













한밤중에 데이터 버그로 다시 깨어났을 때, 쿼리가 몇 초 안에 반환되고 데이터가 절대 손실되지 않으며 비용이 너무 낮아 상사가 웃고 있는 이상적인 데이터 세계를 꿈꿔본 적이 있나요? 꿈처럼 들리나요? 아니요! 이것은 현실이 되어가고 있습니다.
데이터 파티셔닝 문제로 압도당했던 그 밤을 기억하나요? 제품 관리자가 진전을 위해 애를 쓰고 있을 때, 당신은 분산된 데이터로 고군분투하고 있었습니다. 크로스 소스 쿼리는 산을 오르는 달팽이처럼 느리며, 스키마 변경은 일곱 개 부서 간의 조정이 필요했습니다.
하지만 이제 이 고통의 지점들이 새롭게 쓰여지고 있습니다.
Apache Doris와 Iceberg의 조합이 데이터 레이크의 작동 방식을 재정의하고 있습니다. 단순한 1+1=2가 아니라, 질적인 도약을 가져옵니다: 초 단위 쿼리, 매끄러운 스키마 진화, 그리고 진정한 데이터 일관성 보장을 제공합니다.
Doris와 Iceberg의 완벽한 심포니
데이터 엔지니어링 분야에서는 종종 이러한 문제에 직면하게 됩니다:
Xiao Zhang은 지난 3개월간의 사용자 행동 데이터를 분석해야 하는 데이터 분석 요구 사항을 작업 중입니다. 데이터는 Hive 데이터 웨어하우스, 비즈니스 데이터베이스 및 오브젝트 스토리지에 분산되어 있습니다. 크로스 소스 조인의 성능이 좋지 않아 쿼리가 40분 이상 걸리고 데이터 불일치가 자주 발생합니다.
게다가 Xiao Zhang은 데이터 거버넌스 작업도 처리해야 하며, 각 테이블 구조 변경은 그에게 두통을 안겨줍니다. 여러 하위 응용 프로그램이 이러한 테이블에 의존하고 있으며, 스키마 변경은 여러 팀 간의 조정을 필요로 하여 단일 변경을 완료하는 데 일주일이 걸릴 수 있습니다.
이러한 문제들은 데이터의 폭발적인 성장으로 더 두드러지게 되었습니다. 데이터 웨어하우스와 데이터 레이크의 전통적인 분리는 더 이상 요구 사항을 충족시킬 수 없게 되었습니다.
다행히도 2.1 버전에서 Apache Doris의 레이크하우스 아키텍처가 크게 향상되었습니다. 이는 주류 데이터 레이크 포맷(Hudi, Iceberg, Paimon 등)의 읽기 및 쓰기 기능을 향상시킬 뿐만 아니라 다중 SQL 방언 호환성을 도입하여 기존 시스템에서 Apache Doris로의 원활한 전환을 가능케 합니다. 데이터 과학 및 대규모 데이터 읽기 시나리오에서 Doris는 Arrow Flight 고속 읽기 인터페이스를 통합하여 데이터 전송 효율을 100배 향상시킵니다.
따라서 소장이는 자신의 보상을 위해 Doris + Iceberg를 사용하기로 결정했습니다.
