













소개
讀者们,這篇文章是我們正在進行的PyTorch系列的又一篇文章。這篇文章旨在為熟悉PyTorch基本概念的用戶提供一個中途上一个進度。雖然我們在早前的文章中已經 covered 了如何實現一個基本的分類器,但在這篇文章中,我們將討論如何使用PyTorch實現更複雜的深度學習功能。這篇文章的目標是让您了解.
- PyTorch 類如
nn.Module、nn.Functional、nn.Parameter之間的區別以及何時使用哪個 - 如何自定義您的訓練選項,例如為不同層次使用不同的學習速率、不同的學習率計劃
- 自定義權重初始化
所以,讓我們開始吧。
nn.Module 與 nn.Functional
這是一個在閱讀開源代碼時經常遇到的問題。在PyTorch中,層次通常作為 torch.nn.Module 對象之一或多個 torch.nn.Functional 函數實装。那麼應該使用哪個?哪個更好?
우리는 第2部分에서 torch.nn.Module에 대해 이해했습니다. nn.Module 오브젝트를 먼저 정의하고, 그 后再enna forward 메서드를 호출하여 실행하는 것이 PyTorch의 기반입니다. 이것은 객체 지향적인 방법으로 일어나는 것입니다.
반면, nn.functional는 입력에 прямо 호출할 수 있는 関数형태로 일부 レイ어 / 激活 를 제공합니다. 예를 들어, 이미지 텐서를 재스케일링하려면, 이미지 텐서에 torch.nn.functional.interpolate를 호출합니다.
그럼 우리는 무엇을 사용하는지 언제 결정하는지 어떻게 하는지요? 우리가 구현하는 レイ어 / 激活 / 손실이 손실이 있으면 어떻게 하는지요?
状態유지(Stateful-ness) 이해
일반적으로, 어느 레이어든지 함수로 표현할 수 있습니다. 例如, 卷積 操作은 mere 다수의 곱셈과 加法 操作입니다. 따라서, 우리는 그것을 mere 함수로 구현하는 것이 합리적입니다. 하지만 기다리세요, 레이어는 가중치를 持ち, trening 시 보관하고 갱신해야 합니다. 따라서 프로그래밍적으로 레이어는 mere 함수보다 더 많습니다. 또한 trening 我们的 네트워크를 할 때 변하는 데이터를 持ちまわす.
changes이 있다는 사실을 강조하고자 하는 것이다. 这意味着该层具有一个状态,随着训练的进行而改变。为了实现卷积操作的功能,我们还需要定义一个数据结构来存储该层的权重,这与函数本身是分开的。然后,将这个外部数据结构作为输入传递给我们的函数。
或者,为了省去麻烦,我们可以定义一个类来持有数据结构,并将卷积操作作为成员函数。这样真的可以减轻我们的工作量,因为我们可以不必担心函数外部存在有状态的变量。在这些情况下,我们会更愿意使用nn.Module对象,其中包含权重或其他可能会定义层行为的状态。例如,dropout / Batch Norm层的训练和推理行为是不同的。
另一方面,如果不需要状态或权重,可以使用nn.functional。例子包括调整大小(nn.functional.interpolate)、平均池化(nn.functional.AvgPool2d)。
尽管有上述理由,但大多数nn.Module类都有其nn.functional对应物。然而,在实际工作中,上述推理线是需要被尊重的。
nn.Parameter
nn.Parameter 클래스가 PyTorch의 중요한 클래스입니다. 이 클래스에 대한 자료가 PyTorch 인TRODUCTORY 문서에서 미若干部 보입니다. 다음과 같은 사례를 생각해봅시다.
