능하게 합니다.
기계 학습 접근 방식은 지속적으로 발전하고 있습니다. 여기서는 쓰고 있는 시점에서 기계 학습에서 사용되는 몇 가지 인기 있는 접근 방식을 살펴보겠습니다.
k-nearest neighbor
k-최근접 이웃 알고리즘은 분류 및 회귀에 사용할 수 있는 패턴 인식 모델입니다. k-NN으로 약어되는 k-최근접 이웃에서의 k는 일반적으로 작은 양의 정수입니다. 분류 또는 회귀에서 입력은 공간 내에서 k개의 가장 가까운 훈련 예제로 구성됩니다.
우리는 k-NN 분류에 중점을 둘 것입니다. 이 방법에서 출력은 클래스 소속입니다. 이것은 새로운 객체를 그 k개의 가장 가까운 이웃 중 가장 일반적인 클래스에 할당합니다. k = 1인 경우에는 객체가 가장 가까운 단일 이웃의 클래스에 할당됩니다.
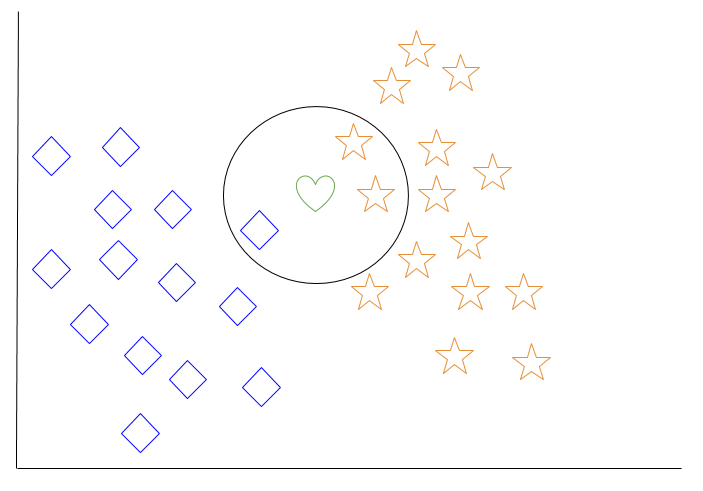
아래 다이어그램을 살펴보면 파란색 다이아몬드 객체와 주황색 별 모양 객체가 있습니다. 이들은 두 개의 별개 클래스에 속합니다: 다이아몬드 클래스와 별 클래스.

새로운 객체가 공간에 추가될 때 – 이 경우에는 녹색 하트 – 기계 학습 알고리즘에서는 하트를 특정 클래스에 분류하길 원할 것입니다.

k = 3으로 선택하면 알고리즘은 하트의 세 개의 가장 가까운 이웃을 찾아서 그것을 다이아몬드 클래스 또는 별 클래스 중 하나로 분류할 것입니다.
우리의 다이어그램에서 녹색 하트의 세 개의 가장 가까운 이웃은 하나의 다이아몬드와 두 개의 별입니다. 따라서 알고리즘은 하트를 별 클래스로 분류할 것입니다.
머신러닝 알고리즘 중 가장 기본적인 것 중 하나인 k-최근접 이웃은 “게으른 학습”의 유형으로 간주됩니다. 훈련 데이터를 벗어나는 일반화는 쿼리가 시스템에 제출될 때까지 발생하지 않습니다.
의사 결정 트리 학습
일반적으로, 결정 트리는 결정을 시각적으로 나타내고 의사 결정을 보여주거나 결정을 내릴 때 사용됩니다. 머신러닝과 데이터 마이닝에서는 결정 트리를 예측 모델로 사용합니다. 이러한 모델은 데이터에 대한 관측값을 데이터의 대상 값에 대한 결론으로 매핑합니다.
결정 트리 학습의 목표는 입력 변수를 기반으로 대상 값의 값을 예측하는 모델을 만드는 것입니다.
예측 모델에서는 관찰을 통해 결정된 데이터 속성이 가지로 나타나며, 데이터의 대상 값에 대한 결론은 잎에 나타납니다.
나무를 “학습”할 때 소스 데이터는 속성 값 테스트를 기반으로 하위 집합으로 나뉘며, 이는 파생된 각 하위 집합에서 재귀적으로 반복됩니다. 노드의 하위 집합이 대상 값과 동등한 값을 가질 때 재귀 프로세스가 완료됩니다.
어떤 사람이 낚시를 가야 할지 여부를 결정할 수 있는 다양한 조건의 예를 살펴 보겠습니다. 이에는 날씨 조건과 기압 조건이 포함됩니다.