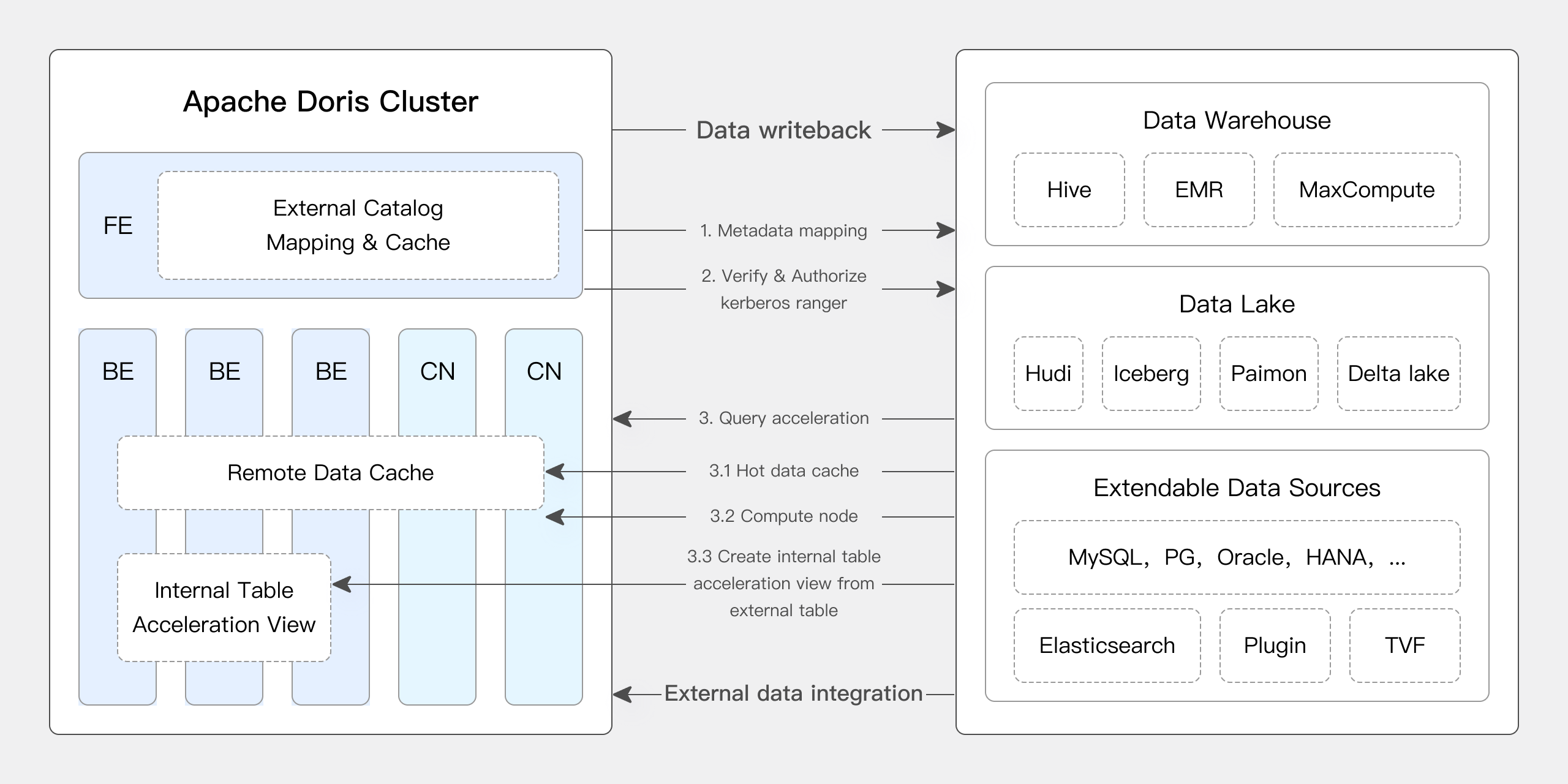
Apache Doris는 Iceberg의 여러 핵심 기능을 네이티브로 지원합니다:
- Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore, DLF 등과 같은 다양한 Iceberg 카탈로그 유형을 지원합니다.
- 네이티브로 Iceberg V1/V2 테이블 형식을 지원하며 Position Delete 및 Equality Delete 파일을 읽을 수 있습니다.
- 테이블 함수를 통해 Iceberg 테이블 스냅샷 이력을 쿼리할 수 있습니다.
- 타임 트래블 기능을 지원합니다.
- Iceberg 테이블 엔진을 네이티브로 지원합니다. Apache Doris는 Iceberg 테이블을 직접 생성, 관리 및 데이터 작성을 할 수 있습니다. 완전한 파티션 변환 함수 세트를 지원하며, 숨겨진 파티션 및 파티션 레이아웃 진화를 비롯한 기능을 제공합니다.