각 nn.Module 객체는 parameters() 関数이 있습니다. 이 関数은 訓練 가능한 パラ미터를 돌려 줍니다. 이러한 パラ미터가 무엇인지 명확하게 정의해야 합니다. nn.Conv2d의 정의 过程中에서, PyTorch의 저자는 层的의 가중치와 편향값을 parameters로 정의했습니다. 그러나 주목하세요, net를 정의할 때, nn.Conv2d의 parameters를 net의 parameters에 추가할 필요가 없었습니다. nn.Conv2d 객체를 net 객체의 멤버로 설정하는 것 本身으로 묵시적으로 이뤄집니다.
이를 내부적으로 nn.Parameter 클래스를 사용하여 지원합니다. 이 클래스는 Tensor 클래스의 서브 클래스입니다. nn.Module 객체의 parameters() 関数을 호출할 때, 그 멤버로 nn.Parameter 객체를 돌려 줍니다.
nn.Module 클래스의 모든 훈련 가중치는 nn.Parameter 객체로 구현되어 있습니다. nn.Module (우리의 경우 nn.Conv2d)가 다른 nn.Module의 멤버로 지정되면, 지정한 대상 객체의 “parameters”(즉 nn.Conv2d의 가중치)이 지정 대상 객체의 “parameters”(net 객체의 パラ미터)에도 추가되며, 이를 “parameters”의 등록이라고 합니다.
tensor를 nn.Module 오브젝트로 할당하려고 하면, parameters() 안에 나타나지 않지만 nn.Parameter 오브젝트로 정의하면 나타난다. 이것은 RNNs의 경우에 이전 출력을 キャッシュ하기 위해 非微分性 tensor를 キャッシュ할 수 있는 scenarios에 便利하게 하기 위해서이다.
nn.ModuleList과 nn.ParameterList()
PyTorch를 사용하면서 YOLO v3을 구현하는 것을 기억하는데, 텍스트 파일을 구문 解析하여 구조를 얻었다. 모든 nn.Module 오브젝트를 Python 리스트에 저장하고 그 리스트를 네트워크를 표현하는 내 nn.Module 오브젝트의 멤버로 만들었다.
간단하게 표현하면, 이렇게 하면 좋다.
개별 모듈을 등록할 때와 달리 Python List를 할당하는 것은 List 내부의 모듈 매개변수를 등록하지 않습니다. 이를 해결하기 위해 nn.ModuleList 클래스로 목록을 래핑하고, 이를 네트워크 클래스의 멤버로 할당합니다.
마찬가지로, 텐서 목록은 nn.ParameterList 클래스로 목록을 래핑하여 등록할 수 있습니다.
가중치 초기화
가중치 초기화는 훈련 결과에 영향을 미칠 수 있습니다. 또한, 서로 다른 종류의 레이어에 대해 다른 가중치 초기화 방식을 필요로 할 수 있습니다. 이는 modules와 apply 함수를 사용하여 수행할 수 있습니다. modules는 nn.Module 클래스의 멤버 함수로, nn.Module 함수의 모든 멤버 nn.Module 객체를 포함하는 반복자를 반환합니다. 그런 다음, 각 nn.Module에 대해 apply 함수를 호출하여 초기화를 설정할 수 있습니다.
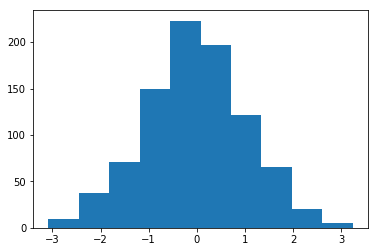
Mean = 1 및 Std = 1로 초기화된 가중치의 히스토그램
torch.nn.init 모듈에서 다양한 인플레이스 초기화 함수를 찾을 수 있습니다.