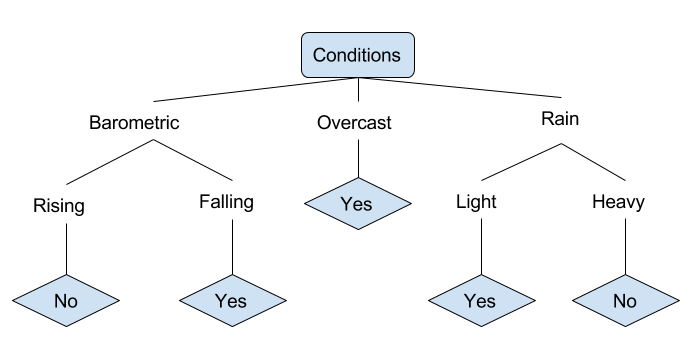
위의 간소화된 의사 결정 트리에서는 예를 들어 트리를 통해 해당 잎 노드로 분류하여 정렬됩니다. 이후 해당 잎에 연관된 분류를 반환하며, 이 경우에는 예 또는 아니오입니다. 이 트리는 낚시에 적합한지 여부에 따라 하루의 상황을 분류합니다.
A true classification tree data set would have a lot more features than what is outlined above, but relationships should be straightforward to determine. When working with decision tree learning, several determinations need to be made, including what features to choose, what conditions to use for splitting, and understanding when the decision tree has reached a clear ending.
심층 학습
심층 학습은 인간의 뇌가 빛과 소리 자극을 시각과 청각으로 처리하는 방식을 모방하려고 합니다. 심층 학습 아키텍처는 생물학적 신경망에서 영감을 받아 하드웨어와 GPU로 구성된 인공 신경망의 여러 층으로 구성됩니다.
심층 학습은 데이터의 특징(또는 표현)을 추출하거나 변환하기 위해 비선형 처리 단위 계층의 연속을 사용합니다. 한 계층의 출력은 다음 계층의 입력으로 사용됩니다. 심층 학습에서 알고리즘은 데이터를 분류하기 위한 지도 학습이 될 수도 있고, 패턴 분석을 수행하는 비지도 학습이 될 수도 있습니다.
현재 사용되고 개발 중인 머신러닝 알고리즘 중에서, 심층 학습이 가장 많은 데이터를 흡수하고 일부 인지 작업에서 인간을 이기는 데 성공했습니다. 이러한 특성으로 인해 심층 학습은 인공 지능 분야에서 상당한 잠재력을 가진 접근 방식이 되었습니다
컴퓨터 비전과 음성 인식은 모두 심층 학습 접근법에서 상당한 발전을 이루었습니다. IBM 워튼은 심층 학습을 활용하는 시스템의 잘 알려진 예입니다.
프로그래밍 언어
머신러닝에 특화된 언어를 선택할 때는 현재 구인 광고에 나열된 기술과 머신러닝 프로세스에 사용할 수 있는 다양한 언어의 라이브러리를 고려해야 할 수도 있습니다.
Python은 많은 프레임워크, TensorFlow, PyTorch, 그리고 Keras를 포함한 다양한 프레임워크들로 기계 학습 작업을 수행하는 데 가장 인기있는 언어 중 하나입니다. 가독성이 뛰어나며 스크립팅 언어로 사용할 수 있는 Python은 데이터 전처리 및 데이터 직접 작업에 모두 강력하고 직관적입니다. scikit-learn 기계 학습 라이브러리는 이미 익숙한 Python 개발자들이 이미 알고있는 NumPy, SciPy, 그리고 Matplotlib을 기반으로 구축되었습니다.
Python으로 시작하려면 “Python 3에서 코드를 작성하는 방법” 시리즈 또는 “scikit-learn으로 Python에서 기계 학습 분류기를 작성하는 방법” 또는 “Python 3와 PyTorch를 사용한 신경 스타일 전이 수행 방법”에 대한 자습서 시리즈를 읽어보십시오.
자바는 기업 프로그래밍에서 널리 사용되며, 일반적으로 기업 수준의 머신러닝을 수행하는 프런트엔드 데스크톱 응용 프로그램 개발자들에 의해 사용됩니다. 일반적으로 프로그래밍에 새로운 사람들에게는 머신러닝에 대해 배우고 싶어하는 경우 첫 번째 선택은 아니지만, 자바 개발 경험이 있는 사람들에게는 머신러닝에 적용하기 위해 선호됩니다. 산업에서의 머신러닝 응용 프로그램 측면에서, 자바는 네트워크 보안을 위해 파이썬보다 더 많이 사용되는 편입니다. 이는 사이버 공격 및 사기 탐지와 같은 경우를 포함합니다.