또한, Doris의 2.1.6 버전은 Doris + Iceberg에 대한 중요한 업그레이드를 가져왔습니다:
Apache Doris는 Iceberg에 대한 DDL 및 DML 작업을 지원합니다. 사용자는 Apache Doris를 통해 Iceberg에서 직접 데이터베이스와 테이블을 생성하고 Iceberg 테이블에 데이터를 작성할 수 있습니다.
이 기능을 통해 사용자는 Apache Doris를 사용하여 Iceberg에서 완전한 데이터 쿼리 및 쓰기 작업을 수행할 수 있으며, 이는 레이크하우스 아키텍처를 더욱 간소화합니다.
따라서, 샤오 장은 Apache Doris + Apache Iceberg를 기반으로 효율적인 레이크하우스 솔루션을 신속하게 구축하여 실시간 데이터 분석 및 처리에 대한 다양한 요구를 유연하게 충족할 수 있습니다:
- Doris의 고성능 쿼리 엔진을 사용하여 Iceberg 테이블 및 기타 데이터 소스의 데이터를 조인하고 분석하여 통합된 연합 데이터 분석 플랫폼을 구축합니다.
- Doris에서 Iceberg 테이블을 직접 관리하고 구축하며, 데이터를 정리 및 처리하고 Iceberg 테이블에 작성하여 통합된 레이크하우스 데이터 처리 플랫폼을 구축합니다.
- Iceberg 테이블 엔진을 통해 Doris 데이터를 다른 상류 및 하류 시스템과 공유하여 추가 처리를 위해 통합된 오픈 데이터 저장 플랫폼을 구축합니다.
이제 단순한 표면 통합이 아니라 레이크하우스 아키텍처의 깊은 융합입니다!
도리스와 아이스버그의 실용적 요약
탐험과 실습에서의 여러 번의 변화 끝에, 소 장은 도리스 + 아이스버그와 관련된 몇 가지 실용적인 경험을 요약했습니다:
지능형 메타데이터 관리
전통적인 솔루션에서 메타데이터 관리는 항상 어려운 문제였습니다. 테이블 파티션 정보, 파일 위치 및 스키마 변경 이력이 곳곳에 흩어져 있어 쿼리 성능이 저하되고 복잡한 운영 및 유지보수가 필요했습니다.
도리스 + 아이스버그는 통합된 메타데이터 관리 레이어를 제공합니다:
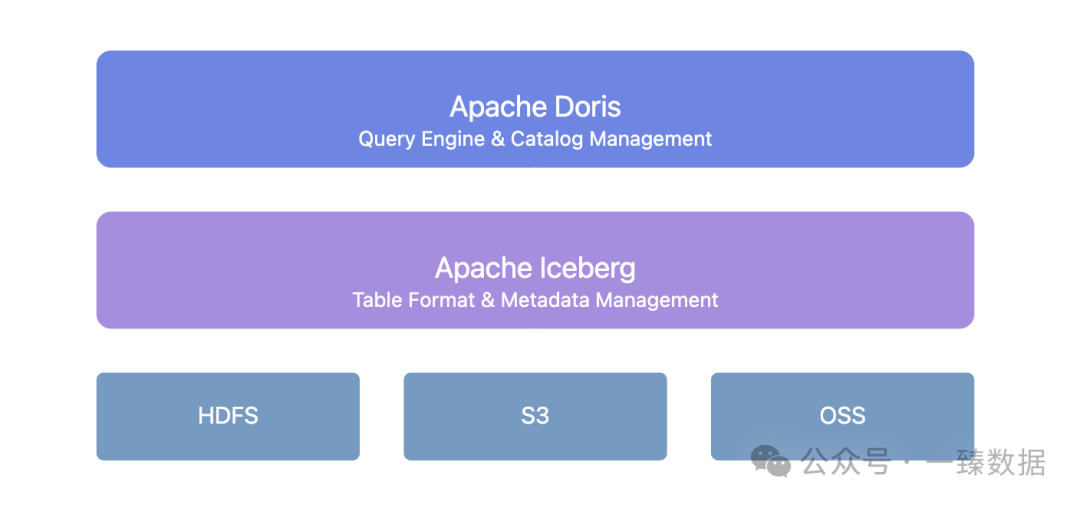
이 아키텍처는 몇 가지 핵심 가치를 제공합니다:
- 심플한 스키마 진화: 테이블 구조 변경에 더 이상 다운타임이 필요하지 않습니다. 도리스 + 아이스버그는 필드 추가, 삭제, 수정 및 파티셔닝 방법 조정을 지원합니다.