modules()와 children()의 차이
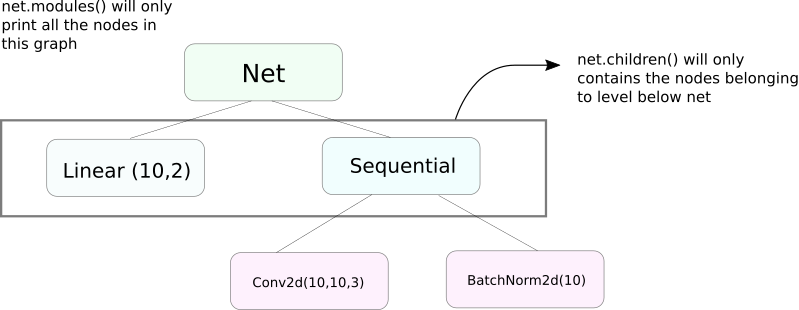
modules 함수와 유사한 children 함수가 있습니다. 두 者的 차이는 trivia적지만 중요합니다. 우리는 nn.Module 오브젝트가 다른 nn.Module 오브젝트를 자신의 데이터 멤버로 포함할 수 있다는 것을 알고 있습니다.
children() 함수는 children가 호출되고 있는 오브젝트의 데이터 멤버로 있는 nn.Module 오브젝트들의 목록을 돌려주는 것뿐입니다.
다른 한편 nn.Modules는 각 nn.Module 오브젝트를 재귀적으로 들어가면서, 이 경로를 따라 가는 각 nn.Module 오브젝트들의 목록을 생성합니다. nn.module 오브젝트가 없을 때까지입니다. 기억해야 하는 것은 modules() 함수는 그 자신을 목록의 일부로 돌려주는 것입니다.
이전 陳述는 nn.Module 类을 상속받은 모든 오브젝트 / 클래스에 대해 참되는 것입니다.
따라서, 가중치를 초기화할 때, modules() 함수를 사용할 수 있을 것입니다. 왜냐하면 nn.Sequential 오브젝트를 들어가고 그 멤버의 가중치를 초기화할 수 없기 때문입니다.
네트워크 정보 관련 정보 출력
네트워크 정보를 인쇄하는 것이 사용자 목적이나 디버깅 목적으로 필요할 수 있습니다. PyTorch은 named_* 함수를 사용하여 네트워크에 대한 많은 정보를 인쇄하는 매우 좋은 방법을 제공합니다. 네이밍이 되어 있는 4개의 함수가 있습니다.
named_parameters함수. convolutional layer가self.conv1과 같이 할당되면, 그 PARAMETER의 이름 (conv1.weight와 conv1.bias)를 얻는 이터레이터를 반환합니다. 이터레이터는nn.Parameter의__repr__함수에 의해 반환되는 값과 함께 전달됩니다.
2. named_modules 함수. 위와 같지만, 이터레이터가 모듈을 반환합니다. modules() 함수와 유사합니다.
3. named_children 함수. 위와 같지만, 이터레이터가 children() 함수의 리턴값과 유사하게 모듈을 반환합니다.
4. named_buffers 함수. 예를 들어 Batch Norm 层的 실시간 평균을 나타내는 버퍼 텐서를 반환합니다.
层的 다른 러닝 률
이 섹션에서는 다른 层层에 대해 다른 러닝 률을 사용하는 방법을 배울 것입니다. 일반적으로, 다른 层层에 대해 다른 러닝 률이나 기울기와 부差异에 대해 다른 러닝 률을 가지는 다양한 iperparameters를 어떻게 구성하는지를 배울 것입니다.
이러한 것을 구현하는 아이디어는 상당히 간단합니다. 지난 글에서 CIFAR 분류기를 구현할 때, 인덱스 오퍼레이터를 통해 네트워크의 모든 パラ미터를 하나의 오ปtimizerr 오브젝트로 전달했습니다.
그러나 torch.optim 클래스는 다른 leaning rate의 다른 세트의 パラ미터를 딕셔너리形式으로 제공할 수 있습니다.
이 예시에서 `fc1`의 パ라미터는 0.01의 leaning rate와 0.99의 모멘텀을 사용합니다. 하이퍼parameter를 지정하지 않은 그룹의 パ라미터(如火`fc2`)는 오피timizerr 함수에 제시된 인자로 들어가는 해당 하이퍼parameter의 기본값을 사용합니다. 다른 层次에 따라 パarameter 리스트를 생성하거나 パarameter가 weight이나 bias인지 여부에 따라 생성할 수 있습니다. 위에서 다룬 named_parameters() 함수를 사용하여 생성할 수 있습니다.