자바용 머신러닝 라이브러리 중에는 Deeplearning4j가 있습니다. 이는 자바와 스칼라 모두를 위해 작성된 오픈 소스 및 분산 딥 러닝 라이브러리입니다; MALLET (MAchine Learning for LanguagE Toolkit)는 텍스트를 위한 머신 러닝 응용 프로그램을 가능하게 합니다. 이는 자연어 처리, 주제 모델링, 문서 분류 및 클러스터링을 포함합니다; 그리고 Weka는 데이터 마이닝 작업에 사용할 머신 러닝 알고리즘 모음입니다.
C++ is the language of choice for machine learning and artificial intelligence in game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language. Some machine learning libraries you can use with C++ include the scalable mlpack, Dlib offering wide-ranging machine learning algorithms, and the modular and open-source Shark.
인간의 편견
데이터 및 계산 분석은 우리에게 객관적인 정보를 받고 있다고 생각하게 만들 수 있지만, 실제로는 아닙니다. 데이터에 기반한 것이라고 해서 기계 학습 결과물이 중립적이라는 뜻은 아닙니다. 인간의 편견은 데이터 수집, 정리 방법에 영향을 미치며, 궁극적으로는 기계 학습이 그 데이터와 상호 작용하는 방법을 결정하는 알고리즘에도 영향을 줍니다.
예를 들어, 사람들이 “물고기”에 대한 이미지를 데이터로 제공하고 이들이 압도적으로 금붕어의 이미지를 선택하는 경우, 컴퓨터는 상어를 물고기로 분류하지 않을 수 있습니다. 이로 인해 상어가 물고기로서 인식되지 않을 수 있습니다.
과거의 과학자 사진을 훈련 데이터로 사용할 때, 컴퓨터는 피부색이나 여성인 과학자를 제대로 분류하지 못할 수 있습니다. 실제로 최근의 피어 리뷰 논문에 따르면, 인공지능 및 기계 학습 프로그램은 인종 및 성별 편견을 포함한 인간과 유사한 편향을 보인다는 것이 밝혀졌습니다. 예를 들어 “언어 말뭉치에서 자동으로 유도된 의미” 및 “말뭉치 수준의 제약을 사용하여 성별 편견 증폭 감소” [PDF]를 참조하십시오.
기계 학습이 비즈니스에서 점점 더 활용됨에 따라 감지되지 않은 편향은 대출 자격을 얻는 것을 방해하거나, 고임급 직업 기회에 대한 광고를 보여주지 않거나, 당일 배송 옵션을 받지 못하게 함으로써 체계적인 문제를 계속해서 유발할 수 있습니다.
인간의 편견이 다른 사람들에게 부정적인 영향을 미칠 수 있기 때문에, 그것을 인식하고 최대한 없애려는 노력이 매우 중요합니다. 이를 달성하기 위한 한 가지 방법은 프로젝트에 다양한 사람들이 참여하도록 보장하고, 다양한 사람들이 테스트하고 검토하도록 하는 것입니다. 다른 사람들은 규제 기관이 알고리즘을 모니터링하고 감사하는 것을 요구하기도 했으며, 편견을 감지할 수 있는 대안 시스템을 구축하기도 했으며, 데이터 과학 프로젝트 계획의 일부로 윤리 검토를 실시하기도 했습니다. 편견에 대한 인식을 높이고, 우리 자신의 무의식적인 편견을 숙고하며, 기계 학습 프로젝트와 파이프라인에서 공정성을 구축하는 것은 이 분야에서 편견을 극복하는 데 도움이 될 수 있습니다.

결론
이 자습서에서는 기계 학습의 사용 사례, 이 분야에서 사용되는 일반적인 방법 및 인기 있는 접근 방법, 적합한 기계 학습 프로그래밍 언어 및 알고리즘에서 재현되는 무의식적인 편견에 대해 염두에 두어야 할 몇 가지 사항을 검토했습니다.
기계 학습은 지속적으로 혁신되는 분야이므로 알고리즘, 방법 및 접근 방식이 계속 변화할 수 있다는 점을 기억하는 것이 중요합니다.
“scikit-learn로 Python에서 머신러닝 분류기를 구축하는 방법” 또는 “Python 3 및 PyTorch로 Neural Style Transfer를 수행하는 방법“에 대한 자습서를 읽는 것 외에도, 데이터 분석 자습서를 통해 기술 산업에서 데이터 작업에 대해 더 배울 수 있습니다.
Source:
https://www.digitalocean.com/community/tutorials/an-introduction-to-machine-learning