- 데이터 버전 관리: 아이스버그의 스냅샷 메커니즘을 통해 언제든지 데이터 상태로 되돌아갈 수 있습니다.
- 통합 카탈로그 서비스: 하이브 메타스토어, 하둡, REST, 글루, 구글 Dataproc 메타스토어 및 DLF와 같은 다양한 아이스버그 카탈로그 유형을 지원하여 기존 인프라와 신속하게 통합합니다.
이제 소 장은 단일 ALTER TABLE 문으로 스키마 변경을 완료할 수 있습니다. 시스템은 호환성을 자동으로 처리하며 하류 응용 프로그램은 변경 사항을 알 수 없습니다.
효율적인 데이터 조직
도리스는 MPP 엔진을 Iceberg의 데이터 조직 방법과 혁신적으로 결합합니다.
-- Create a partitioned Iceberg table
-- Partition columns must be in the table's column definition list
CREATE TABLE sales (
ts DATETIME,
user_id BIGINT,
amount DOUBLE,
pt1 STRING,
pt2 STRING
) ENGINE=iceberg
-- Iceberg's partition type corresponds to List partitioning in Doris
PARTITION BY LIST (DAY(ts), pt1, pt2) ()
PROPERTIES (
-- Compression format
-- Parquet: snappy, zstd (default), plain (no compression)
-- ORC: snappy, zlib (default), zstd, plain (no compression)
'write-format'='orc',
'compression-codec'='zlib'
);
이 SQL 문은 강력한 기술적 메커니즘을 숨깁니다.
- 파일 조직: HDFS와 객체 저장소와 같은 일반 저장 매체를 지원합니다.
- 스마트 파티셔닝: 파티션 변환 함수를 지원하여 Iceberg의 암시적 파티셔닝 및 파티션 진화 기능을 활성화합니다.
- 저장 최적화: Parquet 및 ORC와 같은 열 지향 저장 형식을 지원하며 다양한 압축 방법을 결합하여 성능을 향상시킵니다.
도리스가 Iceberg에서 DDL 및 DML 작업을 지원함으로써 데이터 일관성 문제도 완전히 해결됩니다.
운영 및 유지보수 관리
데이터 플랫폼의 안정성을 보장하기 위해 소 장자는 Iceberg 테이블을 모니터링하고 관리하기 위해 다음 방법을 사용합니다.
-- View table snapshot information
SELECT * FROM iceberg_meta(
"table" = "iceberg.nyc.taxis",
"query_type" = "snapshots"
);
-- Query a specific snapshot using FOR VERSION AS OF
SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF {snapshot_id};
-- Query a specific snapshot using FOR TIME AS OF
SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF {committed_at};
-- Manage snapshots
...
이 도구 체인은 다음을 제공합니다.
- 메트릭 모니터링: 테이블 상태 및 스냅샷 메트릭을 실시간으로 제어합니다.
- 스냅샷 관리: 만료된 스냅샷을 정리하여 저장 공간을 확보합니다.
- 장애 복구: 모든 이력 버전으로 롤백 지원 (스냅샷 ID 또는 스냅샷 생성 시간을 기반으로 한 이력 버전 데이터 읽기).
이러한 실천을 통해 소 장자의 도리스 + Iceberg 기반 데이터 플랫폼은 새로운 높이에 도달했습니다.
- 쿼리 성능이 300% 향상되었습니다.
- 저장 비용이 40% 절감되었습니다.
- 운영 및 유지보수 효율이 200% 증가했습니다.
도리스의 호수집에서의 흥미로운 여정은 끝이 없다.
다음 호에는 더 흥미로운, 유용한, 가치 있는 콘텐츠가 기대된다!