Learning Rate Scheduling
leaning rate를 스케쥴링하는 것은 调 tune하고자 하는 주요 hyperparameter입니다. PyTorch는 其torch.optim.lr_scheduler 모듈을 통해 learning rate를 스케쥴링하는 것을 지원합니다. 다양한 learning rate 스케쥴링을 제공합니다. 다음 예시는 그 중 하나로 나타냅니다.
그 위의 스케줄러는 우리의 경우에서는 milestones 리스트에 포함된 에poch를 도달할 때마다 gamma로 leaning rate를 곱ibe한다. 10n셋째 epoch과 20n셋째 epoch에는 leaning rate가 0.1로 곱ibe 될 것이다. 이를 위해서는 에poch에 대한 루프에서 scheduler.step 로 하나의 라인을 쓰여야 하며, 이를 통해 leaning rate가 갱신되는 것이다.
일반적으로, 트레이닝 루프는 두 개의 안에 들어가는 루프로 구성되며, 하나는 에poch을 돌면서, 또 다른 하나는 그 에poch의 배치를 돌면서 구성되는 것이다. epoch 루프의 시작에 scheduler.step를 호출하여 leaning rate가 갱신되도록 해야하며, 배치 루프에 쓰지 말아야 한다. 그렇지 않으면 10셋째 batch에서 대신 10n셋째 epoch에서 갱신될 수 있다.
또한 scheduler.step가 optim.step의 대신으로 사용되는 것이 아니라고 기억하자는 것이다. 이를 사용하고자 하는 경우 optim.step를 되돌아오기 전에 호출해야하며, (이것이 “batch” 루프에서 일어나는 것이다)
모델 저장
later use for inference, or just might want to create training checkpoints want to save your model. When it comes to saving models in PyTorch, you have two options.
첫 번째는 torch.save를 사용하는 것이다. 이것은 모델을 磁碟에 序列화 시키는 것과 同等의 일이며, nn.Module 객체를 Pickle을 사용하여 序列化시키는 것과 同等의 일을 한다. 이것은 모델을 磁碟에 저장하며, 이를 后来에 메모리에서 torch.load를 사용하여 로드할 수 있다.
위의 내용은 모델의 所有权重과 아키텍처를 저장하게 되며, 所有权重만 저장하고자 하면, 모델全体을 저장하는 것 대신 state_dict의 state_dict만을 저장할 수 있습니다. state_dict는 기본적으로 네트워크의 nn.Parameter 오브젝트와 그 값을 매핑하는 딕셔너리입니다.
위에서 보여준 것처럼, 기존의 state_dict를 nn.Module 오브젝트로 로드할 수 있습니다. 이러한 방법은 모델全体의 저장이 아닌 所有权重만을 저장합니다. 상태 딕셔너리를 로드하기 전에 层层을 갖추어야 합니다. 저장한 state_dict와 완전히 동일하지 않은 네트워크 아키텍처라면, PyTorch가 에러를 던집니다.
torch.optim에서 생성한 최적화 오브젝트도 state_dict 오브젝트를 갖추며, 최적화 알고리즘의 的超参数를 저장합니다. 이를 위의 방법과 유사하게 저장하고 로드할 수 있습니다.load_state_dict를 사용하여 최적화 오브젝트에 대한 상태 딕셔너리를 로드합니다.
결론
이것은 PyTorch의 더 나은 기능을 알아보는 것을 완료하며, 이 글에서 읽은 것들이 구상한 복잡한 deep learning 아이디어를 실현하는 데에 도움이 되길 바랍니다. 자신이 관심이 있으면 자세한 정보를 알아보기 위한 링크가 있습니다.
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced